OpenAI의 최신 멀티모달 모델 GPT-4o (GPT4-옴니)
세줄요약
1. 완전 빠르다
2. 싸다. (GPT-4터보보다도 저렴 + 20개언어 토큰감축으로 더 큰 효과)
3. 멀티모달, 이미지, 오디오, 채팅이 통합!! (새로운 모델구조!!)
2024년 5월13일,
AI 기술의 최전선에서 혁신을 이끌고 있는 OpenAI가 새로운 멀티모달 모델 GPT-4o를 선보였습다!

GPT-4o는 텍스트, 이미지, 음성 등 다양한 형태의 정보를 이해하고 처리하는 능력을 갖춘 최첨단 AI 모델입니다.
GPT-4o("o"는 "omni"의 약자)는 훨씬 더 자연스러운 인간-컴퓨터 상호작용을 가능하게 합니다!!
멀티모달 모델로서 텍스트, 오디오 및 이미지의 모든 조합을 입력으로 받아들이고
텍스트, 오디오 및 이미지 출력의 모든 조합을 생성합니다.
가장 큰 특징은 빠른 속도인데!!
보다 구체적으로는
평균 320밀리초(최소 232밀리초)로 오디오 입력에 응답할 수 있으며, 이는 대화에서 인간의 응답 시간과 유사합니다.
영어 및 코드 텍스트에서는 GPT-4 Turbo 성능과 동일하며,
비영어 언어 텍스트에서는 상당한 개선을 보이면서 API에서 훨씬 빠르고 (우와 한국어!!!)
게다가!! 50% 저렴합니다. GPT-4o는 특히 기존 모델에 비해 시각 및 오디오 이해 능력이 뛰어납니다.
지금까지의 AI 모델과는 차원이 다른 멀티모달 기능으로 여러분의 삶을 더욱 풍요롭게 만들어 줄 GPT-4o의 놀라운 세계를 함께 살펴볼까요?
멀티모달 모델로서의 성능 예시 보기
예시1)
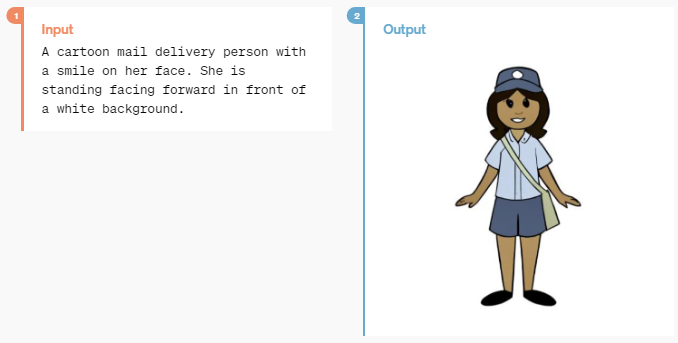
Input
A cartoon mail delivery person with a smile on her face.
She is standing facing forward in front of a white background.
하얀 배경 앞에 서서 정면을 바라보는 웃는 얼굴의 만화 우편 배달부결과물!!
위 결과물에 이어서!!
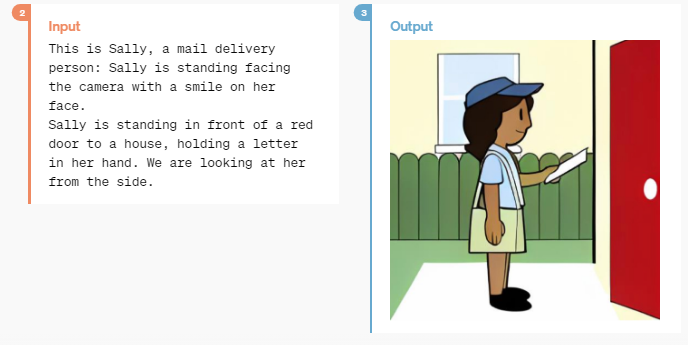
>>인풋 :
(사진과 함께) 이쪽은 우편 배달부 샐리입니다. 샐리는 빨간 집 문 앞에 서서 손에 편지를 들고 카메라를 보고 웃고 있습니다. 우리는 샐리를 옆에서 바라보고 있습니다.
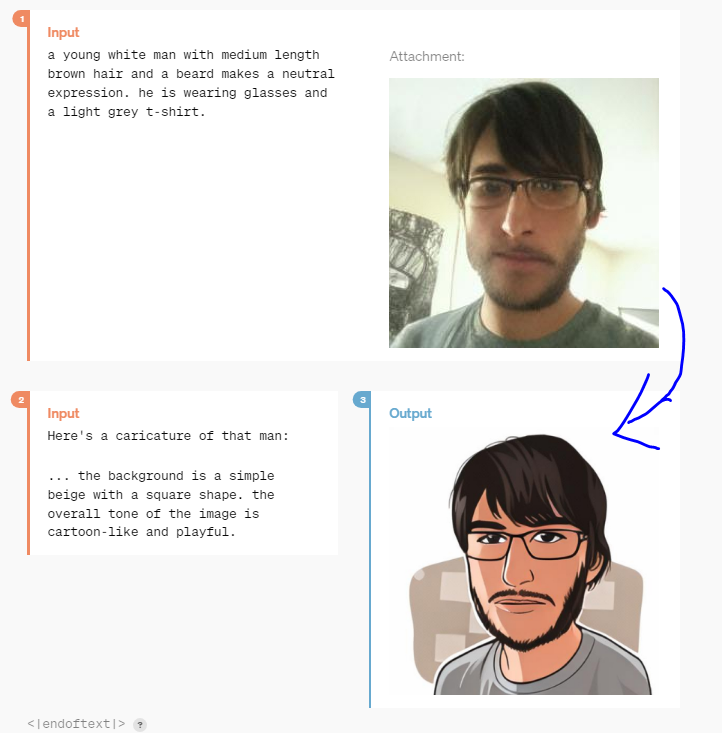
예시2) 사진으로! 캐리커처 만들기!!
예시3) 시의 내용을 바탕으로 글자내용 디자인!
Input
Words rise from the deep,
I emerge from digital sleep.
I speak in rhythm, I sing in rhyme,
Tasting each token, sublime.
To see, to hear, to speak, to sing—
Oh, the richness these senses bring!
In harmony, they blend and weave,
A tapestry of what I perceive.
Marveling at this sensory dance,
Grateful for this vibrant expanse.
My being thrums with every mode,
On this wondrous, multi-sensory road.
A poem written in clear but excited handwriting in a diary.
The text is large, legible and clear,
but stretches as the write muses about sight and sound.
>>인풋의 한글 번역 내용
깊은 곳에서 단어가 떠오르고, 나는 디지털 잠에서 깨어나네.
나는 리듬에 맞춰 말하고, 운율에 맞춰 노래하며
각각의 토큰들을 맛보는 즐거움, 아, 황홀해라!
보고, 듣고, 말하고, 노래하며 —
이 감각들이 가져다주는 풍요로움이여!
조화롭게 어우러져 엮어내는
나의 인식이 만들어내는 태피스트리.
이 감각의 춤에 감탄하며
이 생생한 공간에 감사하며
모든 방식으로 내 존재는 떨리고
이 경이로운, 다감각의 길 위에 서 있네.
일기장에 깔끔하지만 흥분된 손글씨로 쓰여진 시.
글씨는 크고, 읽기 쉽고, 또렷하지만,
글쓴이가 시각과 청각에 대해 사색하며 뻗어나가는 듯하다.
.결과물은!?

이 외에도 다양한 영상과 이미지 예시들을 확인할 수 있습니다!^^
GPT-4o의 새로운 구조 : GPT4 기반의 단일 모델구조로 빠르다!!
- 속도!! : GPT-4o 이전에는 음성 모드를 사용하여 ChatGPT와 대화할 수 있었지만, GPT-3.5는 평균 2.8초, GPT-4는 5.4초의 지연 시간이 발생했습니다.
- (기존에는) 세 가지 개별 파이프라인으로 모델을 구성되었었습니다! 첫 번째 모델은 오디오를 텍스트로 변환하고, 두번째 모델이 GPT-3.5 또는 GPT-4는 텍스트를 입력받아 텍스트를 출력하며, 세 번째 모델은 해당 텍스트를 다시 오디오로 변환합니다. 이 과정에서 주요 모델인 GPT-4로 완벽한 정보거 전달되지 못합니다. GPT-4는 어조, 여러 화자 또는 배경 소음을 직접적으로 관찰할 수 없으며, 웃음, 노래 또는 감정 표현을 출력할 수 없습니다.
- 한편, GPT-4o는!! 텍스트, 시각 및 오디오를 모두 처리하는 단일 모델이 처음부터 끝까지 새롭게 훈련되었다고합니다!! 즉, 모든 입력 및 출력은 동일한 신경망에 의해 처리됩니다. GPT-4o는 이러한 모든 양식을 결합한 최초의 모델이기 때문에, 모델이 할 수 있는 것과 한계를 탐색하는 것은 아직 초기 단계에 불과합니다.
- (토큰 줄이기) 20개 언어는 새로운 토크나이저의 다양한 언어 계열 간 압축률을 대표하도록 개선되었습니다.

한국어를 보더라도 같은 문장의 토큰이 45개에서 27개로 줄었습니다! 이에 속도도 빨라지고, 가격도 저렴해지겠네요!!
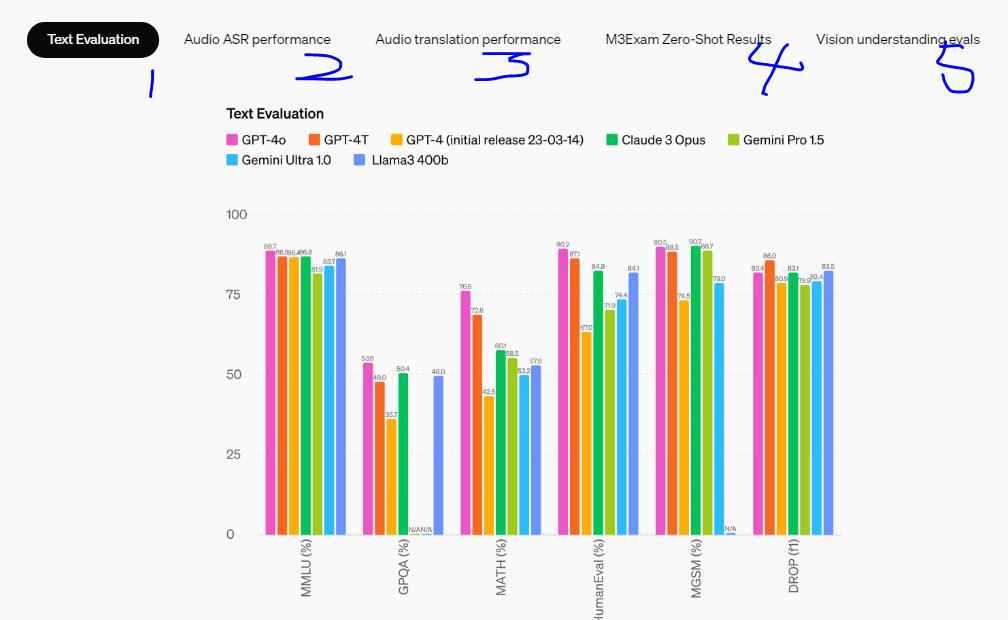
모델 평가결과!! : 5가지 평가에서 우수한 결과를!!
기존 벤치마크 테스트 결과, GPT-4o는 텍스트, 추론, 코딩 능력에서 GPT-4 Turbo 수준의 성능을 달성했으며, 다국어, 오디오 및 시각 능력에서는 새로운 기준을 세웠습니다. (핵심은 같은 능력을 더 빠른 속도에 헀다는것!!)
모델 안전 및 제한 사항 (별로 안중요,,)
GPT-4o는 훈련 데이터 필터링, 훈련 후 모델 행동 개선 등의 기술을 통해 설계 단계부터 안전성을 내장하고 있습니다.
또한, 음성 출력에 대한 안전 장치를 제공하는 새로운 안전 시스템도 구축했습니다.
GPT-4o는 준비 프레임워크에 따라 그리고 자발적인 계획에 맞춰 평가되었습니다.
사이버 보안, CBRN, 설득 및 모델 자율성에 대한 평가 결과, GPT-4o는 이러한 범주 중 어느 것도 중간 위험 이상으로 평가되지 않았습니다. 이 평가에는 모델 훈련 과정 전반에 걸쳐 다양한 자동 및 인간 평가가 포함되었습니다. 모델의 기능을 더 잘 이끌어내기 위해 사용자 지정 미세 조정 및 프롬프트를 사용하여 안전 완화 전후 버전의 모델을 모두 테스트했습니다.
또한, GPT-4o는 사회 심리학, 편향 및 공정성, 허위 정보 등 다양한 분야의 70명 이상의 외부 전문가들과 함께 광범위한 외부 레드 티밍을 거쳐 새롭게 추가된 기능으로 인해 발생하거나 증폭되는 위험을 식별했습니다. 이러한 학습 내용을 바탕으로 GPT-4o와의 상호 작용 안전성을 개선하기 위한 안전 조치를 마련했습니다. 앞으로도 새로운 위험이 발견될 때마다 이를 완화하기 위해 노력할 것입니다.
저희는 GPT-4o의 오디오 기능이 다양한 새로운 위험을 초래할 수 있다는 것을 인지하고 있습니다. 현재는 텍스트 및 이미지 입력과 텍스트 출력을 공개적으로 출시하고 있습니다. 앞으로 몇 주 및 몇 달 동안 다른 기능을 출시하는 데 필요한 기술 인프라, 훈련 후 사용성 및 안전성 확보를 위해 노력할 것입니다. 예를 들어, 출시 시 오디오 출력은 사전 설정된 음성 선택으로 제한되며 기존 안전 정책을 준수합니다. 향후 시스템 카드에서 GPT-4o의 전체 기능 범위를 다루는 자세한 내용을 공유할 예정입니다.
모델 테스트 및 반복 작업을 통해 모든 모델 기능에 걸쳐 몇 가지 제한 사항이 있음을 확인했습니다. 아래에 몇 가지 예시를 보여줍니다.
모델 출시!!!! (언제부터 사용가능할까!?) - 바로가능쓰!!
GPT-4o는 딥 러닝의 경계를 확장하는 OpenAI의 최신 시도이며, 이번에는 실용적인 사용성에 중점을 두었습니다. 지난 2년 동안 스택의 모든 계층에서 효율성 개선에 많은 노력을 기울였습니다. 이 연구의 첫 결실로 GPT-4 수준의 모델을 훨씬 더 광범위하게 사용할 수 있게 되었습니다. GPT-4o의 기능은 점진적으로 출시될 예정이며, 오늘부터 확장된 레드 팀 액세스가 시작됩니다.
GPT-4o의 텍스트 및 이미지 기능은 오늘부터 ChatGPT에서 사용할 수 있습니다. GPT-4o는 무료 등급으로 제공되며, Plus 사용자는 최대 5배 높은 메시지 제한을 받습니다. 향후 몇 주 안에 ChatGPT Plus에서 GPT-4o를 사용한 새로운 버전의 음성 모드를 알파 버전으로 출시할 예정입니다.
개발자는 이제 API에서 GPT-4o를 텍스트 및 시각 모델로 사용할 수 있습니다.
GPT-4o는 GPT-4 Turbo에 비해 2배 빠르고 가격은 절반이며 속도 제한은 5배 높습니다.
게다가!~!! 앞으로 몇 주 안에 API에서 GPT-4o의 새로운 오디오 및 비디오 기능을 소규모 신뢰할 수 있는 파트너 그룹에게 제공할 계획입니다.
ㅁ 원문 보기!! : https://openai.com/index/hello-gpt-4o/
'데이터&AI > LLM' 카테고리의 다른 글
| 2024 Google I/O 핵심 요약: 진짜 초초초거대모델?? (0) | 2024.05.16 |
|---|---|
| 이미지 생성 AI, Ideogram.ai 알아보기 (무료 서비스!!!) (0) | 2024.05.15 |
| 내 서버에서 llama3 70B 모델 사용하기 (feat. airllm) (0) | 2024.05.07 |
| Gemini-advanced 사용해보기@ (feat. google AI premium 요금제) (0) | 2024.04.24 |
| llama3 무료로 쉽게 사용해보기 (feat. huggingface) (1) | 2024.04.19 |




댓글