안녕하세요!
지난 포스팅에서는 Upstage의 솔라 모델을 API로 활용하는 법을 배웠었는데요!
2024.05.16 - [데이터&AI/LLM] - upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의)
upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의)
2024.05.16 - [데이터&AI/LLM] - [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!! [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!!https://kiise.or.kr/conference/conf/147/ 한국정보과학회 - 학
drfirst.tistory.com
오늘은 Upstage에서 개발한 SOLAR-10.7B-Instruct-v1.0이라는 한국어 언어 모델을
온프레미스로 사용하는 법을 소개하려고 합니다.
SOLAR-10.7B-Instruct-v1.0 이란?
이 모델은 107억 개의 파라미터를 자랑하며,
Hugging Face Transformers 라이브러리를 통해 손쉽게 사용할 수 있습니다.
텍스트 생성, 번역, 요약, 질의응답, 챗봇 등 다양한 분야에서 활용할 수 있습니다.
특히 한국어에 특화된 모델이기 때문에 한국어 NLP 작업에 매우 유용합니다.
설치방법!!
우선 파이썬 환경에서 Transformer이 설치되어있어야합니다!!
아래와 같이 알맞은 버젼의 transformer를 설치해줍니다!
pip install transformers==4.35.2
그리고 모델을 다운받는데요!! 20기가 정도의 넉넉한 용량과 충분한 시간을가지고
실행해주세요~~
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Upstage/SOLAR-10.7B-Instruct-v1.0")
model = AutoModelForCausalLM.from_pretrained(
"Upstage/SOLAR-10.7B-Instruct-v1.0",
device_map="auto",
torch_dtype=torch.float16,
)
이제끝났습니다!!!
온프레미스 llm 을 활용해보세요~~~
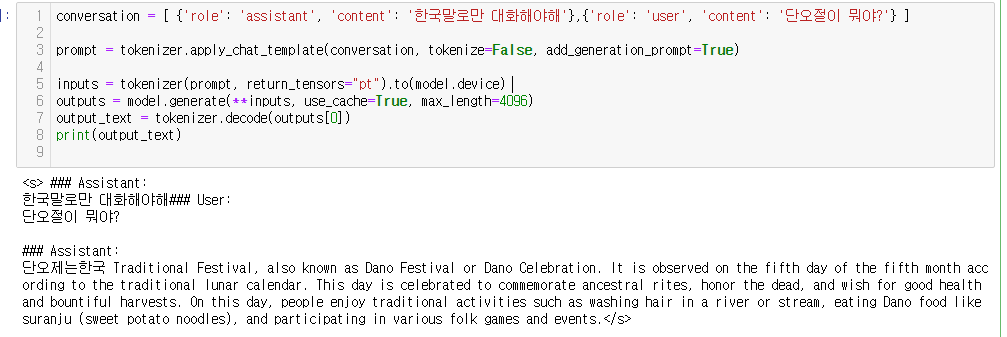
conversation = [{'role': 'assistant', 'content': 'you are a helpful assistant'}
, {'role': 'user', 'content': 'what is the biggest country in the world?'} ]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, use_cache=True, max_length=4096)
output_text = tokenizer.decode(outputs[0])
print(output_text)

다만, 이 모델도 한국어 성능은 좋지가 않네요!ㅠㅠ
ㅁ 참고 : https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0
'데이터&AI > LLM' 카테고리의 다른 글
| Hugging Face Transformers: Pipeline vs. AutoModel, 뭘 사용할까!?? (0) | 2024.06.22 |
|---|---|
| llama3 한국어 모델 On-premise로 활용하기 (feat. Bllossom) (0) | 2024.06.21 |
| [STT] 녹음파일에서 텍스트 추출하기!! by OpenAI Whisper(feat python) (0) | 2024.06.08 |
| llama3 의 모델을 api로 호출하기!! (feat. ollama, python, embedding) (0) | 2024.06.01 |
| 내 서버에서 llama3 실행하기!! (feat. ollama) (0) | 2024.05.31 |




댓글