지난 포스팅에서 RetrievalQA 함수 사용하는 방법을 알아보았습니다!!
[langchain공부] Retriever. 긴 문서에서 원하는 답변 찾기1 (feat. RetrievalQA, 문서 검색, html)
오늘은 langchain 의 꽃!!! Retriever를 활용해보겠습니다!! 우선 이 기술은 어떨떄 활용할까요!? Retrieval의 뜻 자체가 검색이라는 뜻으로, 엄청 긴 PDF, html 등의 문서가 있고 그 문서에서 필요한 내용만
drfirst.tistory.com
그런데!! 이 중 chain type 을 간단히 넘어갔었는데,
이 체인 타입에 관하여 4가지 를 공부해보겠습니다!!
0. 기본 체인 유형: stuff
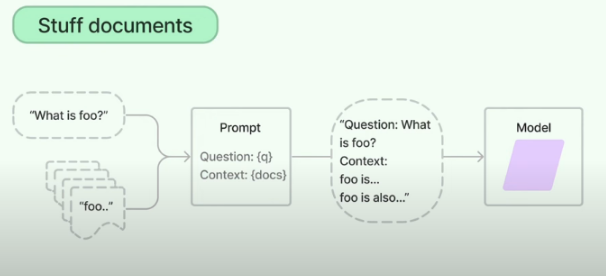
> 기본 체인 유형인 stuff는 모든 텍스트를 하나의 단위로 묶어서 LLM에 전달
> 모든 텍스트를 한 번에 처리, 텍스트의 양이 많지 않은 경우 유용
> 텍스트의 양이 많아질 경우, 최대 토큰 제한을 초과하게 되어 오류가 발생 or 처리 속도 느려지는 단점.
1. map_reduce (맵리듀스 방식)
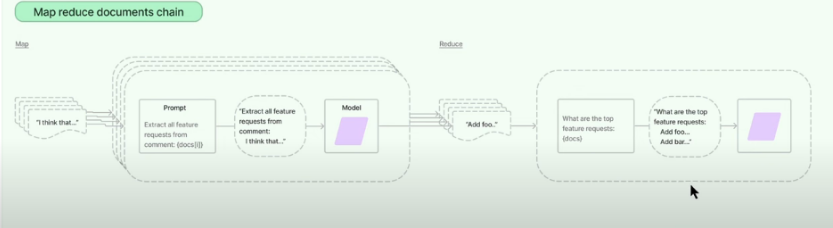
- 텍스트를 여러 개의 배치로 나누어 LLM에 전달
- 각 배치에 대한 LLM의 응답을 취합, 최종 결과 도출
- 대용량 텍스트를 처리할 때 유용, 처리 속도와 효율성을 높일 수 있습니다.
- 다만, LLM을 많이 돌리니 시간이 오래 걸리며 고비용
2. refine (정제)
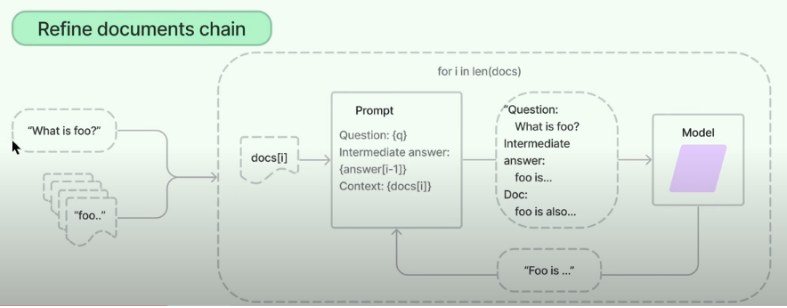
- 텍스트를 여러 개의 배치로 나누어 순차적으로 LLM에 전달.
- (예시) 질문 + chunk1 = 답변1 >> 질문1 + 답변1 + chunk2 =답변2 >> 질문1 + 답변12+ chunk3 로 쭉 누적해서!!
- 이전 배치의 응답을 다음 배치와 함께 LLM에 전달, 응답을 점진적으로 개선
- 텍스트 간의 연관성이 높고, 단계적인 처리가 필요한 경우에 적합
- (장점)답변의 신뢰성이 필요할떄 사용
- (단점) 시간이 오래걸리며 비용이 높다
3. map-rerank
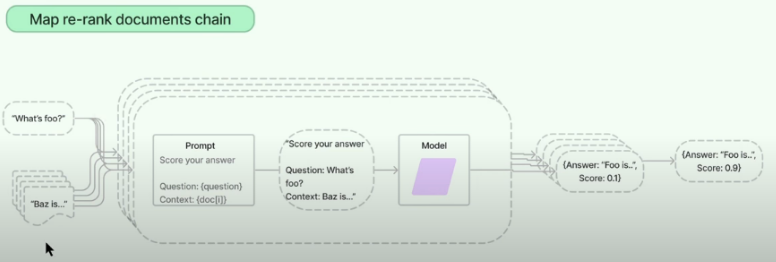
- 텍스트를 여러 개의 배치로 나누어 LLM에 전달
- 사용자가 질문한거에 각각의 답변을 생성 (map reduce 유사)
- 차이점은!? 답변에 score도 받음 (score는 질문과 답변과의 유사도로 산출)
- 질문에 대한 높은 유사도의 답변이 필요할때 사용!!
적절한 체인 유형 선택하기
텍스트의 양, 텍스트 간의 연관성, 원하는 처리 방식 등을 고려하여 적절한 체인 유형을 선택하는 것이 중요합니다.
- 대용량 텍스트를 처리하거나, 처리 속도와 효율성을 높이고 싶은 경우에는 map_reduce 체인 유형을 활용
- 텍스트 간의 연관성이 높고, 단계적인 처리가 필요한 경우에는 refine 체인 유형을,
- 텍스트 내에 여러 개의 답변이 존재할 수 있는 경우, map-rerank 체인 유형을 사용하는 것이 효율적입니다.
코드실습
.
어렵지 않습니다!! 단지, chain_type에
['stuff', 'map_reduce', 'refine', 'map_rerank'] 4가지 중 한가지를 선택하여 넣으면 됩니다~!!
qa = RetrievalQA.from_chain_type(llm=llm_openai4
, chain_type = 'map_reduce' # dict_keys(['stuff', 'map_reduce', 'refine', 'map_rerank'])
, retriever = db_fromfile.as_retriever( search_type='mmr'
, search_kwargs = {'k':3,'fetch_k':10})
, return_source_documents = True)
result_stuff = qa(question)
result_stuff
ㅁ 참고1 : https://towardsdatascience.com/4-ways-of-question-answering-in-langchain-188c6707cc5a
4 Ways to Do Question Answering in LangChain
Chat with your long PDF docs: load_qa_chain, RetrievalQA, VectorstoreIndexCreator, ConversationalRetrievalChain
towardsdatascience.com
ㅁ참고2 : https://www.youtube.com/watch?v=tQUtBR3K1TI&t=26s
['stuff', 'map_reduce', 'refine', 'map_rerank'])
, retriever = db_fromfile.as_retriever( search_type='mmr'




댓글