1. Retriever 종류: Sparse Retriever vs Dense Retriever
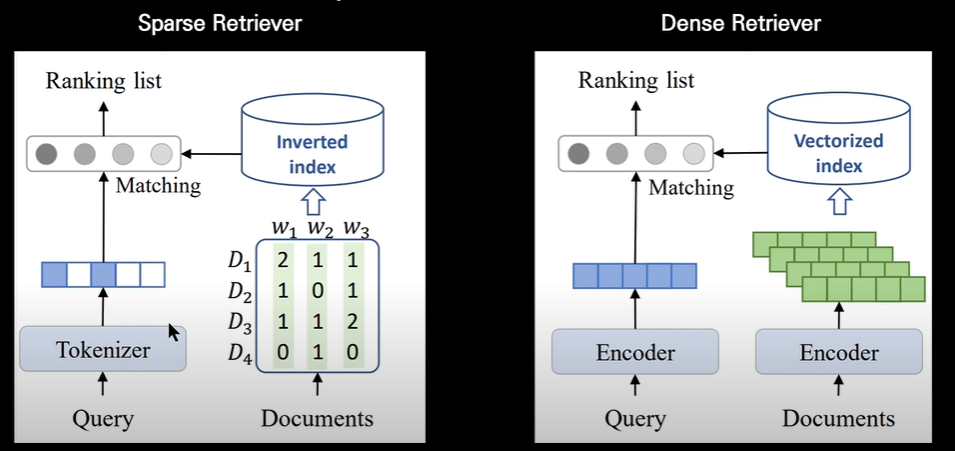
1. 개념
Retriever는 대규모 텍스트 데이터에서 질의와 관련된 정보를 검색하는 데 사용되는 모델
2가지로 구분
2. Sparse Retriever : 텍스트 데이터를 벡터로 변환하여 저장, 질의 벡터와의 유사성을 기반으로 문서 검색
>> TF-IDF와 같은 기법으로 텍스트 데이터를 벡터화 진행
장점:
- 효율적인 메모리 사용
- 빠른 검색 속도
- 높은 확장성
- 질문과 같은 단어만 선택!!!!
단점:
- 낮은 정확도 (but 같은 직접적 단어만 고를떄는 좋다)
- 의미론적 정보 손실
3. Dense Retriever : 텍스트 데이터를 임베딩 벡터로 변환하여 저장, 질의 벡터와의 유사성을 기반으로 관련 문서 검색
>> BERT와 같은 신경망 모델을 사용하여 텍스트 데이터를 임베딩 진행
장점:
- 높은 정확도
- 의미론적 정보 유지 (단어가 다른표현으로 진행해도 가능!!)
단점:
- 높은 메모리 사용
- 느린 검색 속도
- 낮은 확장성
4. Sparse vs Dense 비교
| Sparse Retriever | Dense Retriever | |
| 정확도 | 낮음 | 높음 |
| 의미론적 정보 | 손실 | 유지 |
| 메모리 사용 | 효율적 | 높음 |
| 검색 속도 | 빠름 | 느림 |
| 확장성 | 높음 | 낮음 |
둘다.. 장단점이 있는데,
무엇을 골라야할까요!
그래서 나타난!!
앙상블!! ENsemble Retriever + reciroprocal rank fusion 의 방식이 개발되었습니다!!!
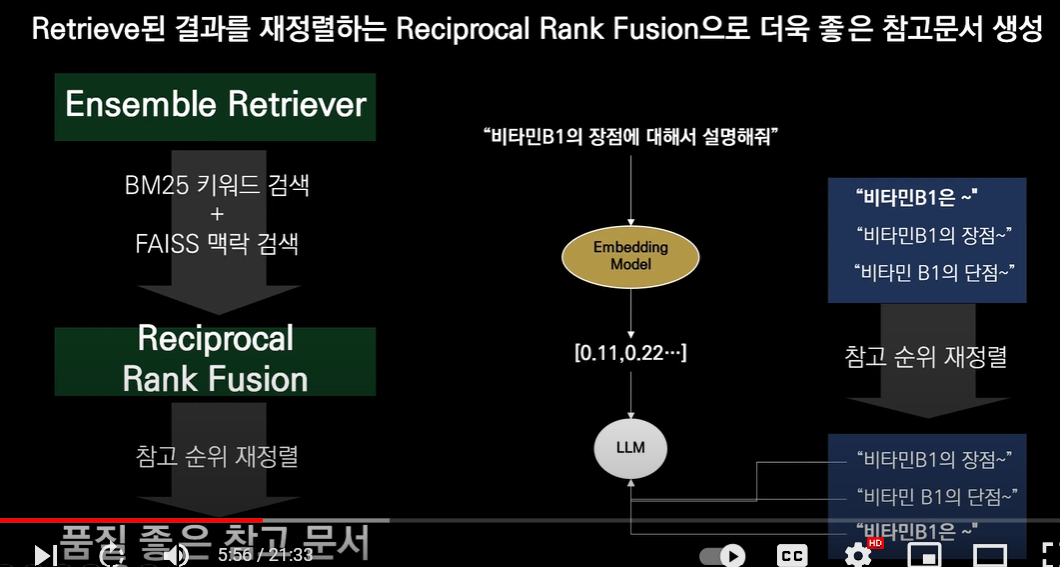
1. 두가지 방법을 결합해서 검색한 뒤
2 문서의 순위를 재정렬해서!! 품잘을 좋게한다
이제 코드를 통해 함꼐 알아봅시다!!
1. 패키지 설치 & 함수 임포트
!pip install rank_bm25
# 새로운 패키지를 설치합니다
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
import openai
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import HuggingFaceEmbeddings
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
from langchain.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import FAISS'
2. 텍스트 가져오기!! 바드에 대한 리뷰 url 두개를 가져와서 로드합니다!!
## pdf 파일로드 하고 쪼개기
loaders = [
WebBaseLoader('https://www.itworld.co.kr/review/317755')
, WebBaseLoader('https://textcortex.com/ko/post/google-bard-review')
]
docs = []
for loader in loaders:
docs.extend(loader.load_and_split())
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0,length_function=tiktoken_len)
texts = text_splitter.split_documents(docs)
3.!! retriever 선언!! 앙상블과 dense retriever(기존에 사용하던 chroma 기반)
bm25_retriever = BM25Retriever.from_documents(texts)
bm25_retriever.k = 2
chroma_vector = Chroma.from_documents(texts, model_huggingface )
chroma_retriever = chroma_vector.as_retriever(search_kwargs={'k':2})
4. 각각의 검색 결과를 비교해보면!?
>> 앙상블의 결과보기!
ensemble_retriever = EnsembleRetriever(
retrievers = [bm25_retriever,chroma_retriever]
, weight = {0.5,0.5})
docs = ensemble_retriever.invoke("구글 바드는?")
for i in docs:
print(i.metadata)
print(":")
print(i.page_content)
print("*"*30)

4가지 검색 결과를 찾아줍니다!
>> 기존 dense retriever 결과보기!
chroma_vector = Chroma.from_documents(texts, model_huggingface )
chroma_retriever = chroma_vector.as_retriever(search_kwargs={'k':2})
docs = chroma_retriever.invoke("구글 바드는?")
for i in docs:
print(i.metadata)
print(":")
print(i.page_content)
print("*"*30)

산출된 결과물이 더 적네요!!
이제!! llm 을 활용하여 최종 답변을 생성해볼까요!?
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
llm_model = ChatOpenAI(model_name = 'gpt-3.5-turbo'
,api_key = "{내key넣기}"
, temperature = 0 )
question = "구글 바드는?"
1. BM25. 앙상블 Retriever 결과!!
qa = RetrievalQA.from_chain_type(
llm = llm_model
, chain_type='stuff'
, retriever = ensemble_retriever)
res = qa(question)
res['result']
2. Dense retriever 결과!!
qa = RetrievalQA.from_chain_type(
llm = llm_model
, chain_type='stuff'
, retriever = chroma_retriever)
res = qa(question)
res['result']

딱 봐도!! 앙상블의 결과가 훨씬 좋네요~!!
이런 기술을 활용해서 지속적으로 RAG의 성능향상을 이뤄갈수 있습니다!!
이글은 모두의 AI 유튜브를 보며 정리한 노트입니다~!
https://youtu.be/ehP4vphl_Us?si=TIGZzNBxHMljts0k




댓글