지난 포스팅 까지 RetrievalQA를 활용하여 긴 문서에서 답변찾기 실습,
[langchain공부] Retriever. 긴 문서에서 원하는 답변 찾기1 (feat. RetrievalQA, 문서 검색, html)
오늘은 langchain 의 꽃!!! Retriever를 활용해보겠습니다!! 우선 이 기술은 어떨떄 활용할까요!? Retrieval의 뜻 자체가 검색이라는 뜻으로, 엄청 긴 PDF, html 등의 문서가 있고 그 문서에서 필요한 내용만
drfirst.tistory.com
답변 찾는 방식의 체인 타입(Chain type) 에 대한 이해를 진행해보았습니다!
[langchain공부] Retriever. 긴 문서에서 원하는 답변 찾기2 (feat. stuff, map_reduce, refine, map_rerank)
지난 포스팅에서 RetrievalQA 함수 사용하는 방법을 알아보았습니다!! 2024.02.06 - [일등박사의 생각/데이터&AI] - [langchain공부] Retriever. 긴 문서에서 원하는 답변 찾기1 (feat. RetrievalQA, 문서 검색, html) [l
drfirst.tistory.com
이번포스팅에서는 이에이어서!!
RetrievalQA 가 기존 chunk를 검색함에 있어서의 검색 타입
즉, Search_type 에 대하여 알아보겠습니다!!!
qa = RetrievalQA.from_chain_type(llm=llm_openai4
, chain_type = 'map_reduce' # dict_keys(['stuff', 'map_reduce', 'refine', 'map_rerank'])
, retriever = db_fromfile.as_retriever( search_type='mmr'
, search_kwargs = {'k':3,'fetch_k':10})
, return_source_documents = True)
result_stuff = qa(question)
result_stuff
지난포스팅에서 알아보았던 코드를 먼저 보곘습니다!!
오늘 알아볼 부분은!! 여기서 의 SEARCH_TYPE 부분입니다!!
위 코드는 mmr로 설정된 것이겠찌요!?
현재시점으로,
위 Type에 설정 가능한 옵션은 아래의 네가지인데요!!
similarity, mmr, similarity_score_threshold,hybrid
각각의 의미를 알아봅시다!!
1. "similarity" : 유사도 중시 (default 값)
- 벡터 공간에서 쿼리 벡터와 문서 벡터의 유사도를 기반으로 순위 산정
- 가장 유사한 문서가 먼저 반환
- search_kwargs={"k": 1} 의 방식으로 검색 대상 갯수 설정 가능!!
- search_kwargs={"filter": {"tags": ["news"]}} 를 통해서 특정 필터 적용 가능!!
2. "mmr" (Maximum Marginal Relevance): 다양성 중시
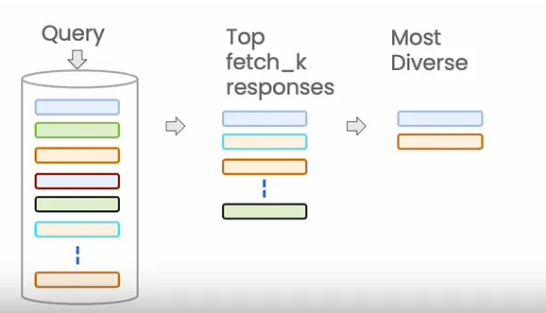
- 관련성과 다양성을 모두 고려하여 순위 선정
- 먼저 가장 관련성이 높은 문서를 선택한 후, (이후 선택되는 문서는 이전 문서들과의 유사도를 고려하여) 유사도가 먼, 즉 다양성이 보장된 답변들을
- 이를 통해 검색 결과에 다양한 정보가 포함
- search_kwargs = {'k':3,'fetch_k':10} 으로
- fetch_k는 similarity 방식으로 먼저 탐색 대상 후보군을 정한 뒤 (여기서는 10개)
- 그중 가장 다양성이 잘 보존 된 방식으로3개의 답변을 선정!!
3. "similarity_score_threshold" : 유사도 중시 + 사용자 임계값 반영
- 유사도 점수 임계값을 설정, 임계값 이상의 점수를 가진 문서만 반환
- 쿼리와 관련성이 낮은 문서를 제외,검색 결과의 정확도 향상
- search_kwargs={"score_threshold": 0.5} 의 방식을 통하여 임계값 설정
4. "hybrid" : 하이브리드. 짬뽕
- "similarity"와 "mmr"을 함께 사용하여 순위 산정
- 초기 결과에는 "similarity"를 사용하여 관련성이 높은 문서를 우선적으로 표시
- 이후 "mmr"을 사용하여 다양한 정보를 제공
개인적 선호도는!!? 다양성이있는 MMR을 선호합니다~!^^
다양한 답변을 여러개 받아서 마지막에 GPT가 정리해주니, 제일 이쁜것 같다는 짧은 경험의 결론이었습니다!
코드별 예시
# 유사도 기반 검색
retriever = db.as_retriever(search_type="similarity")
# MMR 기반 검색
retriever = db.as_retriever(search_type="mmr")
# 상위 5개 문서만 반환
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 5})
# 특정 태그를 가진 문서만 반환
retriever = db.as_retriever(search_type="similarity", search_kwargs={"filter": {"tags": ["news"]}})
# 유사도 점수 0.8 이상의 문서만 반환
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.8})
참고
- Vector store-backed retriever: https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore%EF%BB%BF




댓글