지난 포스팅에서는!! ollama로 올라간 llama를
shell 환경에서 진행해보았는데요!!
2024.05.29 - [데이터&AI/LLM] - 내 서버에서 llama3 실행하기!! (feat. ollama)
내 서버에서 llama3 실행하기!! (feat. ollama)
이전 포스팅에서 ollama를 활용하여 llama2-uncencored 모댈을 활용해보았고,airllm을 활용하여 llama3 모델을 활용해보았는데요!! 이번에는 ollama를 활용하여 llama3를 사용해보겠습니다!! 1. ollama 실행!! -
drfirst.tistory.com
이번에는 API를 호출하는 방법으로 해당 모델을 사용해보겠습니다!!
1. ollama모델 구동
- 기존과 동일하게, 서버에서 ollama를 우선 구동시킵니다!!
OLLAMA_MODELS={모델의 위치} ollama serve
2. python에서 API 호출 (generate)
ollama를 실행하면 ㅣlocalhost의 11434 포트에 오픈이 됩니다!!
이에 아래와 같이 api를 호출하면, 그결과물을 받을수 있습니다!!
import requests
import json
url = "http://localhost:11434/api/generate"
data = {
"model": "llama3",
"prompt": "대한민국의 역대 왕조를 소개해줄래?"
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
print('Success')
else:
print("Error:", response.status_code, response.text)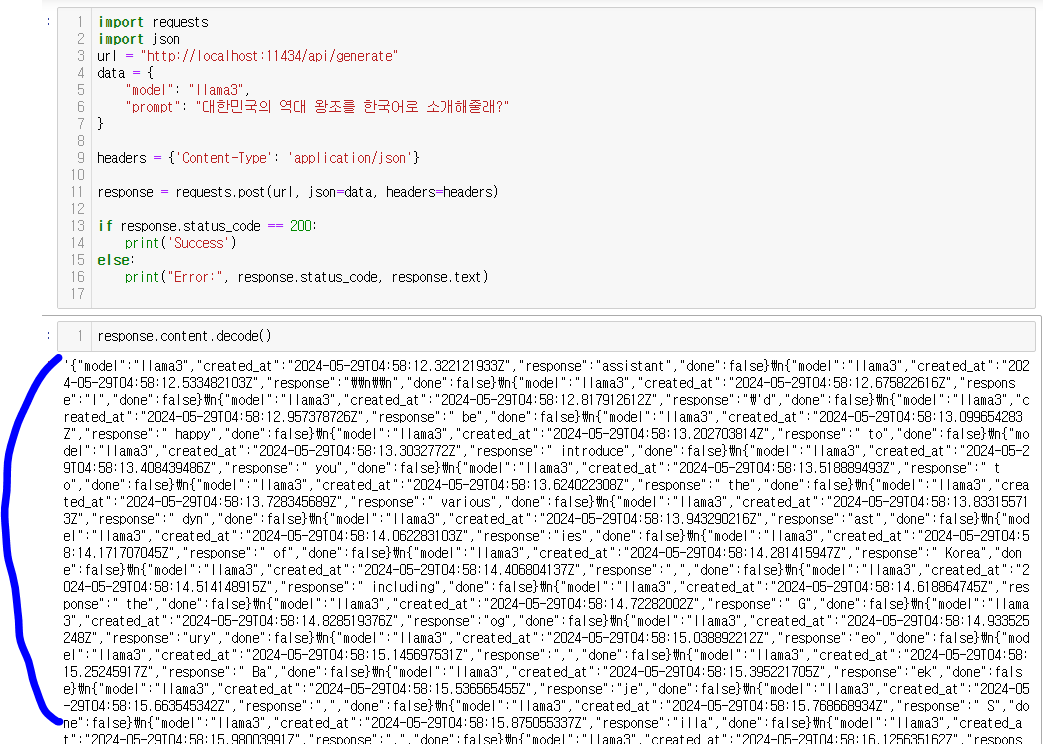
3. 결과물 parsing!!
- 코드를 실행한 결과물은 위 이미지와 같이 지저분한 텍스트형식으로 return 되는데요~~
간단한 python 로 이결과물을 깔끔하게 정리해봅니다~~
# 개별 JSON 객체로 분할
json_objects = response.content.decode().strip().split("\n")
# 각 JSON 객체를 Python 사전으로 변환
data = [json.loads(obj) for obj in json_objects]
res_text = ''
# 변환된 데이터 출력
for item in data:
print(item)
res_text += item['response']
print(res_text)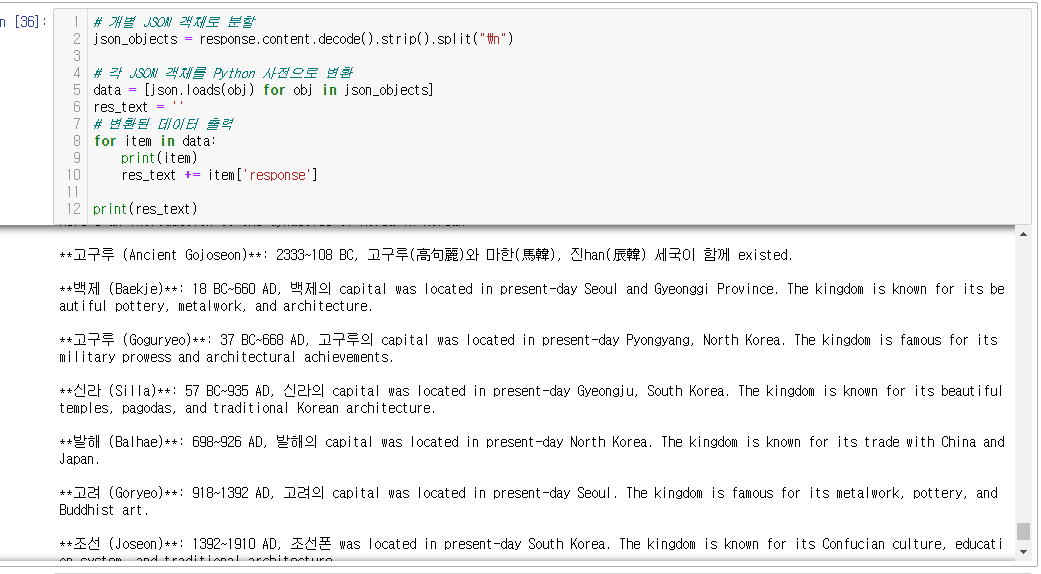
+python에서 API 호출(chat) - openAI와 유사하게 채팅모드로 호출도됩니다!!
아래 코드와 같이 메세지를 user, assistant로 나누어 진행하게되지요~~
import requests
import json
url = "http://localhost:11434/api/chat"
headers = {'Content-Type': 'application/json'}
data = {
"model": "llama3",
"messages": [
{
"role": "user",
"content": "why is the sky blue?"
}
]
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
# result = response.json()
print("Success") # Assuming the API returns the answer in JSON
else:
print(f"Request failed with status code: {response.status_code}")
그리고 데이터 파싱을 하면!?
# 개별 JSON 객체로 분할
json_objects = response.content.decode().strip().split("\n")
# 각 JSON 객체를 Python 사전으로 변환
data = [json.loads(obj) for obj in json_objects]
res_text = ''
# 변환된 데이터 출력
for item in data:
print(item)
res_text += item['message']['content']
print(res_text)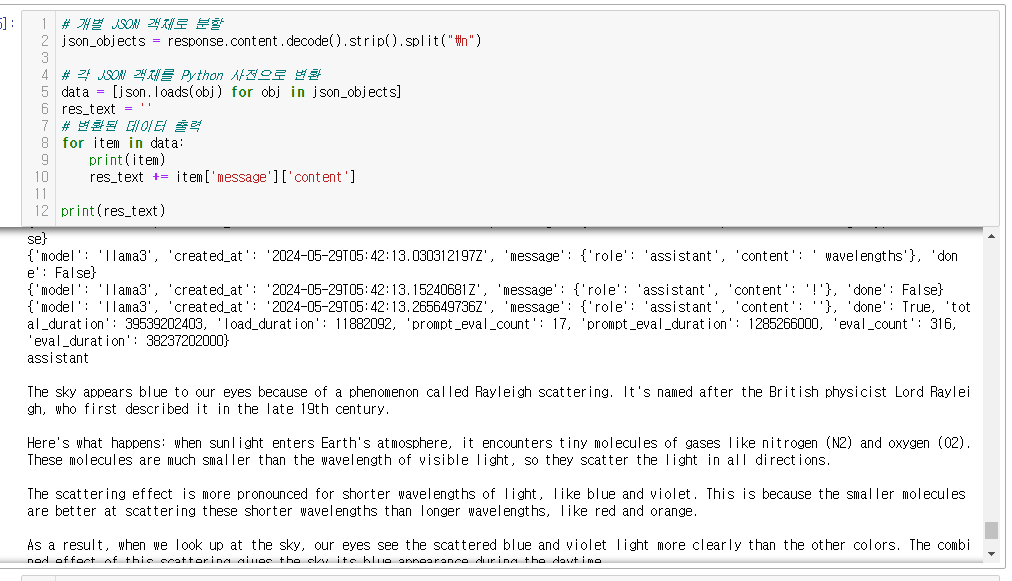
+ sentence embedding이 가능합니다!
hugginggace의 모델기반의 embedding이 이 ollama기반의 api에서도 가능합니다!@
코드를 함께 보아요!
import requests
import json
url = "http://localhost:11434/api/embeddings"
data = {
"model": "llama3",
"prompt": "Why is the sky blue?"
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
print('Success')
else:
print("Error:", response.status_code, response.text)
위 코드를 실행시키면!! 4096개의 vector를 지닌 행렬로 변환해줍니다!

ㅁ 참고 : https://github.com/ollama/ollama/blob/main/docs/api.md
ollama/docs/api.md at main · ollama/ollama
Get up and running with Llama 3, Mistral, Gemma, and other large language models. - ollama/ollama
github.com
'데이터&AI > LLM' 카테고리의 다른 글
| Solar 오픈소스 모델 활용해서 ON-premise LLM 만들기 (0) | 2024.06.13 |
|---|---|
| [STT] 녹음파일에서 텍스트 추출하기!! by OpenAI Whisper(feat python) (0) | 2024.06.08 |
| 내 서버에서 llama3 실행하기!! (feat. ollama) (0) | 2024.05.31 |
| 지금시간 맞추는 GPT 만들기 (feat. function calling) (0) | 2024.05.30 |
| LLM 에이전트(llm agent) 란 무엇일까?- 코드로 알아보기 (feat. prompt engineering) (0) | 2024.05.29 |




댓글