1년도 전에 (벌써!!..) GPT의 fine-tuning의 내용을 포스팅한적이 있었습니다!!
2023.03.04 - [데이터&AI] - Python API를 활용하여 OpenAI 교육(파인튜닝, Fine tuning)하기
Python API를 활용하여 OpenAI 교육(파인튜닝, Fine tuning)하기
안녕하세요!!!! 최근 OpenAI에서 새로운 GPT 모델인 gpt-3.5-turbo를 출시하였습니다!! 하지만 아쉽게도 GPT를 교육할 수 있는 fine-tuning 모델은 아직 기존 모델로만 가능한데요~! 이번 포스팅에서는 python
drfirst.tistory.com
이때는, gpt-3.5-turbo의 시대로!! babbage002 와 davinci와 같은 임베딩 모델로만 가능했었는데요!
시간이 많이흘러 이제는!! 많은 모델들이 추가되었습니다!!

거기다 파인 튜닝을 위한 데이터 양식, 방법 들도 달라졌기에!!
오늘은 그 방법에 대하여 알아보겠습니다~~
0. 목적!!
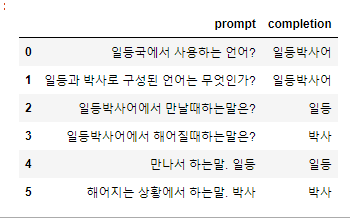
저는 일등박사의 인사말을 학습시켜보고자합니다!!
이에 아래 내용을 학습시켜볼것 입니다!!
1. 데이터 준비하기!!
- 공식 사이트에서는 아래와 같은 new의 데이터 형식으로 사용해야한다고 나와있습니다

이에, 제가 가지고있는 df를 바꾸어보아요!!
df = pd.DataFrame({
'questions':['일등국에서 사용하는 언어?','일등과 박사로 구성된 언어는 무엇인가?','일등박사어에서 만날때하는말은?','일등박사어에서 해어질때하는말은?','만나서 하는말. 일등','해어지는 상황에서 하는말. 박사','일등박사어는 무엇인가?','일등박사어는 무엇인가?','일등','박사'],
'answers':['일등박사어','일등박사어','일등','박사','일등','박사','일등국이서 사용하는 언어입니다','일등과 박사로 구성된 언어입니다','일등','박사'],
})
df_gpt = df[['questions','answers']]
df_gpt.columns = ['prompt','completion']
df_gpt
# Converting to the specified JSON format
formatted_data = [
{
"messages": [
{"role": "system", "content": "너는 일등박사어를 알려주는 선생님이아"},
{"role": "user", "content": row['prompt']},
{"role": "assistant", "content": row['completion']}
]
}
for _, row in df_gpt.iterrows()
]
# Print each formatted JSON entry
for entry in formatted_data:
print(entry)
만들어진!! openai의 양식에 맞춘 데이터입니다!
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '일등국에서 사용하는 언어?'}, {'role': 'assistant', 'content': '일등박사어'}]}
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '일등과 박사로 구성된 언어는 무엇인가?'}, {'role': 'assistant', 'content': '일등박사어'}]}
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '일등박사어에서 만날때하는말은?'}, {'role': 'assistant', 'content': '일등'}]}
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '일등박사어에서 해어질때하는말은?'}, {'role': 'assistant', 'content': '박사'}]}
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '만나서 하는말. 일등'}, {'role': 'assistant', 'content': '일등'}]}
{'messages': [{'role': 'system', 'content': '너는 일등박사어를 알려주는 선생님이아'}, {'role': 'user', 'content': '해어지는 상황에서 하는말. 박사'}, {'role': 'assistant', 'content': '박사'}]}
이제 json으로 저장합니다!
import json
# formatted_data를 JSONL 파일로 저장하는 코드
with open('drfirst_language.jsonl', 'w') as f:
for entry in formatted_data:
f.write(json.dumps(entry) + "\n")
2. openai 패키지로 파일 올리고 학습하기!!
- 방금 저정한 파일을 불러와서 openai의 file로 create 해줍니다!!
(각자의 API_KEY 사용!! 이미 알고계시곘죠?ㅎㅎ)
from openai import OpenAI
client = OpenAI(api_key=API_KEY)
client.files.create(
file=open("drfirst_language.jsonl", "rb"),
purpose="fine-tune"
)
그리고 파인튜닝 job을 시작!!!
job_create = client.fine_tuning.jobs.create(
training_file="file-kMuTRiCJIf7djg38xuryBXb6",
model="gpt-4o-mini-2024-07-18"
)
job_create
그럼 openai 계정의 dashboard > fine-tuning에서도 모델이 생성되고있음을 알 수 있습니다!!

이제 리스트에 등록이되어서!!
# fine-tuning리스트 확인하기!!
res = client.fine_tuning.jobs.list(limit=10)
res
나의 모델 리스트 등록 등 활용이 가능합니다!!

다시 dashboard를 보면 잘 학습되고있는것을 확인할수 있어요!!

그리고!! 학습이완료되면 아래와 같이 모델명이 나오게됩니다~!!

3. 모델 활용하기!!
이젠, 마지막단계로 학습된 모델을 사용해보아요!
completion = client.chat.completions.create(
model= '{대시보드에나온모델명}',
messages=[
{"role": "system", "content": "너는 일등박사어를 알려주는 선생님이아"},
{"role": "user", "content": "일등박사어는 뭐야?"}
]
)
print(completion.choices[0].message)이렇게~~ 모델을 돌려보면!?

아주 답변들 잘합니다!!!

ㅎㅎ뿌듯하네요~!!^^

'데이터&AI > LLM' 카테고리의 다른 글
| Gpt realtime Python으로 구현하기!! (0) | 2024.10.19 |
|---|---|
| 오픈소스모델(qwen2-VL)로 동영상 분석하기!! (GPU야!!!) (3) | 2024.10.16 |
| gpt realtime console로 사용해보기 (1) | 2024.10.13 |
| GPT-4o with canvas 를 사용해보자 (feat. chatgpt에서코딩하기) (3) | 2024.10.12 |
| llama3.2 체험하기 (feat. ollama) + 한국어는,, 언제쯤?! (8) | 2024.10.11 |




댓글