qwen모델 파해지기가 계속되고있습니다!!
2024.10.03 - [데이터&AI/LLM] - 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM)
네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM)
Qwen 2.5 Math: 알리바바가 개발한 새로운 AI 수학 모델 소개 (24년 10월!!)최근 AI 기술의 발전과 함께, 수학 문제 해결을 위한 특화된 모델들이 속속 등장하고 있는데요~~~알리바바 그룹의 AI 연구 부서
drfirst.tistory.com
2024.10.06 - [데이터&AI/LLM] - Qwen2.5를 사용해보기!!! (feat 한국어실력 확인!! qwen2와의 비교 )
Qwen2.5를 사용해보기!!! (feat 한국어실력 확인!! qwen2와의 비교 )
2024.10.03 - [데이터&AI/LLM] - 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM) 네가 그렇게 수학을 잘하니? Qwen2.5-Math (feat. 오픈소스 LLM)Qwen 2.5 Math: 알리바바가 개발한 새로운 AI 수학 모델
drfirst.tistory.com
이번에는 2.5는 아니고 2모델에서 공개된 vision language 모델!!
qwen2.5-VL을 한번 사용해보려구하요~~
1. 모델 소개!!

Qwen2-VL은 오픈소스로 공개된 알리바바클라우드의 VIsion 언어 모델로서 아래와 같은 특징을 자랑합니다!!
주요 개선 사항:
- 다양한 해상도 및 비율의 이미지에 대한 SoTA(최첨단) 이해: Qwen2-VL은 MathVista, DocVQA, RealWorldQA, MTVQA 등 시각적 이해 벤치마크에서 최첨단 성능을 달성
- 20분 이상의 비디오 이해: 온라인 스트리밍 기능을 통해 Qwen2-VL은 20분이 넘는 비디오를 이해할 수 있으며, 고품질 비디오 기반 질문 응답, 대화, 콘텐츠 생성 등의 작업을 수행
- 모바일, 로봇 등의 기기를 작동하는 에이전트: Qwen2-VL은 복잡한 추론과 의사 결정 능력을 갖추고 있어 시각적 환경과 텍스트 지시를 바탕으로 모바일 기기나 로봇 같은 장치를 자동으로 작동 가능.
- 다국어 지원: 글로벌 사용자들을 위해, Qwen2-VL은 영어와 중국어뿐만 아니라 이미지 내 텍스트를 이해하는 데 있어 대부분의 유럽 언어, 일본어, 한국어, 아랍어, 베트남어 등 다양한 언어를 지원. 공식적으로 한국어가 된다고 명시했어요!!!!!
모델 구조를 간단히 본다면!!!
- Naive Dynamic Resolution: Qwen2-VL은 이전과 달리 임의의 이미지 해상도를 처리할 수 있으며, 이를 동적으로 시각 토큰 수로 변환하여 보다 인간적인 시각 처리 경험을 제공 즉!! 다양한 해상도의 이미지를 더 잘 처리할 수 있는 기능이있습니다!!
- 멀티모달 회전 위치 임베딩(M-ROPE): 위치 임베딩을 1D 텍스트, 2D 시각, 3D 비디오 위치 정보로 분해하여 멀티모달 처리 능력을 향상시킵니다.
2. 영상분석!!

그 중 특별한것은!! 20분이상의 영상도 이해한다고!!?
진짜인지 확인을 위해 석양에서 배의 노를 젓는 15초 짜리 영상을 테스트해보겠습니다!
https://www.pexels.com/video/silhouette-of-a-man-on-a-boat-at-sunset-3569604/

코드는 공식적으로 제공된 코드를 사용해보려구합니다~~
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "/home/bongo/porter_notebook/llm/qwen/boat.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)그래서 진행하니!!!!
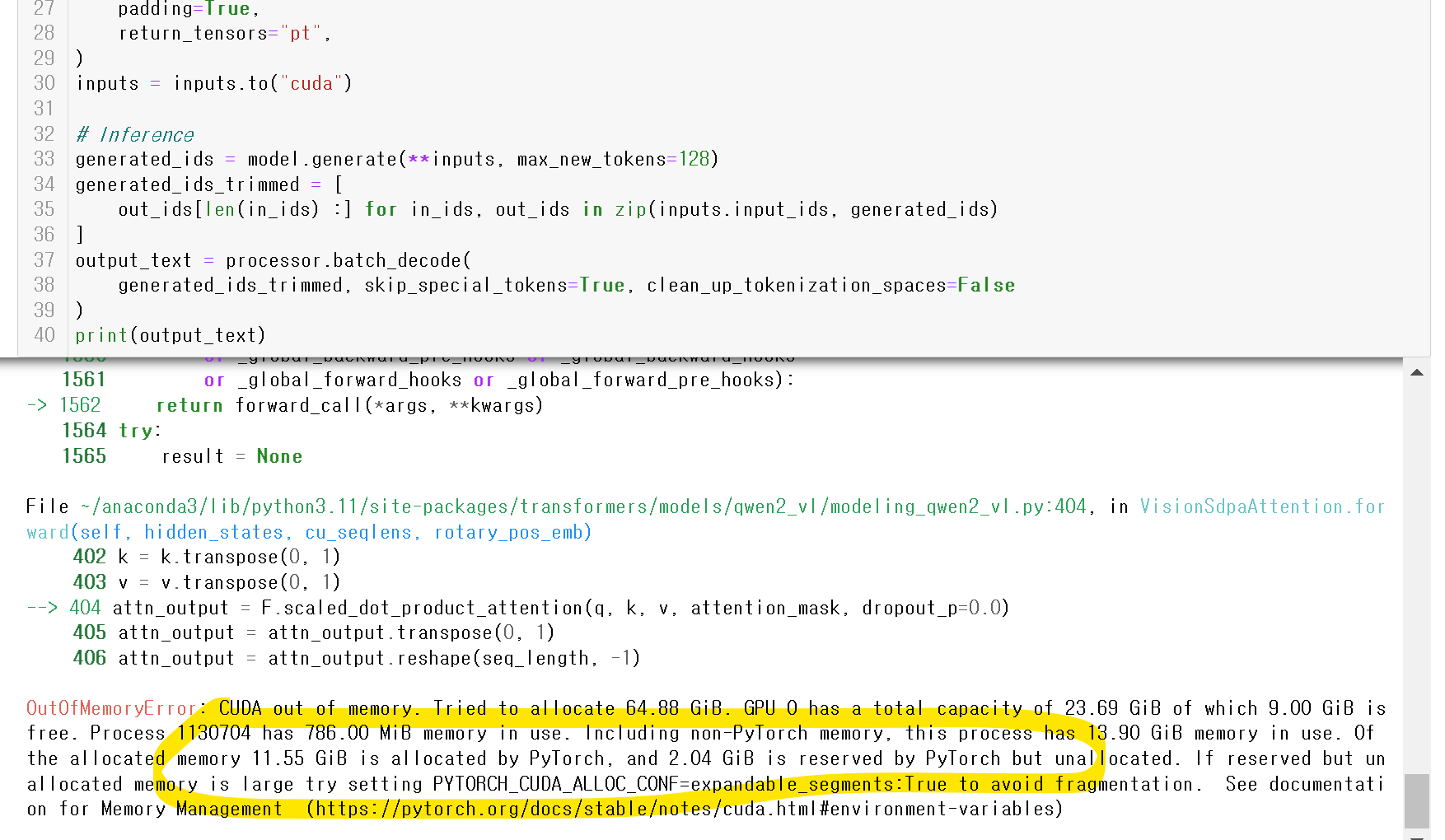
ㅠㅠ 저는 24GB의 3090 GPU를 보유하고있어서,,
64GB 이상의 GPU가 필요하다고하는 이 코드를 실행시킬수가 없었습니다ㅠㅠ
아쉽지만,, 언젠간 더 경량된 모델이 나오고!! 저는 더 고성능의 GPU를 보유할수 있기를,,,
ㅁ 참고 : https://github.com/QwenLM/Qwen2-VL
GitHub - QwenLM/Qwen2-VL: Qwen2-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.
Qwen2-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen2-VL
github.com
'데이터&AI > LLM' 카테고리의 다른 글
| OpenAI의 멀티에이전트 framework SWARM 알아보기 (1) | 2024.10.20 |
|---|---|
| Gpt realtime Python으로 구현하기!! (0) | 2024.10.19 |
| gpt-4o 모델을 fine-tuning 하기!!! (python API 활용해서!) (0) | 2024.10.15 |
| gpt realtime console로 사용해보기 (1) | 2024.10.13 |
| GPT-4o with canvas 를 사용해보자 (feat. chatgpt에서코딩하기) (3) | 2024.10.12 |




댓글