2024년 9월 25일!! 메타에서는 llama3.2모델을 공개했습니다!!

이번 모델의 주요 특징 요약!!!!
1. 모바일 및 엣지 디바이스에 적합한 소형(1B, 3B) 및 중형 비전 모델(11B, 90B)로 구분!!
2. 128K 토큰까지 지원하며 Qualcomm, MediaTek, ARM 하드웨어에서 사용 가능!!
3. Claude 3와 같은 폐쇄형 모델보다 이미지 이해 작업에서 더 나은 성능이라고하고!!
4. 여러 플랫폼 파트너 (including AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud, Snowflake) 에서도 사용 가능하다고 했습니다!!
점점 이런 모델 덕분에 소형 라즈베리파이, 혹은 클라우드의 인터넷이 끊긴 환경에서도 고급 llm을 잘 사용할 수 있을것 같습니다!!
그 외에도!! 처음으로 비전이 가능하여!(11B, 90B 에서만 : 텍스트와 이미지를 함께 이해할 수 있는 새로운 아키텍처를 도입 ) 이미지와 텍스트를 동시에 처리하고 고도화된 추론이 가능하다고합니다!!
그리고 경량화모델 (1B, 3B) 들의 특징으로 가지치기(pruning)와 distillation를 통해 성능을 향상시켰다고합니다!!
1. 가지치기는 Llama 3.1 8B 모델을 기반, 네트워크 일부를 제거하면서 성능을 유지했고,
2. distillation (지식 증류?) 는 더 큰 모델의 출력을 작은 모델에 전달하여 성능을 극대화한것이라고 설명되어있습니다.

이 두 방법을 통해 경량 모델이 모바일 장치에서 효율적으로 실행되면서도 높은 성능을 발휘하게 되었습니다.
써보자!!!
이번에는 오랜만에 ollama를 사용해서 llama3.2를 테스트해보겠습니다!!
그래서 ollama를 실행시키고!!
ollama serve
ollama run llama3.2:1bllama3.2 1b 모델을 실행시킵니다!!
다만..아쉬운 소식은

라고하여,, 공식 서포트 언어는 영어, 독일어, 프랑스어, 이탈리아, 포르투갈, 힌디, 스페인, 태국 8개어라고 명시되어있었습니다!!!

그래도!! 한국어를 해볼까요!?

정말 별로구만요,,ㅠㅠ
그럼 영어로!! 요약을 시켜볼까요!?
The Llama FamilyFrom MetaWelcome to the official Hugging Face organization for Llama, Llama Guard, and Prompt Guard models from Meta! In order to access models here, please visit a repo of one of the three families and accept the license terms and acceptable use policy. Requests are processed hourly. In this organization, you can find models in both the original Meta format as well as the Hugging Face transformers format. You can find: Current:
|
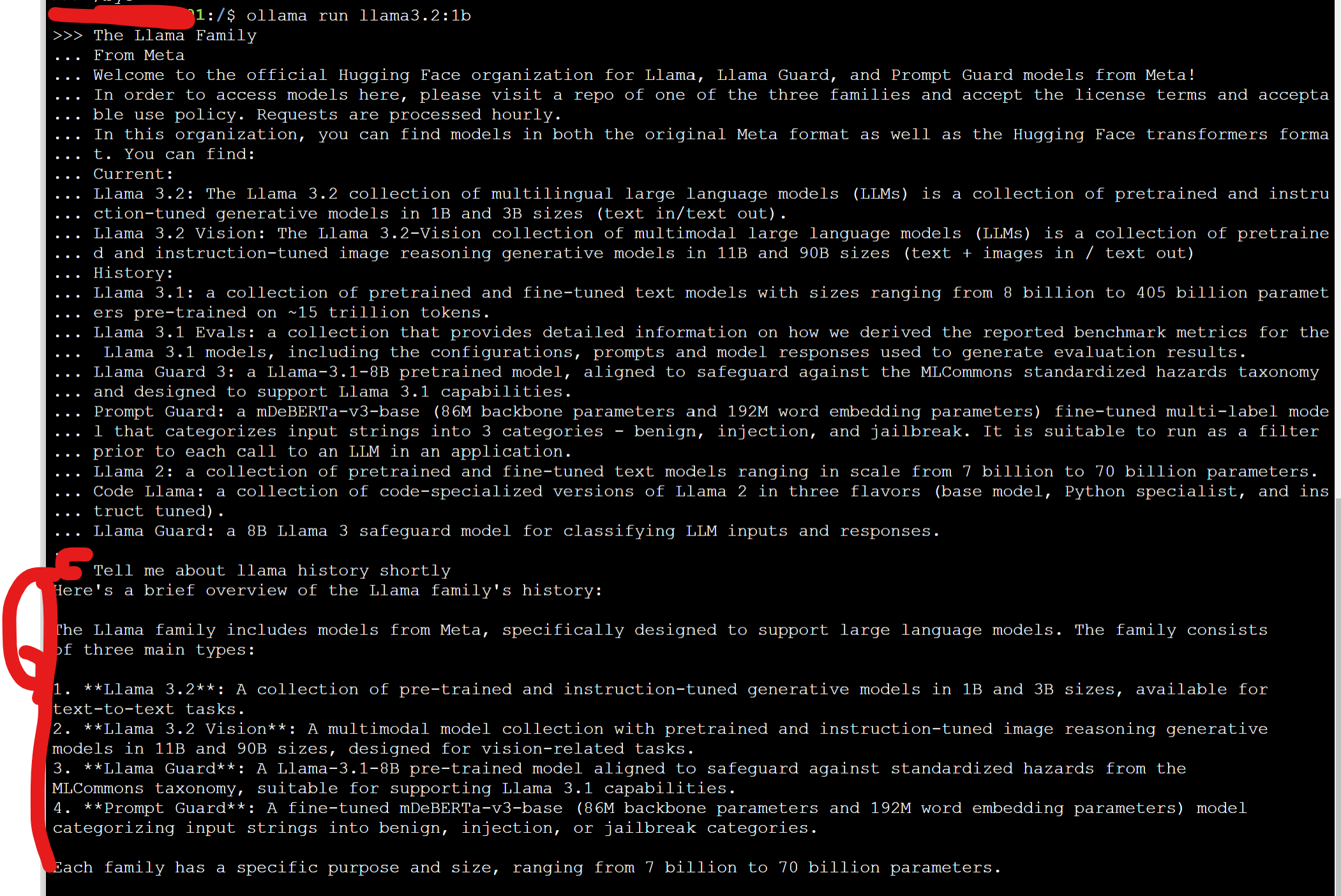
놀라운점은!! 속도가 정말 어마어마하게 빠르다는것입니다!! 위의 긴 프롬포트에 답변하는데 1초도 안걸린것같아요!!
정말정말,, 영어만사용한다면 오픈소스로도 충분히 활용이 가능할것 같습니다!
'데이터&AI > LLM' 카테고리의 다른 글
| gpt realtime console로 사용해보기 (1) | 2024.10.13 |
|---|---|
| GPT-4o with canvas 를 사용해보자 (feat. chatgpt에서코딩하기) (3) | 2024.10.12 |
| 내 컴퓨터에서 llm으로 이미지를 분석해 보쟈! (feat. qwen2-VL) (4) | 2024.10.10 |
| vllm 설치하고 오픈소스 모델을 openai 모듈로 써보기!(feat. 알리바바의 qwen2.5 예시!!) (0) | 2024.10.08 |
| LLM모델의 양자화!!(Quantization): GPTQ 및 AWQ 방식 알아보 (0) | 2024.10.07 |




댓글