사용자가 질문하고 답하는
RAG(Retrieval Augmented Generation, 검색 증강 생성)에서는
텍스트들을 벡터호 하여 Embeding한 하는데, 이 벡터를 저장해두 공간이 필요하다!!
이때 사용되는것이 벡터저장소 (Vectore Store)다!
> Pure Vector database : Vector형태의 값만 저장이 가능하다!! (추천)
- 업데이트 삭제 이동등 DB와 유사한 기능
>> Pinecone, Qdrant , Weaviate: 유료, 다앵한기능
>> Chrome : 무료, 오픈소수!!
> Vector Libraries :
- Vector 유사도를 계산하는 대 특화된 툴 / DB로서의 기능이 적어 유지보수가 잘 안댄다
>> FAISS : 벡터 저장, 벡터 유사도 구하기등, META에서 공개!!
Chroma의 실습 진행!!
1. 필요 패키지 설치 : 파이썬 의 필요 패키지들을 설치해 줍니다.
!pip install chromadb tiktoken transformers setence_transformers pypdf
2. 패키지 임포트
필요한 패키지들을 임포트해줍니다!
이때 저희는 텍스트 숫자가 아닌, 텍스트의 token 기반으로 진행해보가자하여
tiktoken기능을 활용, tiktoken_len함수를 만들어 token 갯수를 확인하겠습니다!
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceEmbeddings
3. pdf파일 로드 : 벡터화할 pdf파일을 로드해줍니다!
이번 포스팅에서는 삼성전자의 기업분석 pdf 를 기반으로 진행하겠습니다
https://wdr.ubion.co.kr/wowpass/img/event/gsat_170823/gsat_170823.pdf
## pdf 파일로드 하고 쪼개기
loader = PyPDFLoader('https://wdr.ubion.co.kr/wowpass/img/event/gsat_170823/gsat_170823.pdf')
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0,length_function=tiktoken_len)
docs = text_splitter.split_documents(pages)
4. 벡터화할 모델 로드
텍스트분석의 대표, huggingface의 모델을 활용할 예정입니다.
텍스트를 벡터화할 모델을 임포트해줍니다!!
from langchain.embeddings import HuggingFaceEmbeddings
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
5. Chroma 기반 대상 문서 벡터화 & 질의하기
## Chroma 기반 pdf(docs 벡터화)
db = Chroma.from_documents(docs, model_huggingface )
## 질의하기
question = '삼성전자의 주요 사업영역은?'
docs = db.similarity_search(question)
docs이제 Chroma 에,
docs 변수로로 저장된 pdf 파일을,
model_huggingface에 저장된 벡터화 모델을 통하여 저장하고!!
Question을 물어봅니다!@

그럼, 위 그림과 같이, 유사한 문장을 찾고, 해당 페이지및 소스를 알려줍니다!!
6. vectorize된 텍스트를 Chroma db 파일로 저장하기
db_toFiles = Chroma.from_documents(docs, model_huggingface, persist_directory = './samsumg.db')위 코드를 통하여, 해당 모델을 db 파일로 저장합니다!!
그럼, 해당 디렉토리에 파일이 생성됨을 확인할 수 있습니다!!

7. Chroma db 파일 읽어오기
db_fromfile = Chroma(persist_directory = './samsumg.db',embedding_function=model_huggingface)
question = '삼성전자의 주요 사업영역은?'
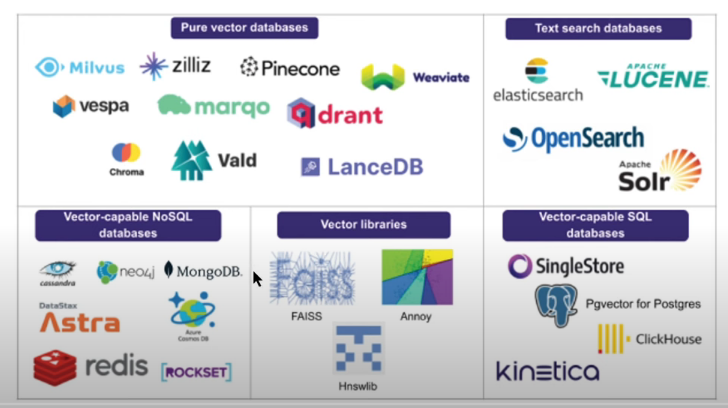
docs3 = db_fromfile.similarity_search_with_relevance_scores(question,k=3)
print(f"가장 유사한문서 : {docs3[0][0].page_content}")
print('*'*20)
print(f"문서유사도 : {docs3[0][1]}")db 파일을 읽어와서 바로 모델에 적용, 결과를 볼 수 있습니다!
FAISS의 실습 !
1. 필요 패키지 설치 : 파이썬 의 필요 패키지들을 설치해 줍니다.
!pip install faiss-cpu
2. 패키지 임포트 : Chroma와 큰차지 없습니다! FAISS불러온다는것만 다름!@
from langchain.vectorstores import FAISS
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
import tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceEmbeddings
3.마찬가지로, pdf 및 모델 로딩하기
## pdf 파일로드 하고 쪼개기
loader = PyPDFLoader('https://wdr.ubion.co.kr/wowpass/img/event/gsat_170823/gsat_170823.pdf')
pages = loader.load_and_split()
## chunk로 쪼개기
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0,length_function=tiktoken_len)
docs = text_splitter.split_documents(pages)
model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask'
, model_kwargs = {'device':'cpu'}
, encode_kwargs = {'normalize_embeddings' : True})
4. FAISS 기반으로 PDF를 벡터화하기 & 질의
db_faiss = FAISS.from_documents(docs,model_huggingface )
question = '삼성전자의 주요 사업영역은?'
docs = db_faiss.similarity_search(question)
docs
5. FAISS 파일 저장 & 불러오기
> Chroma와 근차이 없지요~! 유사하게 파일을 저장하고 불러와서 질의를 진행합니다!
# 파일저장!!
db_faiss.save_local('faiss_index')
## 파일 불러오기!!
new_db_faiss = FAISS.load_local('faiss_index', model_huggingface)
question = '삼성전자의 주요 사업영역은?'
docs_db = new_db_faiss.similarity_search(question)
docs_db
추가기능 몇가지 알아보기!!
1. max_marginal_relevance_search
- 단순 similarity_search를 진행하면, 유사한 답변만 여려개 나올 가능성이 있지요!?
- 이때, max_marginal_relevance_search를 사용하면 다양성 있는 답변을 받을 수 있습니다,
- 우선 질문에 유사한 fetch_k 개 문서를 찾고, 그중에서 lambda_multi 기반으로 다양성을 반영한 결과를 찾아줍니다!
question = 'TV사업 실적?'
## fetch_k 개 문사중에 서 찾을지 !! lambda_multi 다양셩을 중요시할지, 유사도를 중요시할지
docs_db = new_db_faiss.max_marginal_relevance_search(question, k=3,fetch_k = 10, lambda_multi = 1)
docs_db
2. similarity_search_with_relevance_scores
- 유사한 정도가 얼마인지, 지수와 함께 알고 싶을때 사용합니다!!
- 아래 이미지와 같이 검색 결과에 유사도 점수가 포함됩니다!!

오늘의 포스팅은 유튜브 모두의 AI 아래 링크를 학습한 내용을 정리하였습니다~!
좋은 강의를 제작해주신 Kane님 감사합니다!!
https://www.youtube.com/watch?v=fE4SH2vEsdk&t=67s
'데이터&AI > langchain' 카테고리의 다른 글
| [langchain공부] RetrievalQA. 긴 문서에서 원하는 답변 찾기2 (feat. stuff, map_reduce, refine, map_rerank) (0) | 2024.02.07 |
|---|---|
| [langchain공부] RetrievalQA. 긴 문서에서 원하는 답변 찾기1 (feat. RetrievalQA, 문서 검색, html) (1) | 2024.02.06 |
| [langchain공부] langchain 핵심 - 1 (체인 만들기) (0) | 2024.02.03 |
| [langchain공부] DatetimeOutputParser (datetime으로 결과도출!!) (0) | 2024.02.03 |
| [langchain공부] CommaSeparatedListOutputParser(, 결과도출!!) (0) | 2024.02.02 |




댓글