오픈 소스 LLM 서빙 소프트웨어 비교해보기!! (vLLM, Ollama, OpenLLM, LocalAI, llamafiles, GPT4All)
안녕하세요!!제 포스팅에서는 그동안 오픈소스 llm을 크게 2가지 방법으로 시도해보았었습니다~~ 1. 직접 huggingface에서 모델 다운받아 실행하기2024.06.21 - [데이터&AI/LLM] - llama3 한국어 모델 On-premis
drfirst.tistory.com
지난 포스팅에서 여러 llm 서빙 모델에 대하여 알아보았는데요!!
오늘은 이 중 하나인 vllm 을 설치하고!!
vllm의 장점인 API 제공 및 openai 모듈에 연결해서 활용하는 방법을 알아보겠습니다!!
(저는 qwen2.5로 진행했는데 만약 다를모델 [예시 : llama3] 를 사용하고싶다면
모델 부분만 "meta-llama/Meta-Llama-3-8B-Instruct" 로 바꾸어주시면 됩니다~~)

1. VLLM 설치!!
vllm을 설치해줍니다!!
pip install로 간단히 가능해요!!
(물론 transformer와,, 이를위한 pytorch가 필요하지만 이미 되어있다고 가정합니다!!)
pip install vllm
2. VLLM기반으로 qwen2.5 설치!!
vllm의 장점은 별도로 모델을 다운받을 필요없이 알아서 다 설치해둔다는것인데요!!
vllm serve Qwen/Qwen2.5-1.5B-Instruct위와 같은 방법으로 qwen2.5의 1.5B 모델을 설치해줍니다!!

그럼 끝이에요!!!
이제 활용해볼까요!??
3. python에서 API로 VLLM의 qwen2.5호출하기!
import requests
import json
# API 엔드포인트 URL
url = "http://localhost:8000/v1/chat/completions"
# 요청 헤더
headers = {
"Content-Type": "application/json"
}
# 요청 데이터
data = {
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": "너는 어떤 모델인지 소개해줘."}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}
# POST 요청 보내기
response = requests.post(url, headers=headers, data=json.dumps(data))
# 응답 출력
if response.status_code == 200:
print(response.json())
else:
print(f"Error: {response.status_code}, {response.text}")
위와같이 localhost의 8000번 포트로 호출해준다면!?
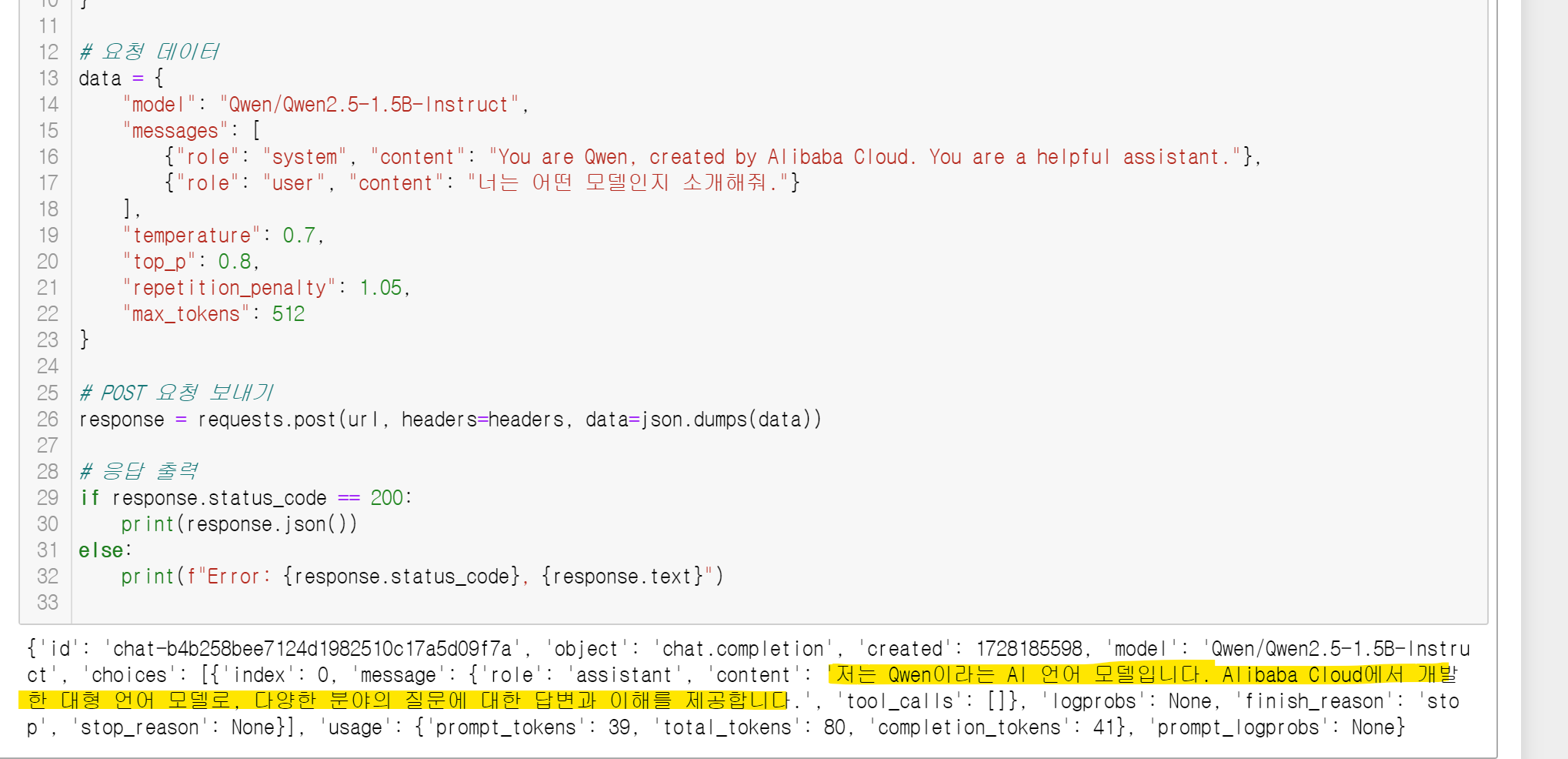
아~~주 잘 답변해줍니다!!
아!! 포트를 바꾸고 싶다면??
vllm serve --model {모델명} --port {포트번호}
로 포트번호를 직접 설정해주면 됩니다!! default는 8000이구요!
4. python의 openai 패키지로 VLLM의 qwen2.5호출하기!
만약 여러분이 기존 openai 패키지로 GPT api를 호출중이었느데,
그것을 그대로 모델만 변경해서 가고싶다면??? 가능합니다!!
openai의 패키지를 활용해서 아래와 같이 진행해주면 됩니다~!
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-1.5B-Instruct",
messages=[
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": "vllm에 대하여 소개해줄래?"},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
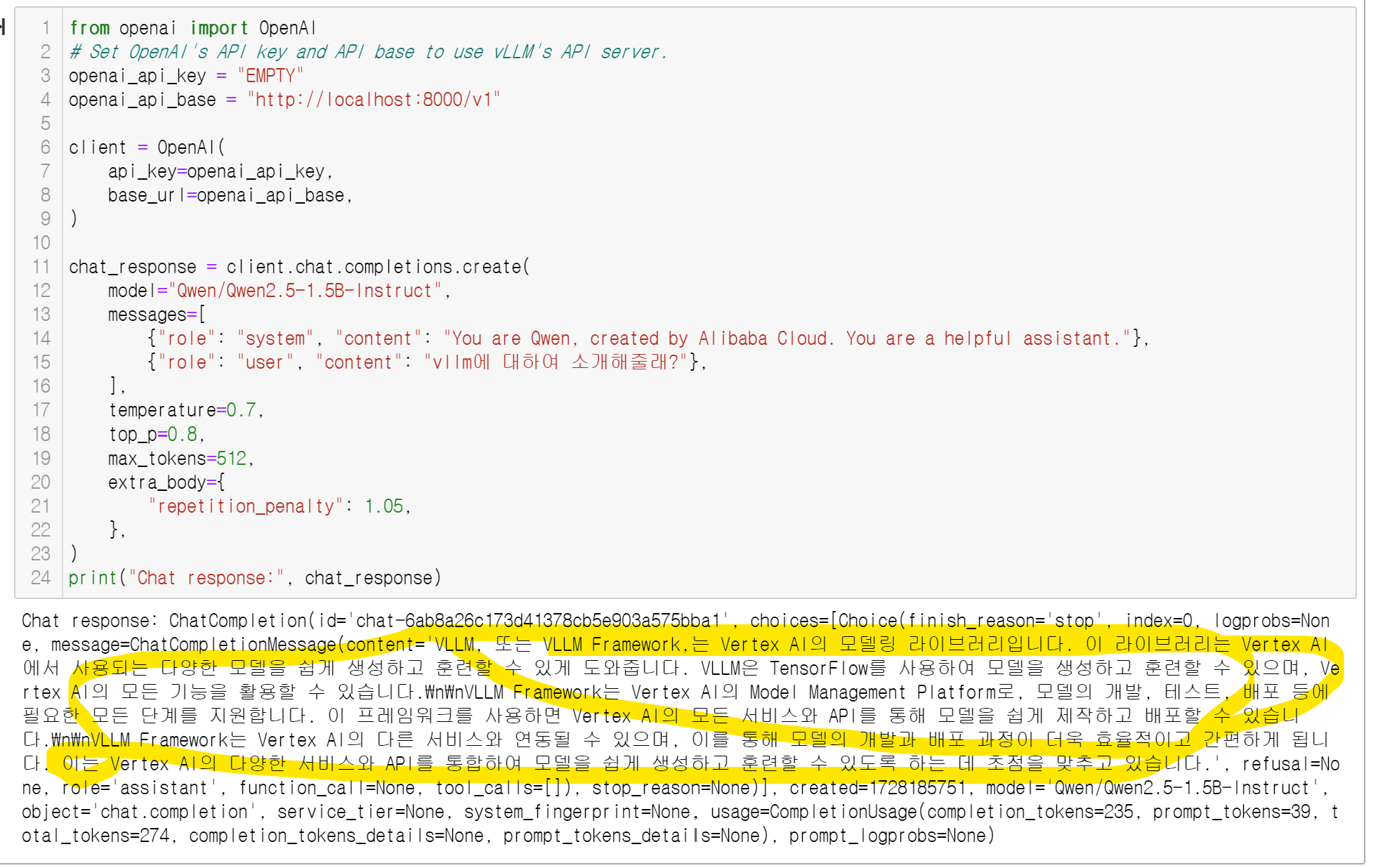
print("Chat response:", chat_response)
그럼!! 아주 우수하죠~?!^^
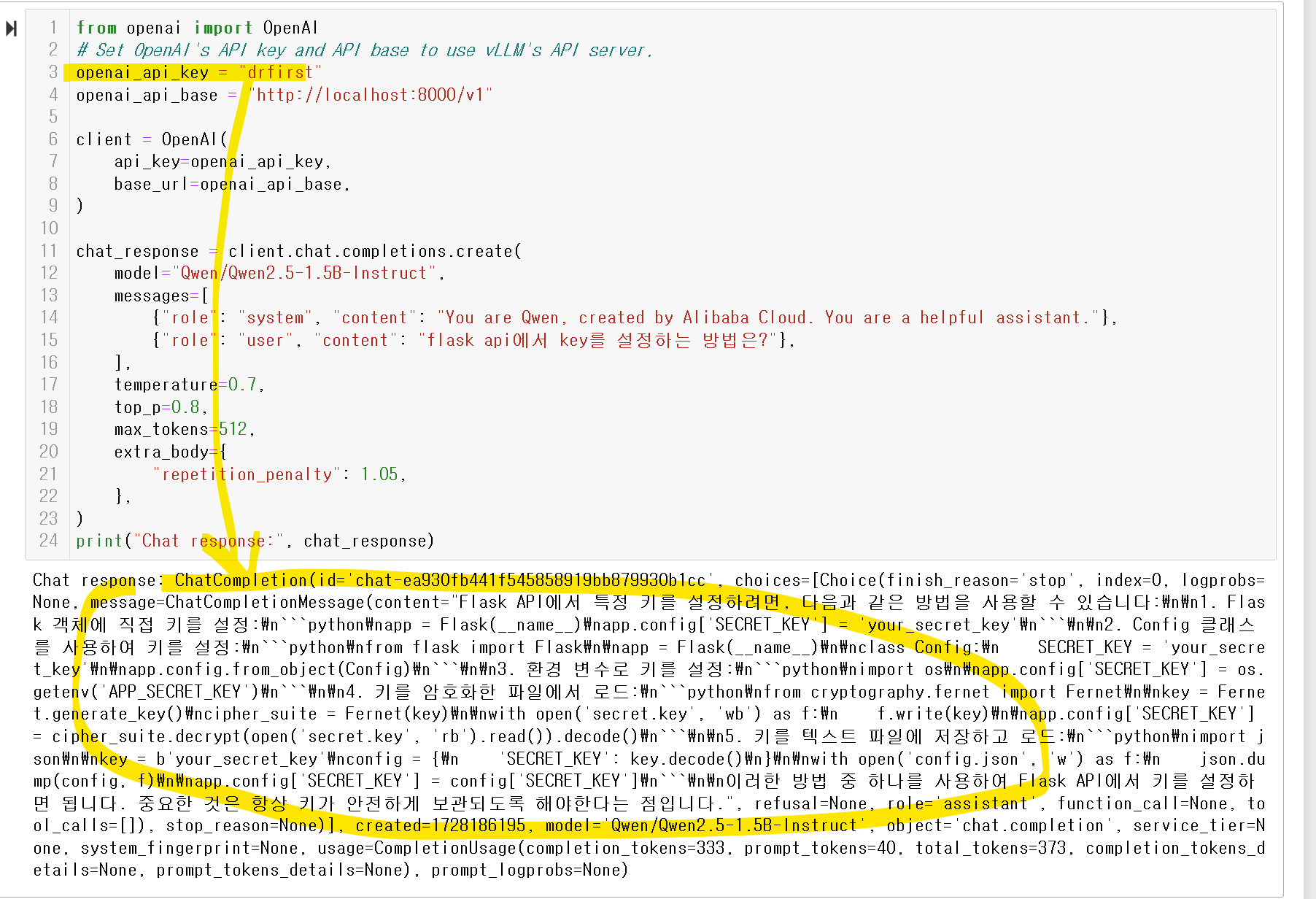
그런데!! openai_api_key = "EMPTY" 가 신경쓰이시나요? 나만의 키를 만들어 서빙하고싶다면!?
모델을 실행할떄!! 아래와 같이 해주시면 됩니다~!!
vllm serve Qwen/Qwen2.5-1.5B-Instruct --api-key {내가설정하고싶은KEY}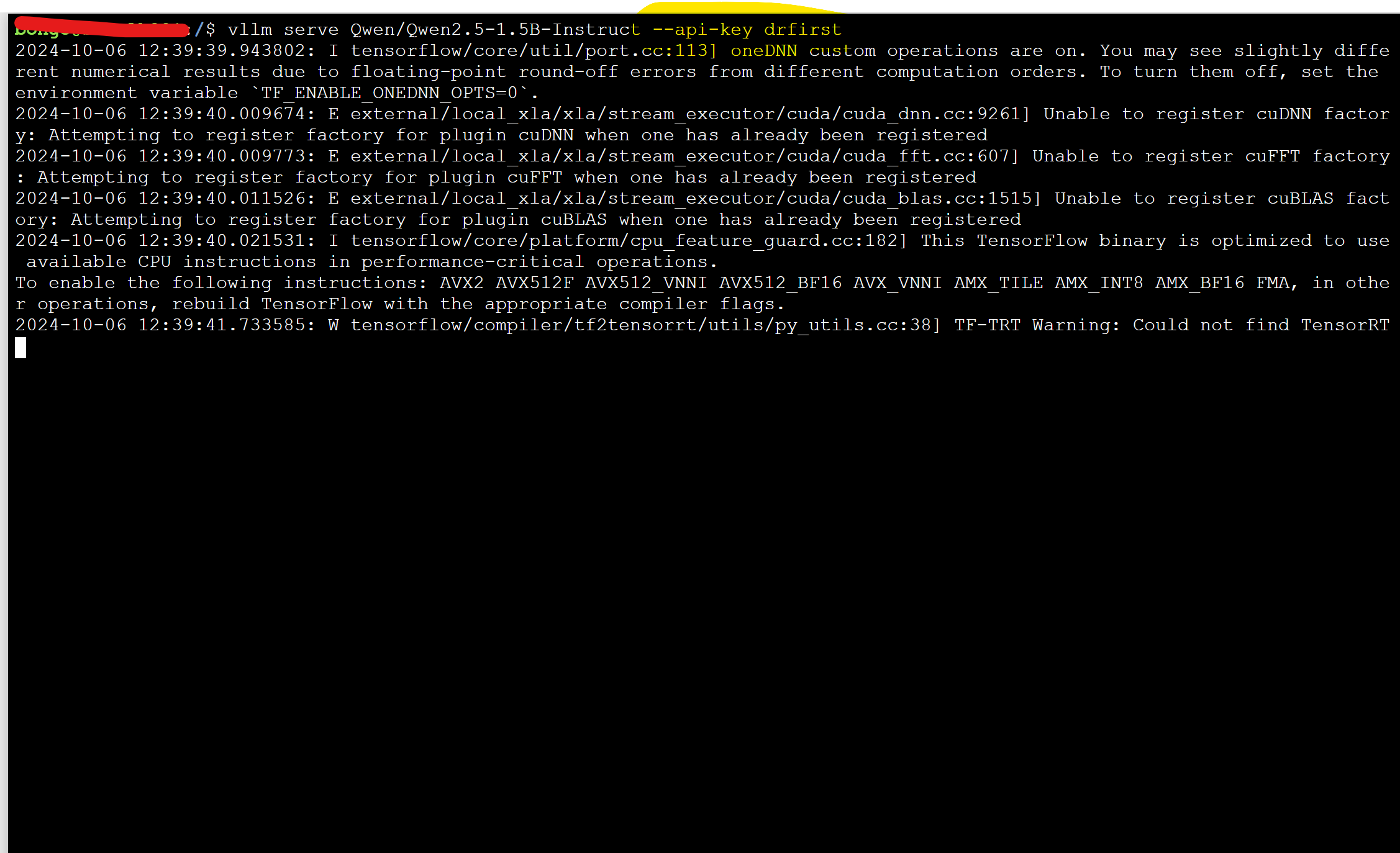
그리고 나면!!?
KEY값이 들리면
아래와 같이 API ERROR가 나오고~~
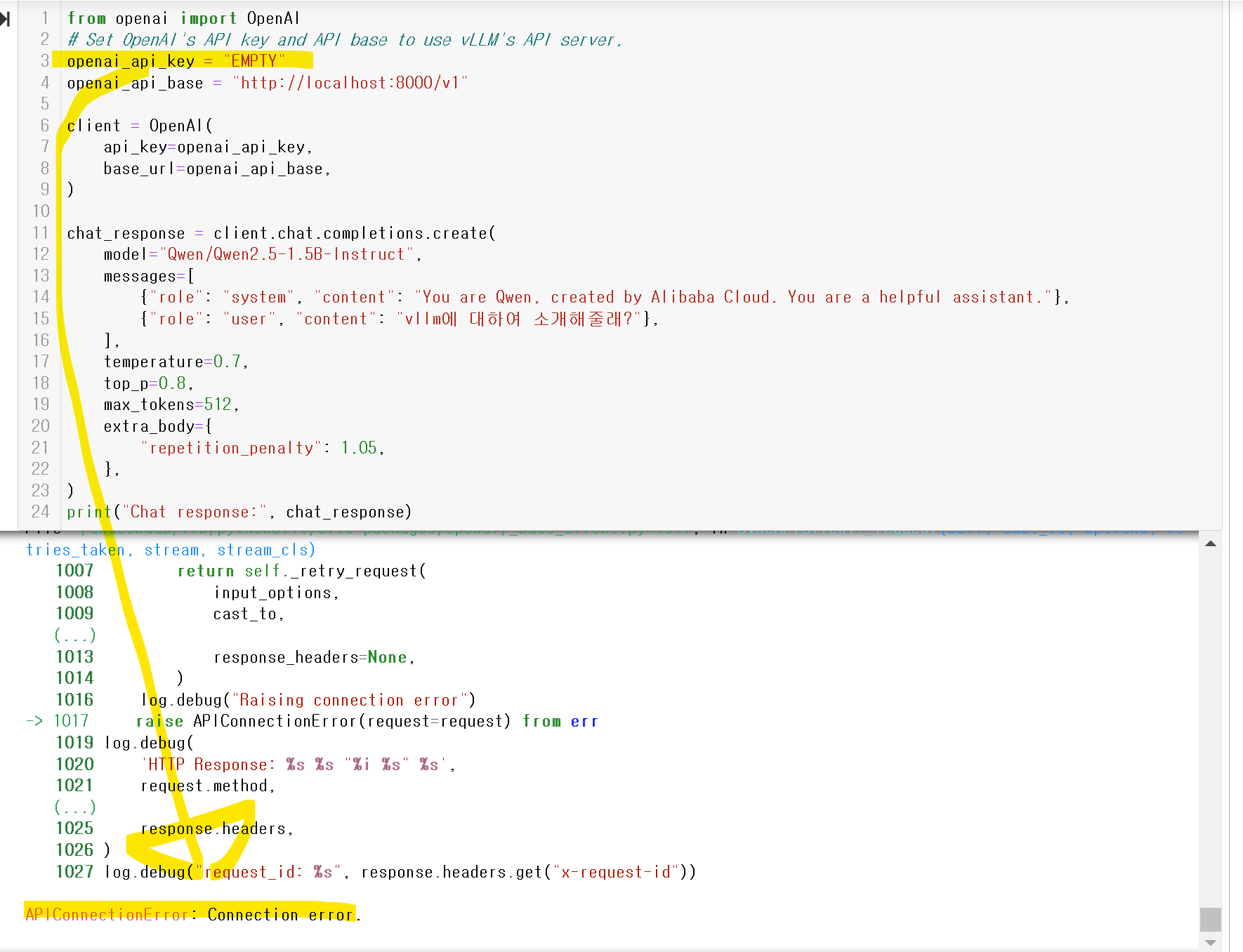
맞을경우에만 작동합니다!!^^
ㅁ 참고 : https://docs.vllm.ai/en/stable/getting_started/installation.html
ㅁ 참고2 : https://github.com/QwenLM/Qwen2.5?tab=readme-ov-file
'데이터&AI > LLM' 카테고리의 다른 글
| llama3.2 체험하기 (feat. ollama) + 한국어는,, 언제쯤?! (8) | 2024.10.11 |
|---|---|
| 내 컴퓨터에서 llm으로 이미지를 분석해 보쟈! (feat. qwen2-VL) (4) | 2024.10.10 |
| LLM모델의 양자화!!(Quantization): GPTQ 및 AWQ 방식 알아보 (0) | 2024.10.07 |
| Qwen2.5를 사용해보기!!! (feat 한국어실력 확인!! qwen2와의 비교 ) (4) | 2024.10.06 |
| 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM) (2) | 2024.10.04 |




댓글