2024.02.05 - [데이터&AI/langchain] - [langchain공부] Vectorstores. 벡터 저장소 (feat. Chroma, FAISS)
[langchain공부] Vectorstores. 벡터 저장소 (feat. Chroma, FAISS)
사용자가 질문하고 답하는 RAG(Retrieval Augmented Generation, 검색 증강 생성)에서는 텍스트들을 벡터호 하여 Embeding한 하는데, 이 벡터를 저장해두 공간이 필요하다!! 이때 사용되는것이 벡터저장소 (Ve
drfirst.tistory.com
지난 포스팅들을 통해서 embedding된 vectore들을 chroma, FAISS 등의
벡터 저장소에 저장하는 과정을 진행해보았는데요!!
이번 포스팅에선느 NoSQL의 선두주자!! mongoDB에 vector를 저장하는 방법을 알아보겠습니다~!
! 이때 mongo의 버젼은 6.011+, or 7.0.2+ 이어야 합니다!!
0. 관련 패키지 불러오기
import os
import xml.etree.ElementTree as ET
import openai
import tiktoken
# 나의 openai API Key
openai_key = "{key}"
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
# API 엔드포인트와 매개변수 설정
## token count 하는 함수
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
# langchain 의 필요 함수들 불러오기!!
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredXMLLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
## 오늘의 핵심 패키지들!@!
from pymongo import MongoClient
from langchain_community.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
1. 텍스트 자료 불러온 뒤 langchain용 doc로 쪼개기!!
> 이번 포스팅은 테슬라의 10-K 공시 자료를 embedding 하여 몽고DB에 저장해보겠습니다!!
# 테슬라 공시 url
target_url = 'https://www.sec.gov/Archives/edgar/data/1318605/000162828024002390/tsla-20231231.htm'
target_url
# bs로 크롤링해오기!
headers = [
{'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36' },
]
res =requests.get(target_url, headers=headers[0]) ## AAPL
soup= BeautifulSoup(res.content,'html.parser')
# BeautifulSoup 객체에서 XML 문자열로 변환
xml_data = str(soup)
# ElementTree를 사용하여 XML 파일로 저장
root = ET.fromstring(xml_data)
tree = ET.ElementTree(root)
tree.write(f"tesla_10K.xml")
loader = UnstructuredXMLLoader(f"tesla_10K.xml")
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=0,length_function=tiktoken_len)
docs = text_splitter.split_documents(pages)
※ 만약 무료인 huggingface모델로 진행하고싶다면!? 아래와 같이 진행할 수 있어요!
# 관련 패키지 및 모델 불러오기
from langchain.embeddings import HuggingFaceEmbeddings
model_huggingface = HuggingFaceEmbeddings(model_name = "nlpaueb/sec-bert-num")
from langchain_community.vectorstores import MongoDBAtlasVectorSearch
from langchain_openai import OpenAIEmbeddings
# insert the documents in MongoDB Atlas with their embedding
vector_search = MongoDBAtlasVectorSearch.from_documents(
documents=docs,
embedding=model_huggingface, ## 요기가 핵심
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)=================================================================================
위의 작업 결과!!
아래 이미지와 같이 111개의 chunk로 쪼개진것을 확인할 수 있습니다!!
2. mongoDB등장!!!!
> 이번 포스팅은 테슬라의 10-K 공시 자료를 embedding 하여 몽고DB에 저장해보겠습니다!!
MONGODB_ATLAS_CLUSTER_URI = 'mongodb://{ 계정}:{비번}@{몽고DB ip}:{db port}'
# initialize MongoDB python client
client = MongoClient(MONGODB_ATLAS_CLUSTER_URI)
DB_NAME = "test"
COLLECTION_NAME = "langchain_test"
ATLAS_VECTOR_SEARCH_INDEX_NAME = "index_name"
MONGODB_COLLECTION = client[DB_NAME][COLLECTION_NAME]
# insert the documents in MongoDB Atlas with their embedding
vector_search = MongoDBAtlasVectorSearch.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(disallowed_special=(),api_key = openai_key),
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
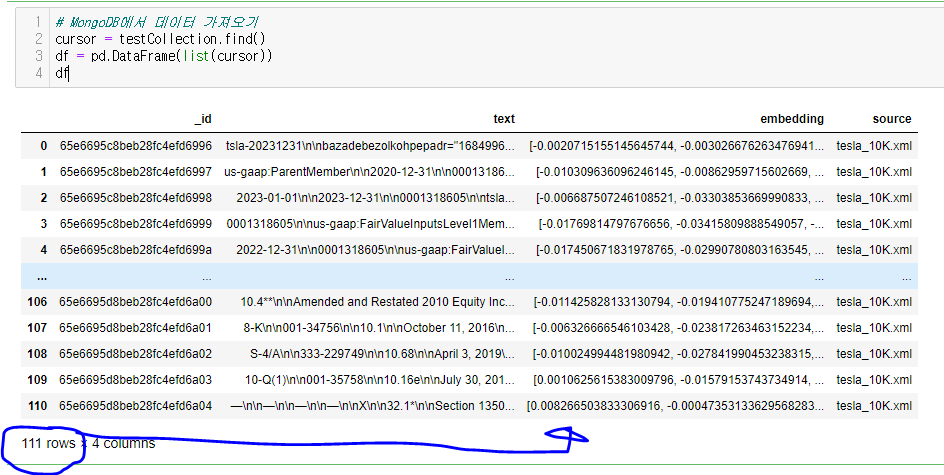
이제 해당 mongoDB를 조회해보면!!
아래와 같이 111개의 chunk가 embedding되어서 저장된것을 확인할 수 있습니다!!
3. RAG!! 질의하기!!!!!
> 아래와 같이 질문을 하면, 임베팅 후 벡터에서 가장 유사한 부분을 찾아서 알려주지요~~
llm = ChatOpenAI(model_name = 'gpt-3.5-turbo'
,api_key = "{api_KEY}"
, temperature = 0 )
question = "main products of tesla"
qa = RetrievalQA.from_chain_type(llm=llm
, chain_type = 'stuff'
, retriever = vector_search.as_retriever( search_type='mmr'
, search_kwargs = {'k':3,'fetch_k':10})
, return_source_documents = True)
result_stuff = qa(question)
result_stuff
! 이때 mongo의 버젼은 6.011+, or 7.0.2+ 이어야 합니다!!
그렇지 않으면 아래와 같은 에러가 발생하게됩니다!
OperationFailure: Unrecognized pipeline stage name: '$vectorSearch', full error: {'operationTime': Timestamp(1709599584, 6), 'ok': 0.0, 'errmsg': "Unrecognized pipeline stage name: '$vectorSearch'", 'code': 40324, 'codeName': 'Location40324', '$clusterTime': {'clusterTime': Timestamp(1709599584, 6), 'signature': {'hash': b'\xfcT\xfa\x0bC\x08\xe7\xac\xea\xfe\xe0o\xa6\x12\xe7\xf0\x90<5\x08', 'keyId': 7306087688048738321}}}
Vector Search: Unrecognized pipeline stage name: '$vectorSearch'
Hello @Lucas_Lind sorry you’re having an issue here, can you confirm this is a cluster in MongoDB Atlas? And what the version of the cluster is?
www.mongodb.com
ㅁ 참고 : https://python.langchain.com/docs/integrations/vectorstores/mongodb_atlas
'데이터&AI > langchain' 카테고리의 다른 글
| OnPremise LLM을 Langchain으로 연결하기 (feat. Solar) (0) | 2024.06.14 |
|---|---|
| [langchain + ollama] langchain으로 llama3 호출하기!!(feat. python, 멀티에이전트) (0) | 2024.06.02 |
| [langchain공부]gpt와 함께하는 few shot learning ! (feat. python) (0) | 2024.02.24 |
| [langchain공부]유로 임베딩 모델 사용하기!? (feat. OpenAI ada) (1) | 2024.02.13 |
| [langchain공부]Retriever의 고급기법 (feat. Ensemble, bm5,Sparse, dense) (0) | 2024.02.10 |




댓글