안녕하세요!!
제 포스팅에서는 그동안 오픈소스 llm을 크게 2가지 방법으로 시도해보았었습니다~~
1. 직접 huggingface에서 모델 다운받아 실행하기
2024.06.21 - [데이터&AI/LLM] - llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom)
llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom)
airllm으로 llama3를 썻다가 메모리 부족 문제로 실행하지 못하는 문제를 겪었었습니다!!2024.05.07 - [데이터&AI/LLM] - 내 서버에서 llama3 70B 모델 사용하기 (feat. airllm) 내 서버에서 llama3 70B 모델 사용하
drfirst.tistory.com
2. llm 서빙모델 (ollama, llamafiles) 등을 활용 하여 테스트하기
2024.05.29 - [데이터&AI/LLM] - 내 서버에서 llama3 실행하기!! (feat. ollama)
내 서버에서 llama3 실행하기!! (feat. ollama)
이전 포스팅에서 ollama를 활용하여 llama2-uncencored 모댈을 활용해보았고,airllm을 활용하여 llama3 모델을 활용해보았는데요!! 이번에는 ollama를 활용하여 llama3를 사용해보겠습니다!! 1. ollama 실행!! -
drfirst.tistory.com
오늘은 이 두번쨰 방법인 llm 서빙하는 몇가지 소프트웨어를 소개하고자합니다~~

오픈 소스 LLM 서빙 소프트웨어 비교
(vLLM, Ollama, OpenLLM, LocalAI, llama.cpp, GPT4All)
| vLLM | Ollama | OpenLLM | LocalAI | llamafiles | GPT4ALL | |
 |
 |
 |
 |
 |
 |
|
| 장점 | 높은 처리량, 짧은 지연 시간, Paged Attention, AWQ 지원, Python 통합 용이 | 쉬운 설치 및 사용, 양자화 모델 지원, 다양한 운영체제 지원 | 다양한 모델 지원, 사용자 친화적인 웹 인터페이스, 모델 성능 모니터링, Kubernetes 확장성 | 다양한 모델 지원, 쉬운 웹 인터페이스, API 제공, Docker 기반 배포 | 가볍고 빠름, CPU/GPU 환경 지원, 다양한 운영체제 지원 | 쉬운 설치 및 사용, GUI 제공, 다양한 모델 지원, 오프라인 사용 가능 |
| 단점 | GPU 필수, AWQ 최적화 부족 | 분산 처리 및 배칭 기능 부재, AWQ 미지원 | 모델 배포 및 관리에 대한 전문 지식 필요, Kubernetes 환경 구축 부담 | 모델 성능 최적화 기능 부족, 고급 사용자를 위한 기능 제한적 | 모델 성능 제한적, 커뮤니티 지원 부족 | 모델 성능 제한적, 기능 제한적 |
| 주요 기능 | 분산 처리, 배칭, Paged Attention, AWQ 지원 | 양자화 모델 지원, 쉬운 설치 및 사용, 다양한 운영체제 지원 | 다양한 모델 지원, 웹 인터페이스, 모델 성능 모니터링, Kubernetes 확장성 | 다양한 모델 지원, 웹 인터페이스, API 제공, Docker 기반 배포 | 경량화 및 가속화된 추론, 다양한 모델 포맷 지원 | 다양한 모델 지원, GUI, 오프라인 사용 가능 |
| 대상 사용자 | 높은 성능과 처리량이 필요한 개발자 및 기업 | 쉬운 설치 및 사용을 원하는 개인 사용자 및 개발자 | 다양한 모델을 실험하고 배포하려는 개발자 및 연구자 | 쉬운 인터페이스로 LLM을 사용하고자 하는 개인 사용자 및 개발자 | 제한된 리소스 환경에서 LLM을 실행하려는 사용자 | 기술적 배경지식이 부족한 사용자, 오프라인 환경에서 LLM을 사용하려는 사용자 |
선택 가이드:
- vLLM: 높은 처리량과 빠른 응답 속도가 필요한 환경에서 적합하며, 특히 AWQ 모델을 사용하려는 경우 유용합니다. GPU가 필수입니다.
- Ollama: 쉬운 설치 및 사용, 양자화 모델 지원 등의 장점이 있으며, GPU가 없는 환경에서도 사용할 수 있습니다.
- OpenLLM: 다양한 모델을 실험하고 배포하려는 개발자 및 연구자에게 적합합니다. Kubernetes 환경 구축 및 운영에 대한 전문 지식이 필요합니다.
- LocalAI: 쉬운 인터페이스로 LLM을 사용하고자 하는 개인 사용자 및 개발자에게 적합합니다. Docker를 사용하여 쉽게 배포 및 관리할 수 있습니다.
- llamafiles : 제한된 리소스 환경에서 LLM을 실행하려는 사용자에게 적합합니다. 가볍고 빠르며, CPU/GPU 환경 모두 지원합니다.
- GPT4All: 기술적 배경지식이 부족한 사용자나 오프라인 환경에서 LLM을 사용하려는 사용자에게 적합합니다. 쉬운 설치 및 사용, GUI 제공, 다양한 모델 지원, 오프라인 사용 가능 등의 장점이 있습니다.
개인적 의견:
- GPU없이 빠르게 테스트해보고싶을떄!! + 상남자 : llamafiles
- GPU없이 빠르게 테스트해보고싶을떄!! + 깐깐한 서울남자 : Ollama
- GPU와함께 , 쉽게 해보고싶을떄 : vLLM
- 모델의 성능 고도화보다는 안정적 환경등을 고려하고싶을떄! : ,OpenLLM
- 본격적으로 파인튜닝하면서 하고싶을떄는? 서빙말고 직접 huggingface에서 모델 받아서 하기!
새부적으로 알아보기!!!
1. VLLM (https://docs.vllm.ai/en/stable/)
개요
VLLM은 대규모 언어 모델을 서빙하기 위한 고성능, 확장 가능한 시스템입니다. VLLM은 모델의 추론 속도와 메모리 사용을 최적화하여 실시간 애플리케이션에서 효율적으로 동작할 수 있도록 설계되었습니다.
주요 특징
- 고성능 서빙: 낮은 지연 시간과 높은 처리량을 제공하는 고성능 추론 엔진.
- 확장성: 분산 환경에서 확장 가능, 여러 노드에 걸쳐 모델 배포.
- 유연한 배포: 클라우드 및 온프레미스 환경에서 쉽게 배포 가능.
- 사용자 친화적 인터페이스: 직관적인 API와 관리 도구 제공.
사용 사례
- 실시간 챗봇 및 대화형 AI 시스템
- 대규모 언어 모델 기반 애플리케이션
- 실시간 데이터 분석 및 처리
2. Ollama (https://ollama.com/)
개요
Ollama는 대규모 언어 모델의 서빙을 위한 오픈소스 플랫폼으로, 쉽게 배포하고 운영할 수 있는 기능을 제공합니다. Ollama는 다양한 언어 모델을 지원하며, 효율적인 자원 관리와 확장성을 중점으로 설계되었습니다.
주요 특징
- 다양한 모델 지원: 여러 대규모 언어 모델을 지원.
- 효율적인 자원 관리: 메모리와 계산 자원을 효율적으로 관리.
- 확장성: 클러스터 환경에서 확장 가능, 자동 확장 기능 제공.
- 모니터링 및 관리 도구: 실시간 모니터링과 관리 도구 제공.
사용 사례
- 대규모 언어 모델을 활용한 자연어 처리 애플리케이션
- 실시간 사용자 응대 시스템
- 데이터 분석 및 처리 워크플로우 자동화
3. OpenLLM (https://github.com/bentoml/OpenLLM)
개요
OpenLLM은 대규모 언어 모델을 위한 오픈소스 서빙 프레임워크로, 유연성과 확장성을 강조합니다. 다양한 환경에서 쉽게 배포하고 확장할 수 있습니다.
주요 특징
- 유연성: 다양한 언어 모델과 호환 가능.
- 확장성: 분산 시스템에서 확장 가능.
- 쉬운 배포: 다양한 배포 옵션 제공, 클라우드 및 온프레미스 모두 지원.
- 모니터링 및 관리: 강력한 모니터링 및 관리 도구 제공.
사용 사례
- 자연어 처리 애플리케이션
- 실시간 번역 및 요약 시스템
- 대규모 데이터 분석
4. LocalAI (https://localai.io/)
개요
LocalAI는 로컬 환경에서 대규모 언어 모델을 서빙하기 위한 오픈소스 프레임워크로, 로컬 컴퓨팅 자원을 최대한 활용하도록 설계되었습니다.
주요 특징
- 로컬 최적화: 로컬 환경에서 최적화된 성능 제공.
- 경량화: 경량화된 모델 서빙, 낮은 자원 사용.
- 쉬운 설치: 간편한 설치 및 설정, 로컬 컴퓨팅 자원 활용.
사용 사례
- 로컬 데이터 처리 및 분석
- 오프라인 환경에서의 언어 모델 활용
- 개인정보 보호가 중요한 애플리케이션
5. LlamaFile (https://github.com/Mozilla-Ocho/llamafile)
개요
LlamaFile은 대규모 언어 모델을 파일 기반으로 서빙하는 오픈소스 소프트웨어로, 파일 입출력을 통해 모델을 관리하고 서빙합니다.
주요 특징
- 파일 기반 관리: 모델의 파일 입출력을 통해 간편하게 관리.
- 확장성: 파일 시스템을 활용한 확장성 제공.
- 유연한 통합: 다양한 파일 형식과 호환 가능, 쉽게 통합 가능.
사용 사례
- 파일 기반 데이터 처리
- 데이터 파이프라인의 일부로 통합
- 간편한 모델 배포 및 관리
+ 더 많은 서비스들을 알아보고싶다면!?!
- langchain에서는 다양한 서비스들을 통합해서 제공하고있습니다
langchain 공식사이트에서 어떤 서비스들이 있는지 쉽게 확인해볼수 있어요~~
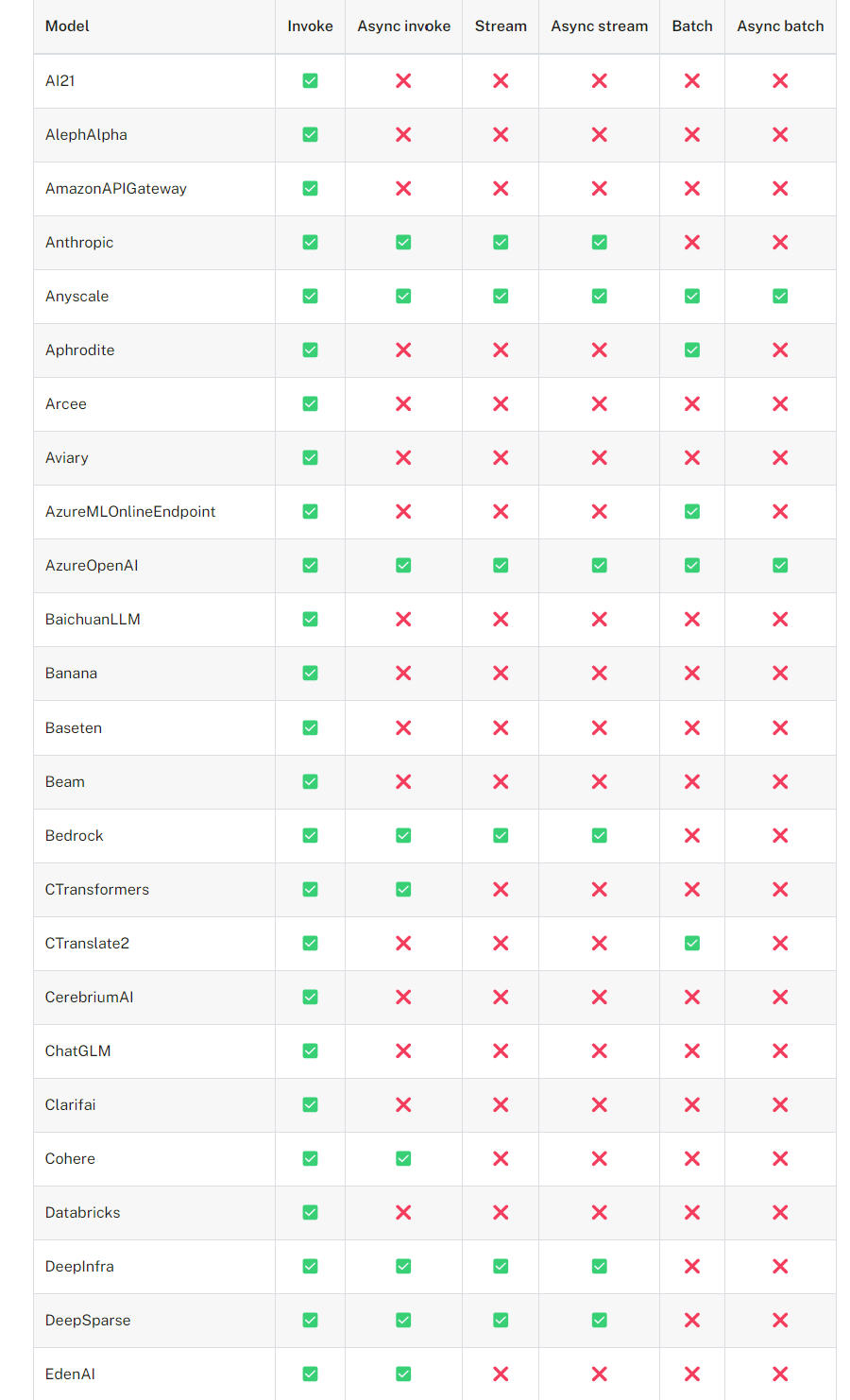
https://python.langchain.com/v0.2/docs/integrations/llms/
LLMs | 🦜️🔗 LangChain
Features (natively supported)
python.langchain.com
감사합니다.
'데이터&AI > LLM' 카테고리의 다른 글
| llm 모델에서 GGUF가 무엇인지 알아보자!! (feat. bllossom 모델을 gguf로 바꿔보기!) (0) | 2024.06.29 |
|---|---|
| RMSNorm과 Layer Normalization 비교하기 (0) | 2024.06.28 |
| qwen2 모델 톺아보기 (feat. llama3 모델과의 비교!) (0) | 2024.06.24 |
| 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력) (0) | 2024.06.23 |
| Hugging Face Transformers: Pipeline vs. AutoModel, 뭘 사용할까!?? (0) | 2024.06.22 |




댓글