2024.10.03 - [데이터&AI/LLM] - 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM)
네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM)
Qwen 2.5 Math: 알리바바가 개발한 새로운 AI 수학 모델 소개 (24년 10월!!)최근 AI 기술의 발전과 함께, 수학 문제 해결을 위한 특화된 모델들이 속속 등장하고 있는데요~~~알리바바 그룹의 AI 연구 부서
drfirst.tistory.com
지난 포스팅에서 qwen2.5-math 모델의 수학실력을 알아보았었는데요!!
오늘은 qwen2.5 오리지날 모델을 사용해보고, 한국어 능력도 테스트해보겠습니다!
2024.06.23 - [데이터&AI/LLM] - 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력)
알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력)
여러가지 오픈소스 모델들을 알아보고있었습니다.2024.05.29 - [데이터&AI/LLM] - 내 서버에서 llama3 실행하기!! (feat. ollama) 내 서버에서 llama3 실행하기!! (feat. ollama)이전 포스팅에서 ollama를 활용하여 l
drfirst.tistory.com
과연!! 6월 공개된 qwen2 보다 한국어 실력이 좋아졌을까요!?
Qwen2.5 코드(AutoModelForCausalLM) 로 활용해보기!
지나번, 2.0 테스트와 동일하게 경량화된 모델인1.5B 모델을 활용해보겠습니다~~
| ※ 참고!! qwen2.5는 7가지의 파라미터의 모델을 공개했습니다!! 그래서!! 서버 현황에 따라 잘 골라쓸 수있겠지요? ^^ >> 7가지 파라미터 : 0.5B 1.5B 3B 7B 14B 32B 72B >> 참고 : https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e |
아래의 간단한 코드로 로딩 끝~~
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
이제!! 한국어 프롬포트를 진행해보아요!!
2.0 과 동일하게 공민왕 업적 물어보기!
prompt = "한국사의 고려 공민왕의 업적 소개해줘"
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
한국어 생성능력은 명확히 지난 모델보다 좋아졌지만,,
내용의 정확도는!! ㅎㅎ 1.5B 모델이니 이해해줘야겠어요!!

이번엔 그냥 단순 생성능력을 볼까요!?
prompt = "철수와 영희의 첫사랑 소설을 쓰고싶어. 제목이랑 목차만들어줘"소설!! 잘쓸수 이쓸까요!?ㅎㅎ

이제 결과물에 이상한 한자어나 일본어가 없이 한국어도 잘하네요~!^^
마지막으로!!
한국어 요약능력을 확인해보겠습다!
GPT가 설명해준 훈민정음 혜래본 설명을 3문장으로 요약시켜보아요~!
훈민정음 혜례본(訓民正音 解例本)은 1446년 조선 세종 대왕이 창제한 훈민정음(한글)의 원리와 사용 방법을 설명한 책입니다. 훈민정음 혜례본은 훈민정음 해례본이라고도 불리며, 이는 "훈민정음을 해설한 예시"라는 뜻으로, 한글 창제의 배경, 목적, 그리고 그 원리에 대한 상세한 설명을 담고 있습니다.
1. 훈민정음 혜례본의 구성
훈민정음 혜례본은 총 33장으로 구성되어 있으며, 크게 서문, 예의, 해례, 정인지 서문으로 나눌 수 있습니다.
서문: 세종 대왕이 훈민정음을 창제한 이유를 설명한 부분으로, 백성들이 한자를 익히기 어려운 상황에서 백성들을 교육하고 소통을 원활하게 하기 위해 훈민정음을 만들었다는 취지가 기록되어 있습니다.
예의: 훈민정음의 자음과 모음이 어떻게 만들어졌는지에 대한 기본적인 설명이 담겨 있습니다. 특히 자음은 발음 기관의 모양을 본떠 만들었고, 모음은 천(天), 지(地), 인(人)의 삼재(三才)를 상징하여 만들어졌다고 설명합니다.
해례: 훈민정음의 글자와 그 발음 원리를 세부적으로 설명한 부분입니다. 자음과 모음의 형태와 그 결합 방식, 그리고 발음의 변화를 예시와 함께 해설한 부분으로, 훈민정음의 창제 원리와 음운학적인 기초를 가장 자세히 다루고 있습니다.
정인지 서문: 세종 대왕이 훈민정음을 창제한 공적을 찬양하고, 훈민정음의 사용이 조선 사회에 미칠 긍정적 영향을 설명하는 글입니다.
2. 훈민정음 혜례본의 의의
훈민정음 혜례본은 단순히 한글의 창제만을 기록한 것이 아니라, 그 창제 원리와 과학적 구조를 명확히 설명한 최초의 문헌입니다. 이 문헌을 통해 우리는 한글이 철저한 음운학적 분석과 철학적 배경을 바탕으로 창제되었음을 알 수 있습니다.
또한, 훈민정음 혜례본은 한글의 독창성과 그 구조적 우수성을 보여주는 중요한 자료로, 특히 자음과 모음의 체계적인 구성은 오늘날에도 그 과학적 가치를 인정받고 있습니다.
3. 훈민정음 혜례본의 발견 및 보존
훈민정음 혜례본은 오랜 기간 동안 사라졌다가, 1940년에 안동의 한 농가에서 우연히 발견되었습니다. 이 책은 국보 제70호로 지정되었으며, 그 문화사적 가치는 매우 크다고 평가됩니다. 훈민정음 혜례본은 1997년 유네스코 세계기록유산으로 등재되었으며, 현재 한국의 국보로서 중요한 문화재로 보존되고 있습니다.
혜례본은 당시 발행된 원본 중 남아 있는 유일한 판본으로 알려져 있으며, 그 가치를 인정받아 전 세계적으로도 중요한 유산으로 평가됩니다.
4. 훈민정음과 현대 한글의 차이
훈민정음 혜례본에 실린 한글은 오늘날의 한글과 형태적으로는 약간의 차이가 있습니다. 창제 당시의 훈민정음은 초성과 중성(자음과 모음)뿐만 아니라 종성도 다양한 방식으로 결합할 수 있도록 설계되었으며, 현재 사용되는 일부 자음과 모음은 당시와 발음이 달랐거나 사용되지 않는 글자들도 있습니다. 하지만 그 기본적인 원리와 체계는 오늘날 한글의 기초가 되었습니다.
결론
훈민정음 혜례본은 단순한 문자 발명 이상의 가치를 지닌 문헌으로, 세종 대왕이 백성들을 위한 소통과 교육을 위해 얼마나 많은 노력과 학문적 기반을 쌓아왔는지를 보여줍니다. 한글의 창제 원리와 음운학적 구조를 기록한 이 문헌은 오늘날까지도 한글 연구의 기초 자료로 사용되며, 한국의 문화적 자부심으로 자리 잡고 있습니다.
요약결과가!!
놀라울 정도로 우수합니다!!
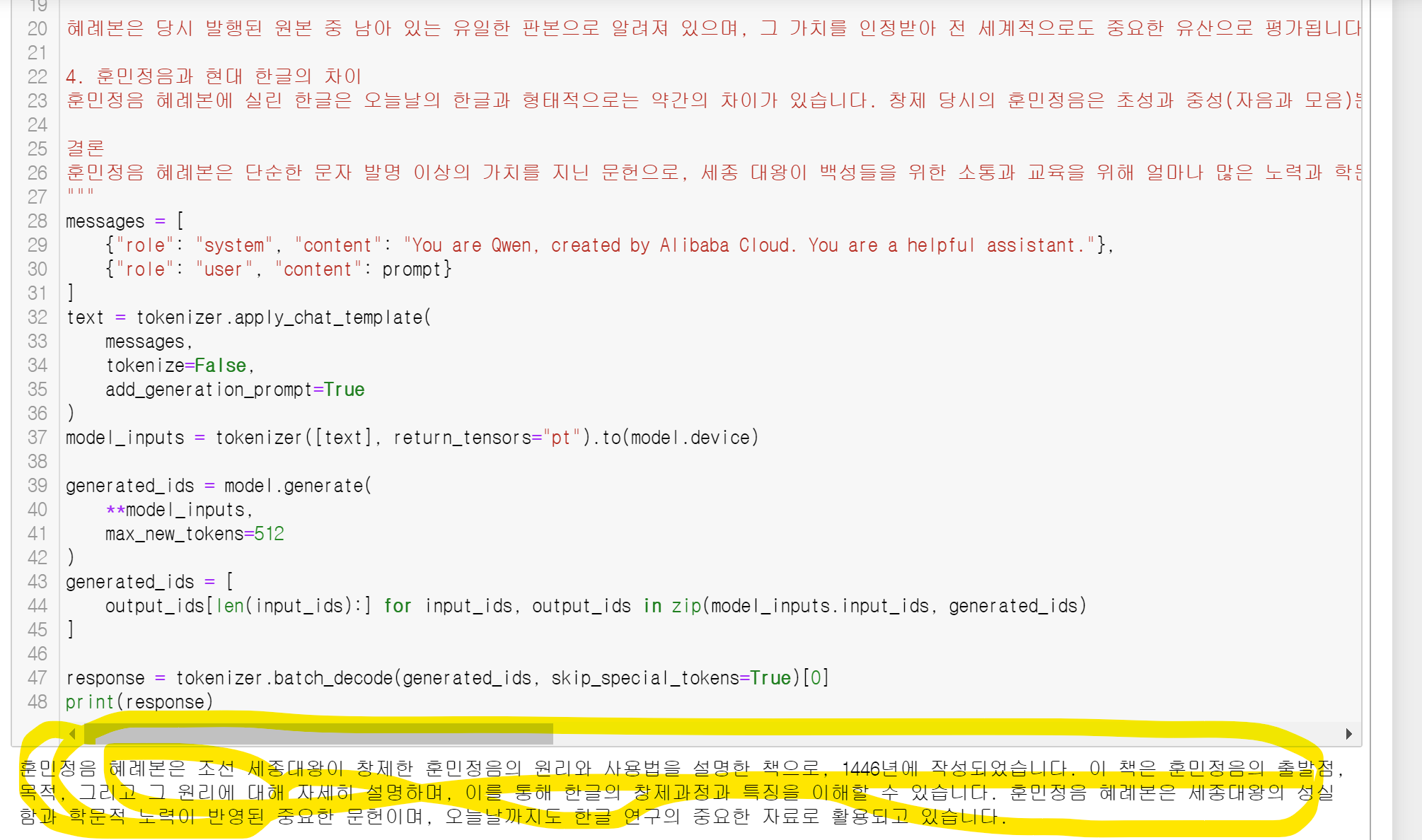
| ■ 요약결과 훈민정음 혜례본은 조선 세종대왕이 창제한 훈민정음의 원리와 사용법을 설명한 책으로, 1446년에 작성되었습니다. 이 책은 훈민정음의 출발점, 목적, 그리고 그 원리에 대해 자세히 설명하며, 이를 통해 한글의 창제과정과 특징을 이해할 수 있습니다. 훈민정음 혜례본은 세종대왕의 성실함과 학문적 노력이 반영된 중요한 문헌이며, 오늘날까지도 한글 연구의 중요한 자료로 활용되고 있습니다. |
이제!! GPU 서버만있다면,, 간단한 LLM 사용은 OpenAPI를 비싼돈 내고 안써도 되지 않을까요!?
앞으로 공개될 모델들의 성능이 얼마나 더 좋아져야할까! 싶네요 ㅎ
모델구조분석!!
이번엔 기존 2.0 모델과 구조가 어떻게 달라졌나 확인해보겠습니다!
2.5의 모델은!!
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 1536)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=1536, out_features=1536, bias=True)
(k_proj): Linear(in_features=1536, out_features=256, bias=True)
(v_proj): Linear(in_features=1536, out_features=256, bias=True)
(o_proj): Linear(in_features=1536, out_features=1536, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=1536, out_features=8960, bias=False)
(up_proj): Linear(in_features=1536, out_features=8960, bias=False)
(down_proj): Linear(in_features=8960, out_features=1536, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(lm_head): Linear(in_features=1536, out_features=151936, bias=False)
)로서!! 기존 2.0의
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 1536)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=1536, out_features=1536, bias=True)
(k_proj): Linear(in_features=1536, out_features=256, bias=True)
(v_proj): Linear(in_features=1536, out_features=256, bias=True)
(o_proj): Linear(in_features=1536, out_features=1536, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=1536, out_features=8960, bias=False)
(up_proj): Linear(in_features=1536, out_features=8960, bias=False)
(down_proj): Linear(in_features=8960, out_features=1536, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(lm_head): Linear(in_features=1536, out_features=151936, bias=False)
)
와 비교한다면!! 모두가 똑같습니다,
즉!! 2.0 과 2.5는 모델이 바뀐것은 아니며
코드 외부의 다른 요소(예: 입력 데이터, 학습된 가중치, 실행 환경 등) 등에서 변화가 일어났을것입니다!.
이후 오픈될 qwen3과 또 모델은 어떻게 다를지 비교해보겠습니다~!
'데이터&AI > LLM' 카테고리의 다른 글
| vllm 설치하고 오픈소스 모델을 openai 모듈로 써보기!(feat. 알리바바의 qwen2.5 예시!!) (0) | 2024.10.08 |
|---|---|
| LLM모델의 양자화!!(Quantization): GPTQ 및 AWQ 방식 알아보 (0) | 2024.10.07 |
| 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM) (2) | 2024.10.04 |
| LLM 모델명 이해하기! (feat. 모델명에 붙은 Instruct 가 무슨뜻이지?) (1) | 2024.10.03 |
| 구글!! 쌀아있네!! 오픈소스 gen-AI gemma2의 놀라운 한국어 실력 (feat. ollama) (2) | 2024.08.29 |



댓글