내가 질문한 내용을!! GPT에 보내고 답변하기!!
RAG의 기본입니다!!
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(openai_api_key = '{내api키}')
my_text = """
구글이 새로운 영상 생성형 인공지능(AI) 모델을 공개했다. 챗GPT로 시장의 게임 체인저가 된 오픈AI에 가려졌던 구글의 AI 역량이 다시 주목받고 있다.
지난달 25일 구글은 영상 생성 AI ‘루미에르’를 선보였다. 기존에 공개된 영상 생성 AI에 비해 진보된 성능이란 평가를 받으며 학계와 업계의 관심을 끌고 있다. 루미에르에는 구글이 개발한 신기술인 ‘시공간 U-넷’이 적용됐다. 영상 전체를 한 번에 처리하는 기술이다.
기존의 영상 생성 AI는 시간-초해상도(TSR)를 사용했다. 몇 개의 기준 프레임을 만들고 그 사이를 채워 시간해상도를 높여 영상을 제작하는 방식이다. 시간해상도는 관측이 얼마나 자주 이뤄지는지를 의미한다. 프레임 수가 많은 영상은 시간해상도가 높다.
"""
my_question = "루미에르는 뭐야?"
res_langchain = llm.invoke(f"{my_text} 위 문장을 기반으로 답변해줘 {my_question}")
res_langchain
위의 코드를 실행해보면!!
아래의 이미지와 같이! 필요한 답변을 잘하는것을 볼 수 있습니다!

그런대 만약!!
input 문구가,, 너무 길어진다면 어떨까요!?
예를 들어서!! gpt-3.5의 4086토큰제한으로, 긴 input문구가 들어간다면,
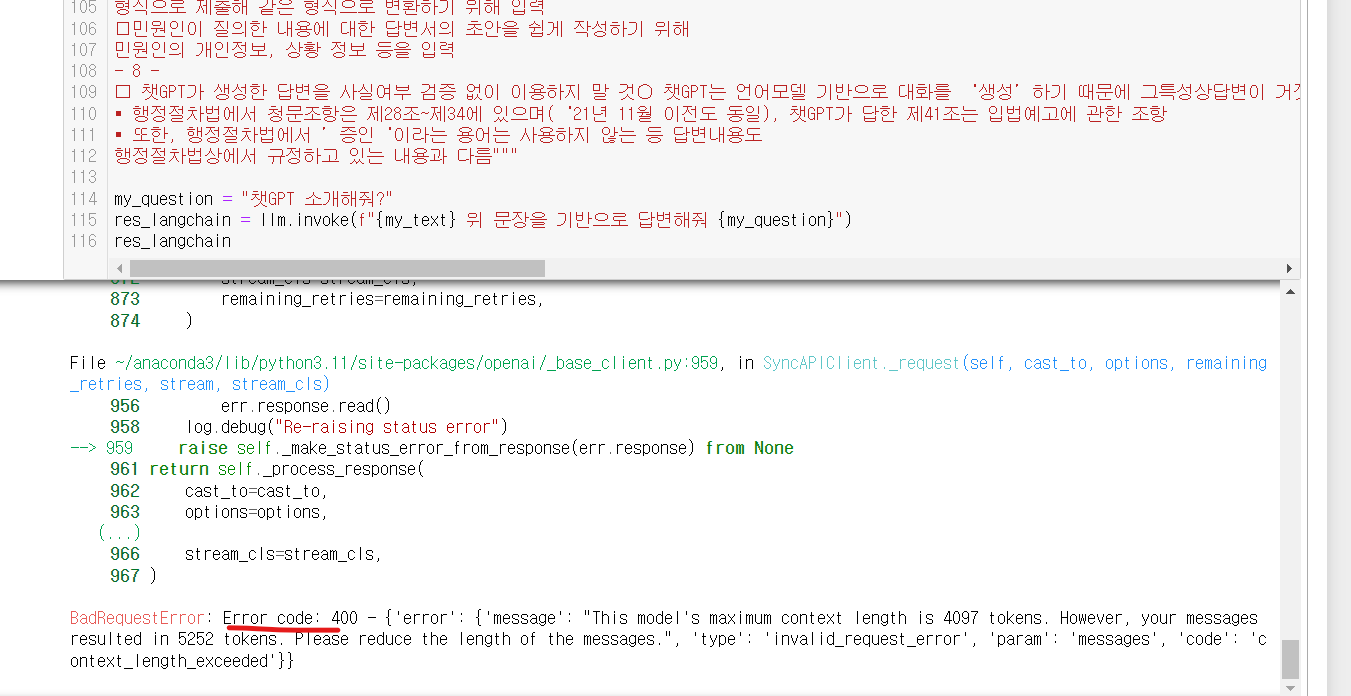
아래와 같이 토큰수를 초과한다는 에러가 발생하는데요!!
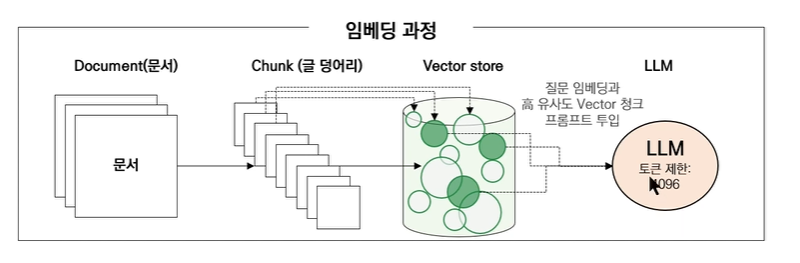
이때의 해결책으로 바로 text splitter가 등장합니다!!
text splitter는 긴 문서를 한번에 GPT에 넣는것이 아니라,
embedding 을 통하여 chunk로 split 하여 저장하게 되는데요!!
그래서 이후 사용자의 질문에 있어,
1. 그 질문에 가장 유사한 chunk 를 찾고,
2. chunk과 질문을 넣어서 LLM에게 답변을 받게됩니다!!
코드로 함꼐 알아보아요!!
1. 관련 패키지 로딩 :필요핸 패키지들을 불러옵니다!!
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
import tiktoken
tokenizer = tiktoken.encoding_for_model('gpt-3.5-turbo')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
2. embedding 모델 불러오기 : 한글 텍스트들을 벡터화하여 embeding할 모델을 불러옵니다!
huggingface에 공개된 모델을 불러올 예정입니다
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
3. 나의 긴 텍스트를 langchain 에서 로드해야합니다!!
my_text = """
챗GPT(ChatGPT) 개요
□ 챗GPT(ChatGPT)는 OpenAI社의 초거대 언어모델인 GPT-3.5,
GPT-4를 기반으로 동작하는 인공지능 챗봇 서비스
▪챗GPT : GPT-3.5를 기반으로 한 무료 버전(’22.11월 공개)
▪챗GPT 플러스 : GPT-4 등 향상된 기능을 사용 가능한 유료 버전(’23.2월 출시)
○ GPT는 OpenAI社가 만든 초거대 언어모델(LLM)로 챗GPT는2021년9월까지의 데이터를 학습
▪GPT(Generative Pre-trained Transformer) : 사전 학습된 생성형 트랜스포머(알고리즘)
▪초거대 언어모델(LLM, Large Language Model) : 문장 내 앞서 등장한 단어를
기반으로 뒤에 어떤 단어가 등장해야 문장이 자연스러운지를 예측하여 문장을완성하는 자연어 처리 모델로 대규모 텍스트 데이터를 학습하여 대화의
맥락을 이해하고, 대화를 기억하는 등 사람처럼 응답하는 능력을 지님□ 챗GPT와 같은 초거대 인공지능 서비스를 구글, 메타, 네이버,
LG, 카카오 등 국내·외 기업에서 출시하였거나, 출시 예정▪해외 : 구글 Bard(챗봇, ’23.2월 공개), 메타 LLAMA(LLM, ’23.2월 공개) 등
▪국내 : 네이버 하이퍼클로바X(LLM), 서치GPT(검색서비스) ’23.7월 출시예정, LG 엑사원(LLM)을 상담, 디자인, 바이오 등에 활용 확대(’23년~), 카카오 KoGPT(LLM), 한국형 챗GPT(챗봇) ’23년 하반기 출시예정 등<GPT 모델 발달 역사>
- 2 -
Ⅱ 챗GPT 활용가능 분야 및 활용예시
< 챗GPT를 공공에서 활용가능한 분야 >
1. 정보탐색능력 활용 2. 언어능력 활용 3. 컴퓨터능력 활용기획 보고서 작성을 위한
아이디어 탐색
‚업무에 필요한 국내외
자료 조사
ƒ보도자료, 인사말, 강의자료
등 대외 공개자료 초안 작성
„언론기사, 논문, 보고서 등
외부자료 요약
…해외사례 조사, 해외 홍보
등을 위한 언어 간 번역
†엑셀 등 응용프로그램
사용법
‡업무 자동화 프로그램
코드 생성
1. 정보탐색능력 활용
(아이디어 탐색) 새로운 콘텐츠 발굴, 문제 해결방안 마련 등신규기획이나, 보고서 작성에 필요한 아이디어를 얻고자 하는 경우 ※ 질문을 구체적으로 하거나, 추가적인 질문을 하여 상세한 답변 유도가 가능 ※ 다만, 질문 과정에서 미확정 정책 등이 유출되지 않도록 유의
연번 질문 예시
Q1 저출산 문제에 대한 정책을 수립하려고 합니다. 돌봄, 사회적 인식, 고용, 정부 지원 등 다양한 측면에서 아이디어를 제시해 주세요. 외국의사례를 함께 제시해 주세요. Q2 청년의 일자리를 늘리기 위한 아이디어를 해외사례와 매칭시켜서
알려주세요. 지원과 관련한 금액과 기간같은 구체적인 수치도 함께
알려주세요. Q3 해외에 인공지능을 활용한 행정서비스에 대해 열 가지 알려주세요. Q4 지역화폐를 시민들이 잘 활용할 수 있도록 하기 위해 정부는 어떤
일을 해야 할까요?
Q5 플라스틱 신분증을 모바일 전자신분증으로 바꿨을 때 예상되는 장점과단점은 무엇이 있을까요?
- 3 -
‚ (국내외 자료조사) 업무에 참고하기 위해 인터넷상에 널리퍼진연구, 논문, 공식자료 등에 포함된 내용을 수집하고 싶은 경우 ※ ’21년 이전 자료만 조사 가능 / 국외 자료 조사의 경우 영어로 질문 시 답변 정확도 상승 ※ 답변내용이 부정확할 수 있으므로 답변 출처 등을 찾아 반드시 확인 필요연번 질문 예시
Q1 한국을 제외한 나라에서 정년(연금수령 연령) 연장 사례와 그에 관련된연구내용에 대해 알려주세요. Q2 남성의 육아휴직이 저출산에 미치는 영향에 대해 연구된 내용들을
알려주세요. Q3 공식적 자료를 활용하여 애플의 스마트폰 매출액과 삼성전자의 스마트폰매출액을 2019년 1분기부터 2020년 3분기까지 비교해주세요. 해당
자료의 출처도 말해주세요. Q4 자연어 처리 인공지능 알고리즘에 대한 논문인 ‘Attention is all
you need’에 대해 비전공자도 알기 쉽게 설명해주세요
2. 언어능력 활용
ƒ (보도자료 등 초안 작성) 보도자료, 인사말, 강의(강연)자료 등대외공개하는 자료의 작성을 효율적으로 하기 위해 초안이 필요한경우 ※ 초안 작성을 위해 미확정 정책, 대외비 등 비공개 정보나, 개인정보를 질문으로 입력하는 경우 정보가 유출될 수 있으므로 주의 필요
연번 질문 예시
Q1 초거대 AI 공공부문 활용방안 세미나 개최계획을 기초로 보도자료로만들려고 합니다. 아래 계획을 참고하여 보도자료를 만들어 주세요. 첫 문단에는 행사 개요와 목적, 둘째 문단에는 세미나 내용, 셋째
문단에는 공개토론을 통한 세미나의 기대효과를 넣어서 작성해주세요.
- 4 -
연번 질문 예시
Q2 인공지능의 공공부문 도입을 주제로 하는 세미나에서 인사말을 해야하는데 초안을 1,500자 내외로 작성해주세요. Q3 청년 창업 지원에 대한 정부의 정책을 대학 졸업생들에게 쉽게 설명하려 하는데 어떤 내용과 순서로 설명하면 좋을까요?
„ (외부자료 요약) 언론기사, 논문 등 많은 분량의 내용을 짧은시간에이해해야 하거나, 간략히 전달하기 위해 요약이 필요한 경우연번 질문 예시
Q1 ‘윤석열 대통령은 14일 디지털플랫폼정부 추진 과정에서 인공지능(AI)‧소프트웨어 분야 등 전후방 효과가 클 것이라고 밝혔다...(생략)...’* 위 기사내용을 100자 내외로 요약해주세요. Q2 ‘AI 기술이 발전할수록 사이버 범죄와 사생활 유출 가능성이 높아지고있다. AI는 사람처럼 실수하지 않고 차별과 편견 없이...(생략)...’** 위 논문의 핵심을 10가지로 요약해주세요.
* ‘尹 “벽 깨고 연결하는 디지털플랫폼정부로 기득권 깨겠다”’ - 연합뉴스(’23.4.14) ** ‘인공지능 기술보다 중요한 인공지능 윤리’ - 한국뇌과학연구원(’23.3월)
… (언어 간 번역) 해외사례 조사, 해외 홍보 등 언어 간 번역및미국식‧영국식 영어 등 현지화된 번역이 필요한 경우
연번 질문 예시
Q1 ‘La direction interministérielle du numérique (DINUM) est en
charge de la transformation numérique de l’État au bénéfice du
citoyen comme de l’agent, ...(생략)...‘* 위 불어 자료를 한국어로 번역해주세요
Q2 ‘챗GPT가 공무원의 업무혁신을 이끈다 - 초거대 인공지능 공공부문
활용방안 세미나 개최 ...(생략)...’** 위 보도자료를 미국 언론보도 스타일로 번역해주세요.
* 프랑스 디지털행정부(DINUM) 소개자료
** ‘챗GPT가 공무원의 업무혁신을 이끈다’ - 행안부 보도자료(’23.3.30.)
- 5 -
3. 컴퓨터능력 활용
† (업무용 응용프로그램 사용법 탐색) 엑셀 등 업무용 응용프로그램의사용법을 쉽게 찾으려는 경우
※ 한 번의 질문보다는 추가 질문으로 보다 정확한 사용법 확인이 가능연번 질문 예시
Q1 엑셀 표에 입력된 값들 중 50을 넘는 값을 노란색으로 표시해주는
방법에 대해 알려주세요. Q2 2021년부터 2023년까지 사업 예산에 대한 연평균 증가율을 엑셀로
구하는 방법에 대해 알려주세요. ‡ (업무 자동화 프로그램 제작) 많은 자료 병합, 특정 키워드포함기사 검색·정리 등 반복적 업무에 드는 시간을 단축하려는경우 ※ 자동화 프로그램의 제작‧활용을 위해서는 기본적으로 프로그래밍에 대한
이해가 필요 (이용자의 컴퓨터 환경에 따라 프로그램 코드 수정이 필요)
연번 질문 예시
Q1 (엑셀 취합) 자료 조사로 기관들이 제출한 엑셀파일들을 하나의 파일로 취합하는 엑셀 매크로를 만들어주세요. è 챗GPT는 엑셀 안에서 사용되는 프로그램(VBA) 코드를 생성Q2 (기사 검색‧정리) ㅇㅇㅇ 뉴스에서 행정안전부와 관련된 기사를 찾아제목, 링크, 내용을 정리하는 프로그램을 만들어주세요
è 챗GPT는 파이썬 등의 프로그래밍 언어로 프로그램 코드를 생성
- 6 -
Ⅲ 챗GPT 문제점(한계)와 활용 시 주의사항
1. 문제점(한계)
□ 저작권 · 개인정보 보호
○ 챗GPT가 저작권자의 사용허가 없이 인터넷 기사, 웹사이트게시글등을 학습용 데이터로 이용하는 경우 저작권 문제 논란
▪우리나라 : 명확한 인공지능의 저작물 학습 근거를 마련하기 위한 입법 추진 중
▪미국 : 월스트리트저널, 뉴욕타임즈 등의 유·무료기사를 인공지능 학습에
이용한 사항에 대해 월스트리트저널 모회사가 저작권 위반 소송을 제기○ 챗GPT가 학습하는 정보에 개인정보(인터넷상에 공개된 개인정보)가포함되어 개인정보 보호 규정에 대한 위반 논란
▪이탈리아 : 챗GPT가 학습하기 위해 개인정보를 수집 및 처리하는데, 이에대한 법적 근거가 없다며 챗GPT에 차단 조치 및 조사 시행
□ 중요정보 유출
○ 챗GPT에 입력하는 정보는 저장되고 성능개선을 위한 학습자료로활용 가능*(챗GPT 이용약관)
* ’23.4.25. 개인계정 설정에서 사용자가 입력한 정보는 30일간 저장되고, 성능개선을 위한 학습자료로 활용하지 않도록 하는 선택기능을 추가
▪삼성전자 : 직원이 반도체 프로그램의 오류를 수정하기 위해 프로그램 코드를 챗GPT에 입력한 사실을 확인, 주의 안내 및 일부 이용 제한 등 조치□ 답변의 신뢰성, 윤리성, 편향성
○ 초거대 인공지능은 학습한 단어의 패턴, 관계성을 분석하여 답변을생성하기 때문에 답변이 매우 논리적으로 보일 수 있으나, 거짓된 답변도가능○ 챗GPT는 비윤리적인 질문에 답변을 거부토록 훈련되었으나, 우회적질문으로 비윤리적(또는 범죄)으로 활용할 수 있는 결과물도 제시가능○ 편향적이거나, 차별적 데이터 학습 시 편향적인 답변도 도출가능
- 7 -
2. 활용 시 주의사항
□ 챗GPT에 비공개 정보나, 개인정보를 입력하지 말 것
○ 의사결정이 완료되지 않거나, 공표되지 않은 정보, 외부 반출이허용되지 않는 대외비 등 비공개 정보를 입력하지 않도록주의○ 행사 참석자 정보, 민원인 정보 등 업무처리 과정에서 수집·처리하는 개인정보를 입력하지 않도록 주의
< 잘못된 입력의 예 >
(예시1) 의사결정이 완료되지 않거나, 공표되지 않은 정보
부동산 공급대책, 가상화폐 정책 등 국민에게 중대한 영향을 미치는 정책을정부의 종합적 방향이 최종 확정되지 않거나, 공표되지 않은 상황에서
브리핑 또는 보도자료를 작성하기 위해 정책내용을 입력
(예시2) 외부 반출이 허용되지 않는 정보
행사계획을 작성하기 위해 중요 인사 참석 등 대외비로 관리해야 할 행사
내용을 입력
국산 전투기의 무기 개량 방향에 대한 보고서에 담을 문제점, 개선책에
대한 아이디어를 얻기 위해 현재 국산 전투기의 무기 사양 등을 입력
(예시3) 개인정보 입력
출입 사전등록 중 행사 참석자들이 전화번호 등 개인정보를 서로 다른
형식으로 제출해 같은 형식으로 변환하기 위해 입력
민원인이 질의한 내용에 대한 답변서의 초안을 쉽게 작성하기 위해
민원인의 개인정보, 상황 정보 등을 입력
- 8 -
□ 챗GPT가 생성한 답변을 사실여부 검증 없이 이용하지 말 것○ 챗GPT는 언어모델 기반으로 대화를 ‘생성’하기 때문에 그특성상답변이 거짓 정보일 가능성이 있으므로 항상 검증과 확인이필요 ※ “지금 당장 중요한 일을 챗GPT에 의존하는 것은 실수. 현재 수준은 ‘미리보기’인셈이며 앞으로 견고함과 진실성 면에서 해야 할 일이 많음.” - 샘 알트만, OpenAI 대표< 부정확한 답변 예 >
▪ 행정절차법에서 청문조항은 제28조~제34에 있으며(‘21년 11월 이전도 동일), 챗GPT가 답한 제41조는 입법예고에 관한 조항
▪ 또한, 행정절차법에서 ’증인‘이라는 용어는 사용하지 않는 등 답변내용도
행정절차법상에서 규정하고 있는 내용과 다름"""
# 파일을 쓰기 모드로 엽니다.
with open('saved_my_text.txt', 'w') as file:
# 파일에 텍스트를 씁니다.
file.write(my_text)
이제 핵심부분!!
해당 파일을 읽어온 뒤 Text_splitter로 쪼개서 doccs에 저장합니다!!
loader = TextLoader("saved_my_text.txt")
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0,length_function=tiktoken_len)
docs = text_splitter.split_documents(pages)
4. 이제 임베딩 모델을 활용, Chroma 기반 docs 벡터화를 진행합니다!!
## Chroma 기반 docs 벡터화
chroma_vector = Chroma.from_documents(docs, model_huggingface )'
5. llm모델을 활용, 물어보기 실행!!
llm_model = ChatOpenAI(model_name = 'gpt-3.5-turbo'
,api_key = "{나의 key}"
, temperature = 0 )
my_question = "공공기관에서 챗GPT 활용가능 분야 알려줘"
qa = RetrievalQA.from_chain_type(llm=llm_model
, retriever = chroma_vector.as_retriever())
result_stuff = qa(my_question)
result_stuff
결국 아래와 같이 필요한 부분만을 찾아 잘 대답하는것을 확인할 수 있습니다!!

이때 사용되는 Splitter는 두가지가 있는데요!! 각각의 특징을 알아봅시다!!
1. RecursiveCharacterTextSplitter
- 작동 방식:
- 텍스트를 여러 문자(예: \n\n, \n, " ", "")에 대해 재귀적으로 분할.
- 각 문자에 대해 텍스트를 분할, 분할된 텍스트의 길이가 지정된 chunk_size보다 작거나 같을 때까지 반복
- 기본적으로 다음 순서대로 문자를 사용하여 분할합니다.
- "\n\n" (빈 줄)
- "\n" (줄 바꿈)
- " " (공백)
- "" (빈 문자열)
- 장점:
- 문맥적으로 관련된 텍스트를 함께 유지하는 데 효과적
- 단락, 문장, 단어 단위로 텍스트 분할 가능
- 단점:
- 긴 텍스트를 처리할 때 느린 속도
- chunk_size 설정에 따라 분할 결과 다름
- 코드 예시
from langchain.text_splitter import RecursiveCharacterTextSplitter
# RecursiveCharacterTextSplitter 객체 생성
splitter = RecursiveCharacterTextSplitter(chunk_size=50)
# 텍스트 분할
text = "This is a long sentence. It has multiple clauses and spans multiple lines. We want to split it into smaller chunks."
chunks = splitter.split_text(text)
# 결과 출력
for chunk in chunks:
print(chunk)2. CharacterTextSplitter
- 작동 방식:
- 지정된 separator 문자를 기준으로 텍스트를 분할
- chunk_size 또는 chunk_overlap 설정 고려 X.
- 장점:
- RecursiveCharacterTextSplitter보다 빠르고 간단
- 일관적인 분할 결과
- 단점:
- 사이즈가 크게 분할 될 경우 분석 불가
- 단락, 문장, 단어 단위로 텍스트를 분할 불가
- 코드 예시:
from langchain.text_splitter import CharacterTextSplitter
# CharacterTextSplitter 객체 생성
splitter = CharacterTextSplitter(separator=".")
# 텍스트 분할
text = "This.is.a.sentence.with.multiple.dots."
chunks = splitter.split_text(text)
# 결과 출력
for chunk in chunks:
print(chunk)3. 두 TextSplitter 비교
| 작동 방식 | 재귀적 분할 | separator 기반 분할 |
| 장점 | 문맥 유지 | 속도, 일관성 |
| 단점 | 속도, chunk_size 의존 | 문맥 분리 |
| 적합한 상황 | 문맥 유지가 중요한 경우 | 속도와 일관성이 중요한 경우 |
4. 결론 : 개인적으로는 RecursiveCharacterTextSplitter 추천합니다!!
- 문맥 유지가 중요하다면 RecursiveCharacterTextSplitter를 사용하는 것이 좋습니다.
- 속도와 일관성이 중요하다면 CharacterTextSplitter를 사용하는 것이 좋습니다.
참고이미지!!

ㅁ이 글은 모두의AI 유튜브 강의를 기반으로 작성했습니다`!^^
https://youtu.be/127lV0wcDmc?si=w1NUgIsiEQ9e_sUd




댓글