많이 사용하는 huggingface의 BERT 모델!
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
위와 같은 방식으로 로드하는데요!!
그런데,,
조금더 큰 dimension (1536, 허깅페이스는768) 에서 분석을 하고싶다
신뢰할 수 있는 모델을 사용하고싶다
검증된 서비스로 사용하고싶다!!
나는 유료의 안정적인 서비스가 필요하다.
혹은,,
나는 돈이 너무 많다~!
허깅페이스가 싫다
등등 의 사유로 유로 embedding모델을 사용하고 싶을 수 있겠지요?
이에, Openai에서 유료로 제공하는 embedding모델 사용법을 알아보겠습니다!
우선 OpenAI의 유로 embedding 모델을 아래와 같습니다!!
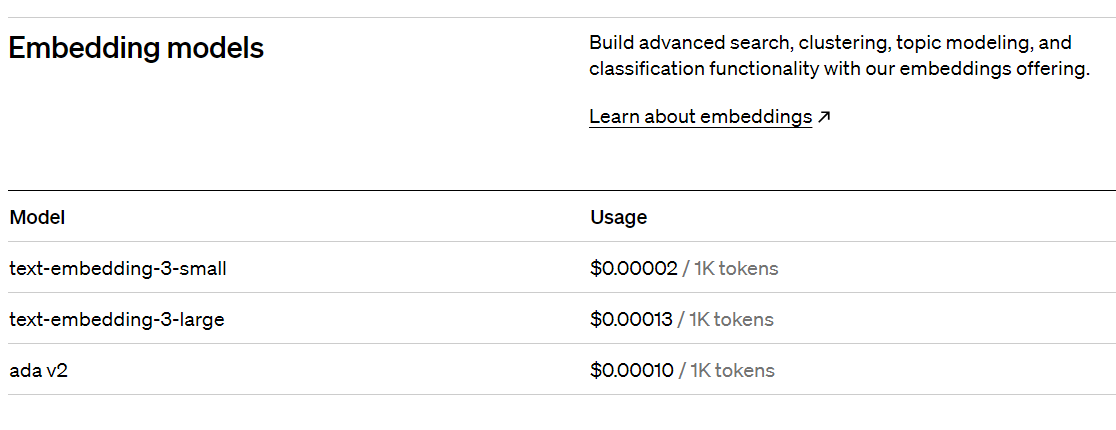
가격이 합리적이지요~!!?
바로 사용해봅시다!!
1. 패키지 임포트
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
## 오늘의 핵심 패키지!!
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.embeddings import OpenAIEmbeddings
# 나의 openai api 키
openai_key = '{입력하기}'
2 OpenAIEmbeddings 을 활용한 ADA 모델 설정!!
model_ada = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=openai_key
)
3. 대상 원문 load 하고 split하기!!
이번 포스팅은 DAO에 관한 pdf 파일을 예씨로 진행해보았습니다!
loader = PyPDFLoader('https://ettrends.etri.re.kr/ettrends/200/0905200008/065-076_%EC%B5%9C%EC%84%A0%EB%AF%B8_200%ED%98%B8.pdf')
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
4. 마지막!! Chroma를 활용, embedding 결과 저장 및 검색 진행!!!
## Chroma 기반 pdf(docs 벡터화)
chroma_vector = Chroma.from_documents(docs, model_ada )
## 해당 vector 에 질문할 객체 생성
chroma_retriever = chroma_vector.as_retriever(search_kwargs={'k':4})
## 질문하기!!
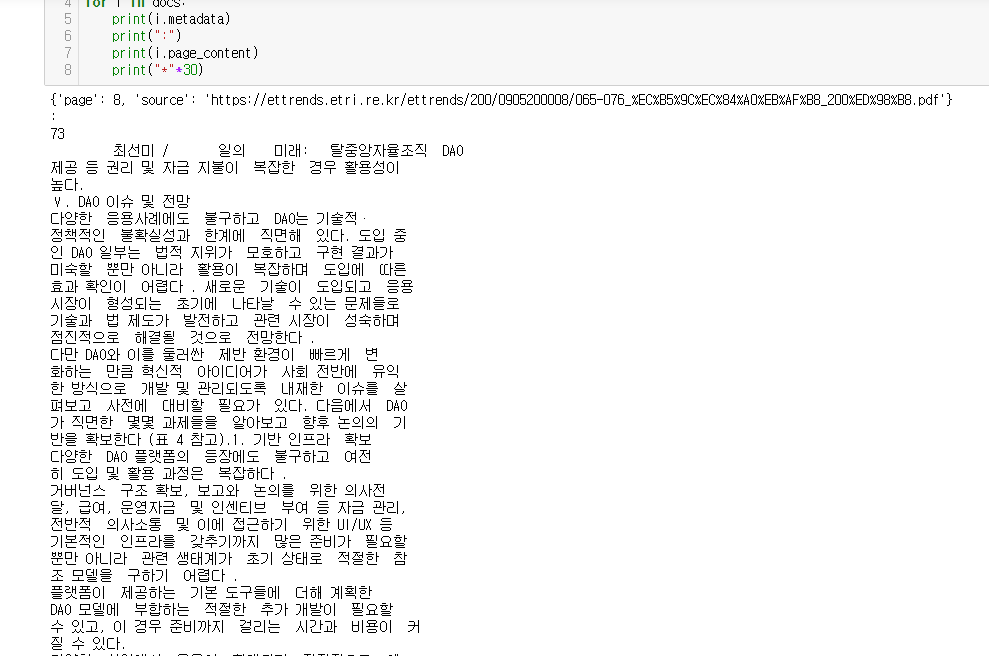
docs = chroma_retriever.invoke("DAO의 활용 사례는?")
for i in docs:
print(i.metadata)
print(":")
print(i.page_content)
print("*"*30)
아래와 같이 잘 검색함을 확인할 수 있습니다!!
무료로 사용하는 hugging face모델로이 방법도 다시한 번 알아볼까요!?
2-huggingface :> 모델 선언하기!!
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
3. huggingface 기반 임베딩 및 질문하여 유사한 텍스트 검색!!
chroma_vector2 = Chroma.from_documents(docs, model_huggingface )
chroma_retriever2 = chroma_vector2.as_retriever(search_kwargs={'k':4})
docs = chroma_retriever2.invoke("DAO의 활용 사례는?")
for i in docs:
print(i.metadata)
print(":")
print(i.page_content)
print("*"*30)



댓글