airllm으로 llama3를 썻다가 메모리 부족 문제로 실행하지 못하는 문제를 겪었었습니다!!
2024.05.07 - [데이터&AI/LLM] - 내 서버에서 llama3 70B 모델 사용하기 (feat. airllm)
내 서버에서 llama3 70B 모델 사용하기 (feat. airllm)
2024.04.19 - [데이터&AI/LLM] - llama3 무료로 쉽게 사용해보기 (feat. huggingface) llama3 무료로 쉽게 사용해보기 (feat. huggingface)우리시간 지난 밤(2024년 4월 18~19일 밤) 메타에서는 라마3를 오픈소스를 공개
drfirst.tistory.com
그런데!! 이제는 내 서버에서!!!
한국어를 잘하는 llama3 오픈소스 모델을 사용할수 있게되었습니다!!
바로바로
Bllossom
입니다!!
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B
MLP-KTLim/llama-3-Korean-Bllossom-8B · Hugging Face
Update! [2024.06.18] 사전학습량을 250GB까지 늘린 Bllossom ELO모델로 업데이트 되었습니다. 다만 단어확장은 하지 않았습니다. 기존 단어확장된 long-context 모델을 활용하고 싶으신분은 개인연락주세요!
huggingface.co
공식 사이트의 소개를 본다면~~
저희 Bllossom팀 에서 한국어-영어 이중 언어모델인 Bllossom을 공개했습니다!
서울과기대 슈퍼컴퓨팅 센터의 지원으로 100GB가넘는 한국어로 모델전체를 풀튜닝한 한국어 강화 이중언어 모델입니다!
한국어 잘하는 모델 찾고 있지 않으셨나요?
- 한국어 최초! 무려 3만개가 넘는 한국어 어휘확장
- Llama3대비 대략 25% 더 긴 길이의 한국어 Context 처리가능
- 한국어-영어 Pararell Corpus를 활용한 한국어-영어 지식연결 (사전학습)
- 한국어 문화, 언어를 고려해 언어학자가 제작한 데이터를 활용한 미세조정
- 강화학습
이 모든게 한꺼번에 적용되고 상업적 이용이 가능한 Bllossom을 이용해 여러분 만의 모델을 만들어보세욥!
무려 Colab 무료 GPU로 학습이 가능합니다. 혹은 양자화 모델로 CPU에올려보세요 [양자화모델](https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B-4bit)
1. Bllossom-8B는 서울과기대, 테디썸, 연세대 언어자원 연구실의 언어학자와 협업해 만든 실용주의기반 언어모델입니다! 앞으로 지속적인 업데이트를 통해 관리하겠습니다 많이 활용해주세요 🙂
2. 초 강력한 Advanced-Bllossom 8B, 70B모델, 시각-언어모델을 보유하고 있습니다! (궁금하신분은 개별 연락주세요!!)
3. Bllossom은 NAACL2024, LREC-COLING2024 (구두) 발표로 채택되었습니다.
4. 좋은 언어모델 계속 업데이트 하겠습니다!! 한국어 강화를위해 공동 연구하실분(특히논문) 언제든 환영합니다!!
특히 소량의 GPU라도 대여 가능한팀은 언제든 연락주세요! 만들고 싶은거 도와드려요.
라고합니다!!!
Bllossom
chat.bllossom.ai
에서 chatgpt같이 대화를 해볼 수 있습니다 (지금은 작동을 안하는것같네요ㅠ)
이제 코드로 성능을 한번 볼까요~~?
코드는 매우 간단합니다!!
아래와 같이 모델을 다운받은 뒤!!
import transformers
import torch
model_id = "MLP-KTLim/llama-3-Korean-Bllossom-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
프롬포트를 입력하면!!?
PROMPT = '''You are a helpful AI assistant. Please answer the user's questions kindly. 당신은 유능한 AI 어시스턴트 입니다. 사용자의 질문에 대해 친절하게 한국어로 답변해주세요.'''
instruction = "대한민국의 역사 소개해줘 "
messages = [
{"role": "system", "content": f"{PROMPT}"},
{"role": "user", "content": f"{instruction[:2000]}"}
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9
)
print(outputs[0]["generated_text"][len(prompt):])
한국어로 참 결과를 잘 알려주네요!
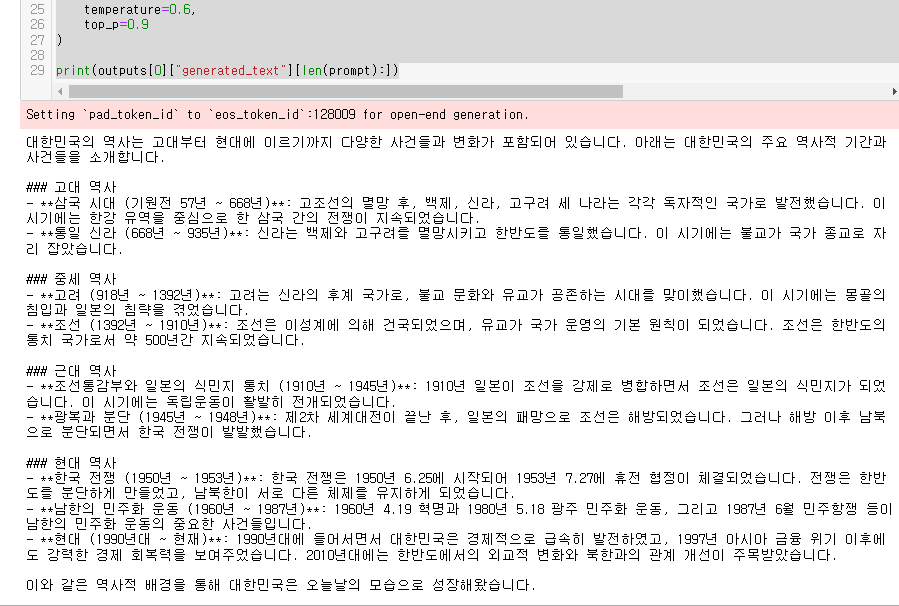
성능이 참 맘에 드는데요!!
이번에는 모델을 세부적으로 분석해보곘습니다!!
pipeline.model.eval()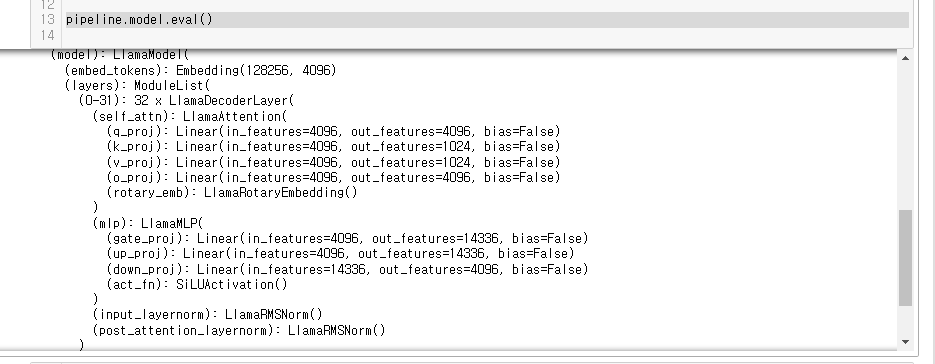
이 모델은 Hugging Face의 Transformers 라이브러리에서 제공하는,LlamaForCausalLM 클래스의 인스턴스로,
LLaMA (Large Language Model Meta AI) 모델을 기반으로 한 Causal Language Modeling을 수행합니다.
이 모델은 자연어 처리(NLP) 작업에서 주로 텍스트 생성, 자동 완성, 대화 시스템 등에 사용됩니다.
모델의 주요 구성 요소와 기능을 살펴보겠습니다.
주요 구성 요소
- Embedding Layer (embed_tokens):
- 이 레이어는 입력 토큰을 고차원 벡터로 변환합니다.
- 모델의 어휘 크기는 128,256이고, 임베딩 차원은 4,096입니다.
- LlamaDecoderLayer:
- 이 모델은 총 32개의 디코더 레이어로 구성되어 있습니다.
- 각 디코더 레이어는 다음의 서브 모듈로 이루어져 있습니다.
- Self-Attention Mechanism (self_attn):
- LlamaAttention:
- q_proj (Query Projection): 입력 피처(4,096차원)를 쿼리로 변환 demension > 4096
- k_proj (Key Projection): 입력 피처를 키로 변환. demension > 1,024
- v_proj (Value Projection): 입력 피처를 값으로 변환. demension > 1,024
- o_proj (Output Projection): 출력 피처(4,096차원)를 생성. demension > 4096
- rotary_emb (Rotary Embedding): 회전 임베딩을 사용하여 위치 정보를 인코딩
- LlamaAttention:
- MLP (Multi-Layer Perceptron):
- LlamaMLP:
- gate_proj: 입력 피처(4096)를 14,336차원으로 변환
- up_proj: 입력 피처 (4096) 를 14,336차원으로 변환
- down_proj: 14,336차원의 피처를 다시 4,096차원으로 변환.
- act_fn (SiLUActivation): 활성화 함수로 SiLU (Sigmoid Linear Unit)를 사용합니다.
- LlamaMLP:
- Normalization Layers:
- input_layernorm: 입력에 대해 RMS (Root Mean Square) 정규화를 수행합니다.
- post_attention_layernorm: self-attention 이후 RMS 정규화를 수행합니다.
- norm: 전체 모델의 최종 RMS 정규화 레이어입니다.
- Language Modeling Head (lm_head):
- lm_head: 4,096차원의 피처를 어휘 크기(128,256)로 변환하여 최종 출력을 생성합니다.
모델 설명
- 대규모 어휘: 128,256개의 토큰을 처리할 수 있는 모델!! (gpt-4o의 tokens is 128,000)
- 고차원 피처: 4,096차원의 임베딩과 출력 피처를 사용하여 높은 표현력을 제공합니다. (gpt4는 미공개)
- 복잡한 디코더 구조: 32개의 디코더 레이어로 구성, 각 레이어는 self-attention 메커니즘과 다층 퍼셉트론(MLP)을 포함
- 위치 정보 인코딩: 회전 임베딩( rotary_emb)을 통해 위치 정보를 인코딩, 모델이 문맥을 더 잘 이해
- 정규화: 여러 RMS 정규화 레이어를 통해 안정적이고 효율적인 학습을 지원
내 GPU 서버에서 이렇게편하게 한국어 모델을 돌릴수 있다니!!
감동x100이네요ㅠㅠ
게다가 오픈소스이기에,, 이모델로 파인튜닝&모델고도화를 진행해봐야겠습니다~!^^
'데이터&AI > LLM' 카테고리의 다른 글
| 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력) (0) | 2024.06.23 |
|---|---|
| Hugging Face Transformers: Pipeline vs. AutoModel, 뭘 사용할까!?? (0) | 2024.06.22 |
| Solar 오픈소스 모델 활용해서 ON-premise LLM 만들기 (0) | 2024.06.13 |
| [STT] 녹음파일에서 텍스트 추출하기!! by OpenAI Whisper(feat python) (0) | 2024.06.08 |
| llama3 의 모델을 api로 호출하기!! (feat. ollama, python, embedding) (0) | 2024.06.01 |




댓글