2024.06.23 - [데이터&AI/LLM] - 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력)
알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력)
여러가지 오픈소스 모델들을 알아보고있었습니다.2024.05.29 - [데이터&AI/LLM] - 내 서버에서 llama3 실행하기!! (feat. ollama) 내 서버에서 llama3 실행하기!! (feat. ollama)이전 포스팅에서 ollama를 활용하여 l
drfirst.tistory.com
오늘은 지난번 사용해 보았던 qwen2 모델을 llama3모델과 비교하여 분석해보겠습니다~~
1. Qwen2 모델 구조 확인하기
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-1.5B-Instruct-GPTQ-Int8",
torch_dtype="auto",
device_map="auto"
)
model.eval()위와 같은 코드로 간단히 모델구조 확인이 가능합니다!

2. Qwen2 모델 구조 해석
qwen2는 Aliyun(알리바바 클라우드) 에서 개발한 모델로 주요 구성 요소는 다음과 같습니다
1. Qwen2Model:
- embed_tokens (Embedding): 151,936개의 토큰, 1536차원의 임베딩 벡터로 표현
- layers (ModuleList): 모델의 핵심 부분!!. 28개의 Qwen2DecoderLayer가 순차적으로 연결.
- self_attn (Qwen2SdpaAttention): Self-Attention 메커니즘을 구현, 입력 시퀀스 내의 각 토큰이 다른 모든 토큰과의 관계를 파악.이때 Qwen2RotaryEmbedding을 사용하여 위치 정보를 효과적으로 반영하며, QuantLinear를 사용하여 양자화를 통해 모델 크기 경량화
- mlp (Qwen2MLP): MLP(Multi-Layer Perceptron)는 각 토큰의 표현을 더욱 풍부하게 만들어 줌. SiLU 활성화 함수를 사용하며, QuantLinear를 사용하여 양자화를 수행
- input_layernorm (Qwen2RMSNorm): 각 디코더 레이어의 입력에 레이어 정규화를 적용하여 학습 안정성을 높이고 성능을 향상시킵니다.
- post_attention_layernorm (Qwen2RMSNorm): Self-Attention 계산 후 레이어 정규화를 적용합니다.
- norm (Qwen2RMSNorm): 모델의 마지막에 레이어 정규화를 적용, 출력값 정규화 진행
2. lm_head (Linear):
- 마지막 디코더 레이어의 출력을 151,936개의 토큰에 대한 확률 분포로 변환. 이 확률 분포를 기반으로 다음 토큰 예측.
특징:
- Qwen2SdpaAttention: Qwen2 모델은 Scaled Dot-Product Attention(SDPA)의 변형인 SDPA를 사용, 계산 효율성 향상!
- Qwen2RotaryEmbedding: 회전 위치 Embedding 을 사용하여 토큰의 위치 정보를 효과적로 모델링
- Qwen2RMSNorm: RMSNorm(Root Mean Square Layer Normalization)을 사용하여 레이어 정규화를 수행
- QuantLinear: 양자화된 선형 변환을 사용하여 모델 크기를 줄이고 추론 속도를 높입니다.
3. Qwen2 vs Llama3 모델 비교분석!!

두 모델을 간단히 표로 비교 분석한 결과는 다음과 같습니다.
(좋은곳을 빨간색으로 처리 , Linear와 QuantLinear는 장단점이 있기에 뒤에서 다시 공부함!)
| Llama3 | Qwen2 | |
| 토큰 수 | 128,256개 | 151,936개 |
| Embedding | 4,096 차원 | 1,536 차원 |
| 레이어 수 | 32개의 디코더 레이어 | 28개의 디코더 레이어 |
| Self-attention 특징* | 전통적인 Linear 레이어 사용 | QuantLinear를 사용하여 계산 효율성을 높임 |
| Self-attention 구성 | q_proj: Linear( 4,096 -> 4,096) k_proj: Linear(4,096 -> 1,024) v_proj: Linear(4,096 -> 1,024) o_proj: Linear(4,096 -> 4,096) rotary_emb: LlamaRotaryEmbedding |
q_proj: QuantLinear k_proj: QuantLinear v_proj: QuantLinear o_proj: QuantLinear rotary_emb: Qwen2RotaryEmbedding |
| MLP 구성 | gate_proj: Linear(4,096 -> 14,336) up_proj: Linear(4,096 -> 14,336) down_proj: Linear(14,336 -> 4,096) act_fn: SiLU |
gate_proj: QuantLinear up_proj: QuantLinear down_proj: QuantLinear act_fn: SiLU |
| Normalization | LlamaRMSNorm | Qwen2RMSNorm |
| Output | 4,096 차원 > 128,256 차원 | 1,536 차원> 151,936 차원 |
| 차원 및 프로젝션 | Query와 Key의 차원이 다름 (4,096과 1,024) MLP의 차원 변환이 매우 큼 (4,096 -> 14,336) |
모든 프로젝션이 양자화된 Linear로 처리됨 차원이 상대적으로 작음 (1,536) |
| 모델 크기 | 더 큰 모델 크기와 더 높은 차원 | 양자화된 연산을 통해 메모리와 계산 효율성을 높임 |
| 모델의 목적과 사용 사례 | 복잡한 언어 모델링 작업에서 높은 성능 더 많은 레이어와 높은 차원을 사용 |
메모리와 계산 효율성을 극대화 리소스가 제한된 환경에서 유리 |
세부적으로 두 모델의 장단점을 비교해보면~~~
Llama3는!!?
요약 : 미국 기업 Meta로 nvidia 그래픽을 빵빵하게 사용하여 다양하게 학습, 높은 성능으로 사용가능한 모델!!
장점
- 높은 표현력:
- 높은 차원(4,096)을 사용하여 복잡한 언어 표현을 더 잘 포착할 수 있고.
- 32개의 디코더 레이어를 통해 더 깊은 학습이 가능
- 복잡한 언어 모델링:
- 더 많은 레이어와 높은 차원을 통해 복잡한 언어 모델링 작업에서 높은 성능을 발휘할 수 있습니다.
- 정교한 MLP 구조:
- MLP의 gate_proj, up_proj, down_proj의 차원 변환이 커서 더 복잡한 함수 근사를 할 수 있다!!.
단점
- 높은 계산 비용:
- 높은 차원과 많은 레이어로 인해 계산 비용과 메모리 사용량이 큽니다.
- 모델 크기:
- 큰 모델 크기로 인해 훈련 및 추론 시 더 많은 하드웨어 리소스가 필요합니다.
- 느린 추론 속도:
- 높은 차원과 많은 레이어로 인해 실시간 추론 속도가 느릴 수 있습니다.
Qwen2은!?
요약 : 중국 기업 알리바바가 없는 그래픽 상황에서 효율성을 바탕으로 빠르게 연산하여 사용가능한 모델!!
장점
- 효율성:
- QuantLinear를 사용하여 메모리 사용량과 계산 비용을 줄임으로써 높은 효율성
- 더 낮은 차원(1,536)으로 빠른 연산이 가능.
- 적은 리소스 사용 : 리소스가 제한된 환경에서도 효과적으로 작동
- 추론 속도 : 양자화된 연산을 통해 빠른 추론 속도를 제공
단점
- 표현력 제한 : 낮은 차원으로 인해 매우 복잡한 언어 표현을 포착하는 데 제한됨
- MLP 구조의 단순화 : QuantLinear로 단순화된 MLP 구조는 매우 복잡한 함수 근사에 어려움
- 레이어 수 제한: 28개의 레이어로, 더 많은 레이어를 사용하는 모델에 비해 깊이 있는 학습 어려움!
4. 더 알아보기!! Self-attention에서의 Linear 와 QuantLinear
한줄요약 : llama3와 qwen2의 특징과 같이 Linear는 높은 표현혁 but 높은 리소스사용, QuantLinear는 효율적 리소스 낮은 표현력!!
Linear 란?
Linear 레이어는 신경망의 기본 구성 요소 중 하나, 입력 벡터에 대한 선형 변환을 수행
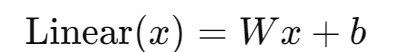
W : 가중치 행렬 / 바이어스 벡터 / x: 입력 벡터
장점
- 표현력:높은 정밀도로 가중치를 학습하여 복잡한 패턴을 모델링 가능
- 유연성:다양한 크기와 형태의 데이터를 처리 가능
단점
- 메모리 사용량: 높은 정밀도의 가중치를 저장해야 하므로 높은 메모리 사용량
- 계산 비용: 높은 정밀도로 인해 큰 계산 비용
QuantLinear
QuantLinear는 양자화(Quantization)된 Linear 레이어로, 모델의 가중치를 정밀도를 낮춰 저장하고 계산합니다. 일반적으로 32비트 부동소수점 대신 8비트 정수 또는 그 이하로 가중치를 표현합니다.
장점
- 메모리 효율성 : 가중치를 낮은 정밀도로 저장하여 메모리 사용량 최소화.
- 계산 속도: 정수 연산은 부동소수점 연산보다 빠르므로 계산 속도 증가
- 저전력: 메모리 접근과 연산 비용이 줄어들어 전력 소모가 감소
단점
- 표현력 감소 : 낮은 정밀도로 인해 가중치 표현력이 감소
- 정보 손실:양자화 과정에서 일부 정보 손실이 발생
Linear 와 Quantlinear 비교 표!
| Linear | QuantLinear | |
| 정밀도 | 높은 정밀도 (보통 32비트 부동소수점) | 낮은 정밀도 (보통 8비트 정수 또는 그 이하) |
| 메모리 사용량 | 높은 메모리 사용량 | 낮은 메모리 사용량 |
| 계산 비용 | 높은 계산 비용 | 낮은 계산 비용 |
| 계산 속도 | 상대적으로 느림 | 상대적으로 빠름 |
| 표현력 | 높은 표현력 | 낮은 표현력 |
| 정보 손실 | 없음 | 양자화 과정에서 일부 정보 손실 발생 |
| 사용 사례 | 복잡한 모델링과 높은 정밀도가 필요한 경우 | 리소스가 제한된 환경, 실시간 응답이 필요한 응용 프로그램 등 |
'데이터&AI > LLM' 카테고리의 다른 글
| RMSNorm과 Layer Normalization 비교하기 (0) | 2024.06.28 |
|---|---|
| 오픈 소스 LLM 서빙 소프트웨어 비교해보기!! (vLLM, Ollama, OpenLLM, LocalAI, llamafiles, GPT4All) (1) | 2024.06.25 |
| 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력) (0) | 2024.06.23 |
| Hugging Face Transformers: Pipeline vs. AutoModel, 뭘 사용할까!?? (0) | 2024.06.22 |
| llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom) (0) | 2024.06.21 |




댓글