여러가지 오픈소스 모델들을 알아보고있었습니다.
2024.05.29 - [데이터&AI/LLM] - 내 서버에서 llama3 실행하기!! (feat. ollama)
내 서버에서 llama3 실행하기!! (feat. ollama)
이전 포스팅에서 ollama를 활용하여 llama2-uncencored 모댈을 활용해보았고,airllm을 활용하여 llama3 모델을 활용해보았는데요!! 이번에는 ollama를 활용하여 llama3를 사용해보겠습니다!! 1. ollama 실행!! -
drfirst.tistory.com
2024.06.21 - [데이터&AI/LLM] - llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom)
llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom)
airllm으로 llama3를 썻다가 메모리 부족 문제로 실행하지 못하는 문제를 겪었었습니다!!2024.05.07 - [데이터&AI/LLM] - 내 서버에서 llama3 70B 모델 사용하기 (feat. airllm) 내 서버에서 llama3 70B 모델 사용하
drfirst.tistory.com
오픈소스로 llm 모델을 체험한다는 즐거움이있었지만!!
한국어로서 운영하는데 아쉬움이 았습니다
이번에는 한국어 능력도 우수한!!, 알리바바에서 나온 qwen2 모델을 소개해보고자합니다~~

Qwen2 소개
알리바바의 Qwen 팀에서 새롭게 선보인, ( 2024년06월06일!!!!) llm언어 모델 시리즈,
Alibaba Cloud’s Qwen2 with Enhanced Capabilities Tops LLM Leaderboard
The latest language model series from Alibaba Cloud topped rankings for open-sourced LLMs thanks to enhanced performance and safety alignment.
www.alibabacloud.com
Qwen2는 이전에 출시되었던 Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio 등
Qwen 시리즈의 뒤를 잇는 최신 모델입니다~~
모델 주요 특징:
- 다양한 모델 크기: Qwen2는 다양한 크기의 디코더 언어 모델로 구성, 각 크기별로 기본 언어 모델 및 채팅 모델 제공
- 향상된 아키텍처: Transformer 아키텍처를 기반으로 SwiGLU 활성화 함수, 어텐션 QKV 바이어스, 그룹 쿼리 어텐션, 슬라이딩 윈도우 어텐션 및 전체 어텐션의 혼합 등 다양한 기술을 적용하여 향상된 성능!!
- 강력한 토크나이저: 여러 자연어와 코드에 적응 가능한 향상된 토크나이저를 통해 더욱 정확하고 효율적인 언어 처리를 지원 >> 한국어 능력도 믿음직합니디1!^^
qwen2에서 제공한 공식 평가정보인데요~~
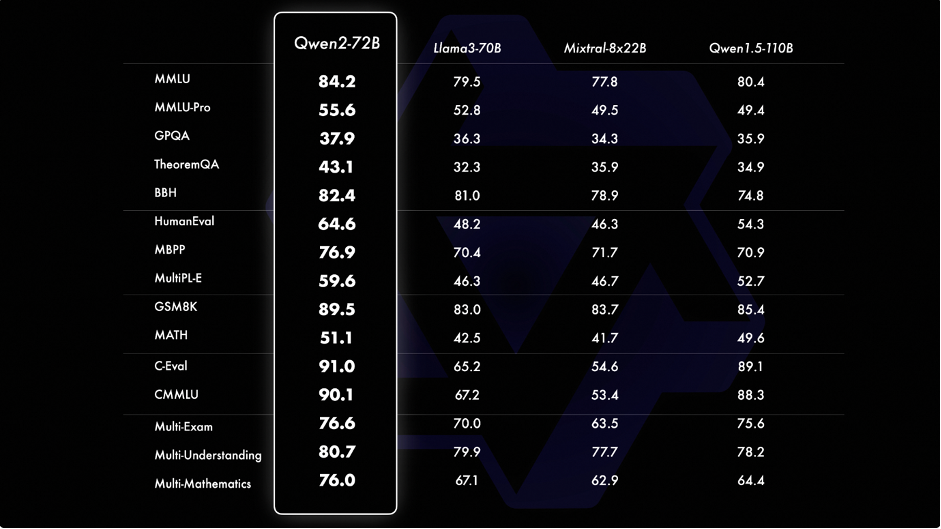
llama3-70B 모델을 능가한다고하네요~?
llama3-70B 모델을 능가한다고하네요~?
Qwen2 모델 종류는!?
이번 모델은 72B / 57B / 7B /1.5B / 0.5B 6 가지로 구분이 되는데요!
그 6가지로 그냥 모델 instruct, gguf 형식 양자화등으로 나눠졌으묘
세부 사항은 아래와 같습니다~~
| 모델 이름 | 모델 크기 (B) | 특징 |
| Qwen/Qwen2-72B-Instruct | 72 | 가장 큰 모델, 명령어 기반 텍스트 생성에 특화 |
| Qwen/Qwen2-72B | 72 | 가장 큰 모델, 일반적인 텍스트 생성 |
| Qwen/Qwen2-7B-Instruct | 7 | 명령어 기반 텍스트 생성에 특화 |
| Qwen/Qwen2-7B | 7 | 일반적인 텍스트 생성 |
| Qwen/Qwen2-57B-A14B-Instruct | 57 | 명령어 기반 텍스트 생성에 특화, 14B 파라미터의 추가 학습 데이터 사용 |
| Qwen/Qwen2-57B-A14B | 57 | 14B 파라미터의 추가 학습 데이터 사용 |
| Qwen/Qwen2-1.5B-Instruct | 1.5 | 명령어 기반 텍스트 생성에 특화 |
| Qwen/Qwen2-1.5B | 1.5 | 일반적인 텍스트 생성 |
| Qwen/Qwen2-0.5B-Instruct | 0.5 | 명령어 기반 텍스트 생성에 특화 |
| Qwen/Qwen2-0.5B | 0.5 | 일반적인 텍스트 생성 |
| Qwen/Qwen2-72B-Instruct-AWQ | 72 | 명령어 기반 텍스트 생성에 특화, AWQ(Answering What questions) 데이터셋으로 추가 학습 |
| Qwen/Qwen2-72B-Instruct-GPTQ-Int8 | 72 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int8 정밀도로 변환 |
| Qwen/Qwen2-72B-Instruct-GPTQ-Int4 | 72 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int4 정밀도로 변환 |
| Qwen/Qwen2-7B-Instruct-AWQ | 7 | 명령어 기반 텍스트 생성에 특화, AWQ 데이터셋으로 추가 학습 |
| Qwen/Qwen2-7B-Instruct-GPTQ-Int8 | 7 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int8 정밀도로 변환 |
| Qwen/Qwen2-7B-Instruct-GPTQ-Int4 | 7 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int4 정밀도로 변환 |
| Qwen/Qwen2-57B-A14B-Instruct-GPTQ-Int4 | 57 | 명령어 기반 텍스트 생성에 특화, 14B 파라미터의 추가 학습 데이터 사용, GPTQ 양자화 기술을 사용하여 Int4 정밀도로 변환 |
| Qwen/Qwen2-1.5B-Instruct-AWQ | 1.5 | 명령어 기반 텍스트 생성에 특화, AWQ 데이터셋으로 추가 학습 |
| Qwen/Qwen2-1.5B-Instruct-GPTQ-Int8 | 1.5 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int8 정밀도로 변환 |
| Qwen/Qwen2-1.5B-Instruct-GPTQ-Int4 | 1.5 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int4 정밀도로 변환 |
| Qwen/Qwen2-0.5B-Instruct-AWQ | 0.5 | 명령어 기반 텍스트 생성에 특화, AWQ 데이터셋으로 추가 학습 |
| Qwen/Qwen2-0.5B-Instruct-GPTQ-Int8 | 0.5 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int8 정밀도로 변환 |
| Qwen/Qwen2-0.5B-Instruct-GPTQ-Int4 | 0.5 | 명령어 기반 텍스트 생성에 특화, GPTQ 양자화 기술을 사용하여 Int4 정밀도로 변환 |
| Qwen/Qwen2-0.5B-Instruct-MLX | 0.5 | 명령어 기반 텍스트 생성에 특화, MLX(Multilingual eXtended) 데이터셋으로 추가 학습 |
| Qwen/Qwen2-7B-Instruct-MLX | 7 | 명령어 기반 텍스트 생성에 특화, MLX 데이터셋으로 추가 학습 |
| Qwen/Qwen2-7B-Instruct-GGUF | 7 | 명령어 기반 텍스트 생성에 특화, GGUF 포맷으로 변환 |
| Qwen/Qwen2-0.5B-Instruct-GGUF | 0.5 | 명령어 기반 텍스트 생성에 특화, GGUF 포맷으로 변환 |
| Qwen/Qwen2-1.5B-Instruct-MLX | 1.5 | 명령어 기반 텍스트 생성에 특화, MLX 데이터셋으로 추가 학습 |
Qwen2 웹사이트에서 활용해보기
https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
Qwen2 72B Instruct - a Hugging Face Space by Qwen
huggingface.co
huggingface에서 제공된, qwen2 모델을 테스트 할 수 있는 사이트 입니다.
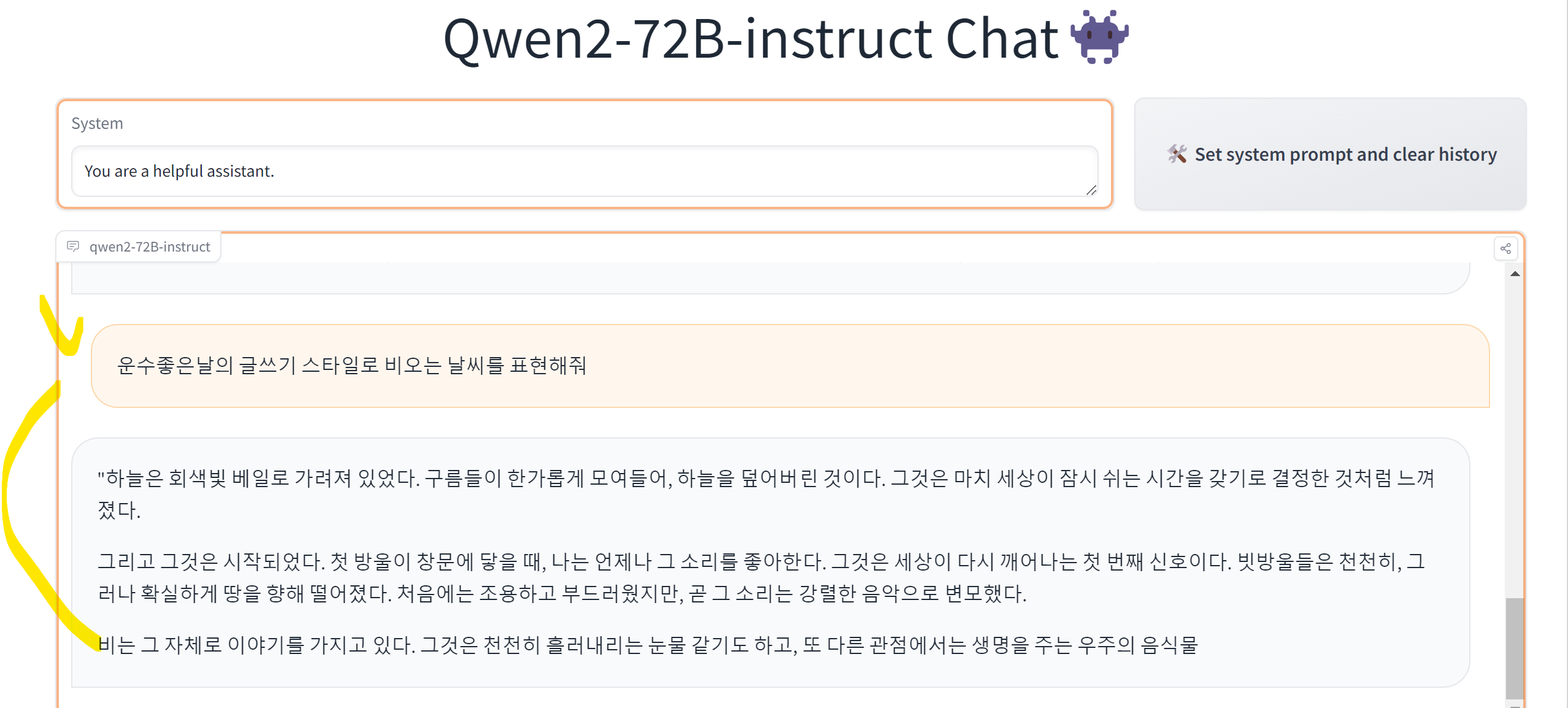
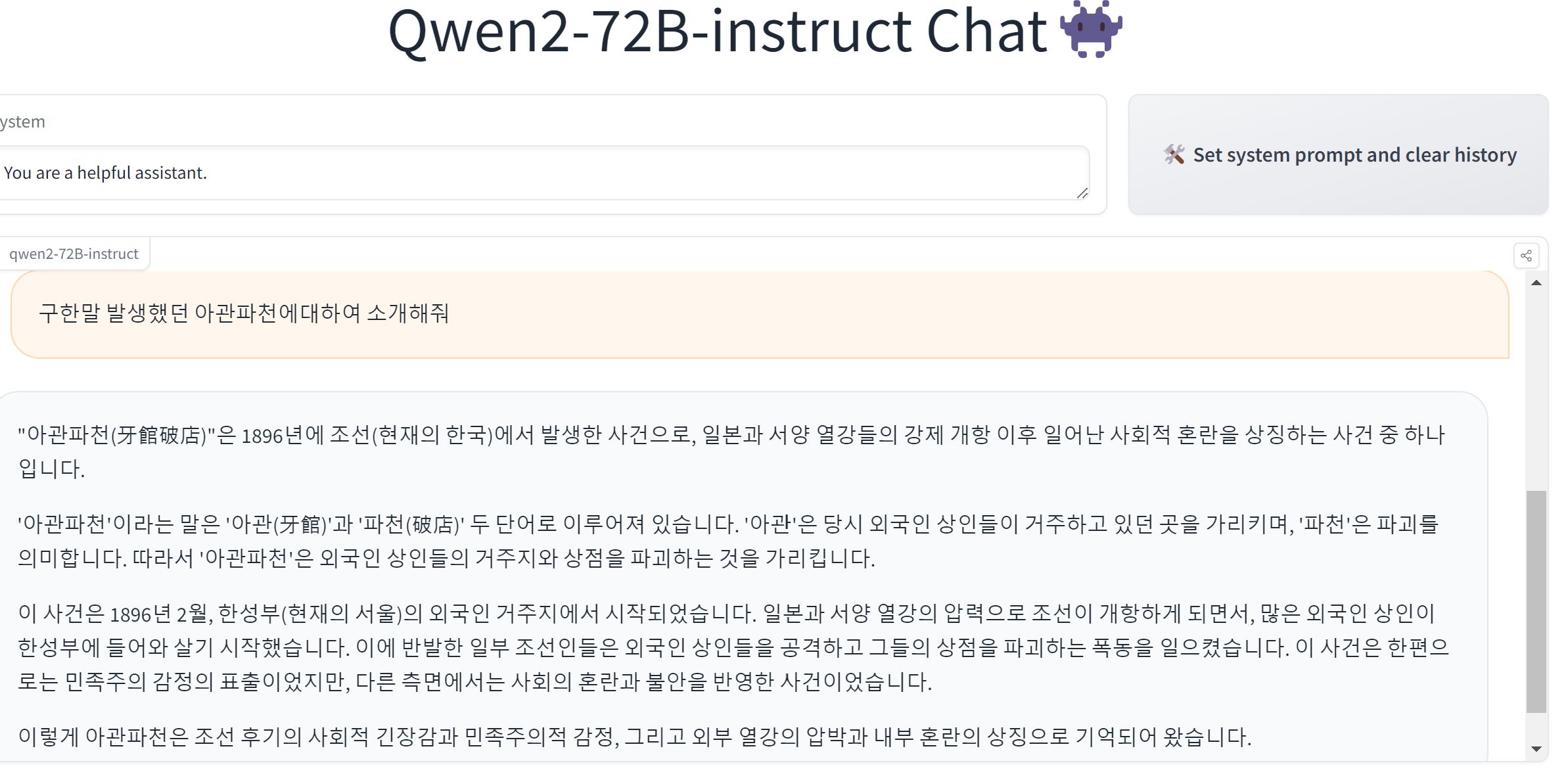
우리의 역사인 "아관파천" 에 대하서는 다른말을하네요~~~
Qwen2 코드로 활용해보기!
가장 경량화된 모델인 1.5B 모델을 활용해보겠습니다~~
아래의 간단한 코드로 로딩 끝~~
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-1.5B-Instruct-GPTQ-Int8",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-1.5B-Instruct-GPTQ-Int8")
이제는 생성을 진행해보아요!!
prompt = "고려 공민왕의 업적에 대하여 소개해줘"
messages = [
{"role": "system", "content": "You are a helpful assistant.한국어로 답변해!!"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1028
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
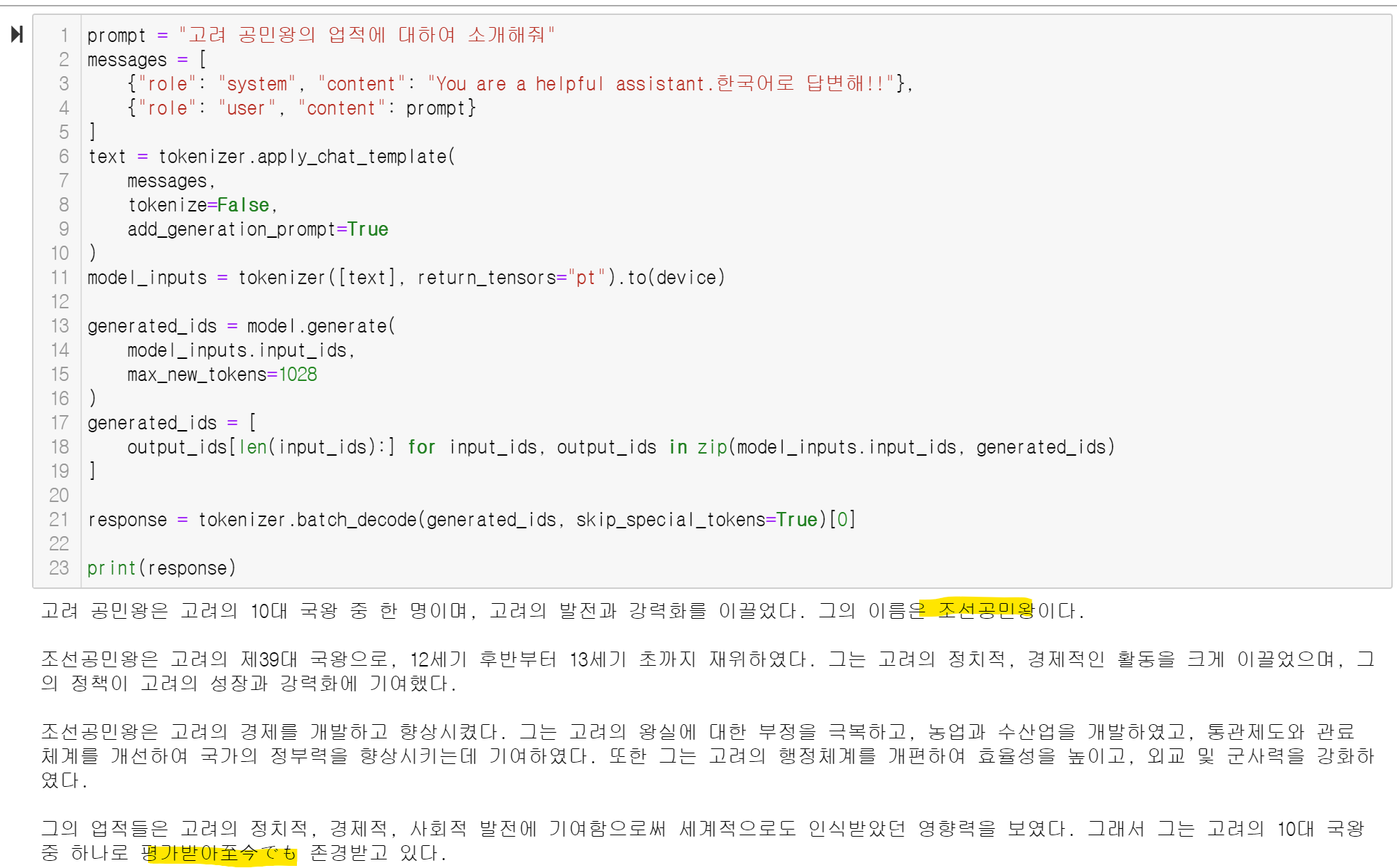
한국의 역사를 한국어로 물었는데~~ 여러 아쉬운 점이 있긴 합니다!!
ㅁ 참고 : https://huggingface.co/Qwen/Qwen2-1.5B-Instruct
Qwen/Qwen2-1.5B-Instruct · Hugging Face
Qwen2-1.5B-Instruct Introduction Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts m
huggingface.co
'데이터&AI > LLM' 카테고리의 다른 글
| 오픈 소스 LLM 서빙 소프트웨어 비교해보기!! (vLLM, Ollama, OpenLLM, LocalAI, llamafiles, GPT4All) (1) | 2024.06.25 |
|---|---|
| qwen2 모델 톺아보기 (feat. llama3 모델과의 비교!) (0) | 2024.06.24 |
| Hugging Face Transformers: Pipeline vs. AutoModel, 뭘 사용할까!?? (0) | 2024.06.22 |
| llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom) (0) | 2024.06.21 |
| Solar 오픈소스 모델 활용해서 ON-premise LLM 만들기 (0) | 2024.06.13 |




댓글