오늘은 langchain 의 꽃!!! RetrievalQA를 활용해보겠습니다!!
우선 이 기술은 어떨떄 활용할까요!?
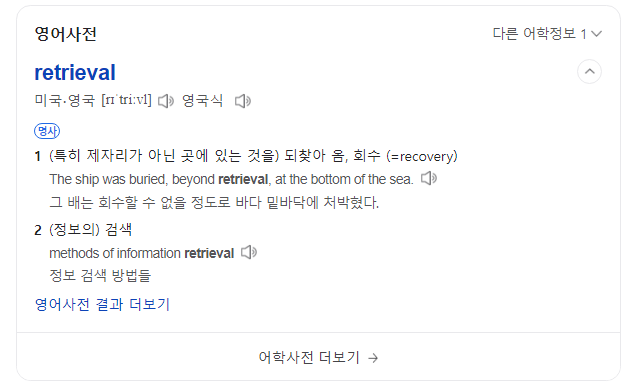
Retrieval의 뜻 자체가 검색이라는 뜻으로,
엄청 긴 PDF, html 등의 문서가 있고 그 문서에서 필요한 내용만
검색하여 추출하고싶을때!! 사용하는것인데요~!
오늘의 실습은
로블록스 하는법!! 의 웹사이트를 대상으로 진행해보겠습니다~!!
https://www.androidpolice.com/roblox-beginners-guide/
Roblox beginner's guide: How to get started exploring and creating
Curious about how to get started with Roblox? Here's a handy guide to get you on your way
www.androidpolice.com
1. 패키지 호출
> 관련된 패키지를 호출합니다!!
> 지난 포스팅의 내용(벡터화 vector store의 지식이 꼭 필요합니다!)
2024.02.05 - [일등박사의 생각/데이터&AI] - [langchain공부] Vectorstores. 벡터 저장소 (feat. Chroma, FAISS)
[langchain공부] Vectorstores. 벡터 저장소 (feat. Chroma, FAISS)
사용자가 질문하고 답하는 RAG(Retrieval Augmented Generation, 검색 증강 생성)에서는 텍스트들을 벡터호 하여 Embeding한 하는데, 이 벡터를 저장해두 공간이 필요하다!! 이때 사용되는것이 벡터저장소 (Ve
drfirst.tistory.com
import requests
import pandas as pd
from bs4 import BeautifulSoup
import tiktoken
model_option = "gpt-4"
tokenizer = tiktoken.encoding_for_model(model_option)
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_community.document_loaders import UnstructuredXMLLoader
from langchain.output_parsers import XMLOutputParser
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatAnthropic
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from transformers import BertTokenizer, BertModel
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
model_huggingface = HuggingFaceEmbeddings(model_name = "nlpaueb/sec-bert-num"
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
이에 더하여 오늘 추가되는 패키지는 아래 3개와 같습니다!@!@
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
2. html 파일 준비!!
target_url = "https://www.androidpolice.com/roblox-beginners-guide/"
res =requests.get(target_url, headers= {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36' })
with open('sample.html', 'w', encoding='utf-8') as file:
file.write(res.text)
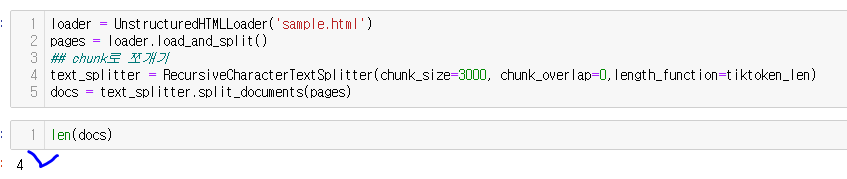
loader = UnstructuredHTMLLoader('sample.html')
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=0,length_function=tiktoken_len)
docs = text_splitter.split_documents(pages)
Target 사이트의 html 을 크롤링하여 저장하고!
langchain 내에 load 및 split 을 진행해줍니다!!
이때 chunk size는 3000토큰으로 합니다!!
3. 벡터화!!
>> 이제 확보된 docs를 hugging face의 모델을 기반으로 벡터화를 진행합니다
## Chroma 기반 pdf(docs 벡터화)
chroma_vector = Chroma.from_documents(docs, model_huggingface )
4. 질문하기!!!
로블록스의 사용법을 물어봅니다!!
question = "how to change name"
langchain의 llm 객체 만들기!!
실시간 답변을 받기 위해 callbacks의 StreamingStdOutCallbackHandler를 활용해줍니다!
openai = ChatOpenAI(model_name = 'gpt-3.5-turbo'
,api_key = "{나의 key}"
, streaming= True
, callbacks = [StreamingStdOutCallbackHandler()]
, temperature = 0 )
이제!! 오늘의 핵심!!! RetrievalQA 입니다!!
qa = RetrievalQA.from_chain_type(llm=openai
, chain_type = 'stuff'
, retriever = chroma_vector.as_retriever( search_type='mmr'
, search_kwargs = {'k':3,'fetch_k':10})
, return_source_documents = True)
result_stuff = qa(question)
result_stuff
방금 선언한 openai 객채를 llm으로서, chain_type 은 Stuff 방식으로,
검색 방식은 mmr 방식, 관련된 10개의 chunk에서(fetc_k) 3개의 결과물 (k) 을 바탕으로 답변을 할것입니다!!

짠!!! 위와 같이 결과를 잘 배출해줍니다!!!!
다음 포스팅에서는 Retrieval의 방법, chain type에 대하여 자세히 알아보겠습니다!!
오늘의 포스팅은 유튜브 모두의 AI 아래 링크를 학습한 내용을 정리하였습니다~!
좋은 강의를 제작해주신 Kane님 감사합니다!!
https://youtu.be/tQUtBR3K1TI?si=UVDQeWuD9R9XdM5C




댓글