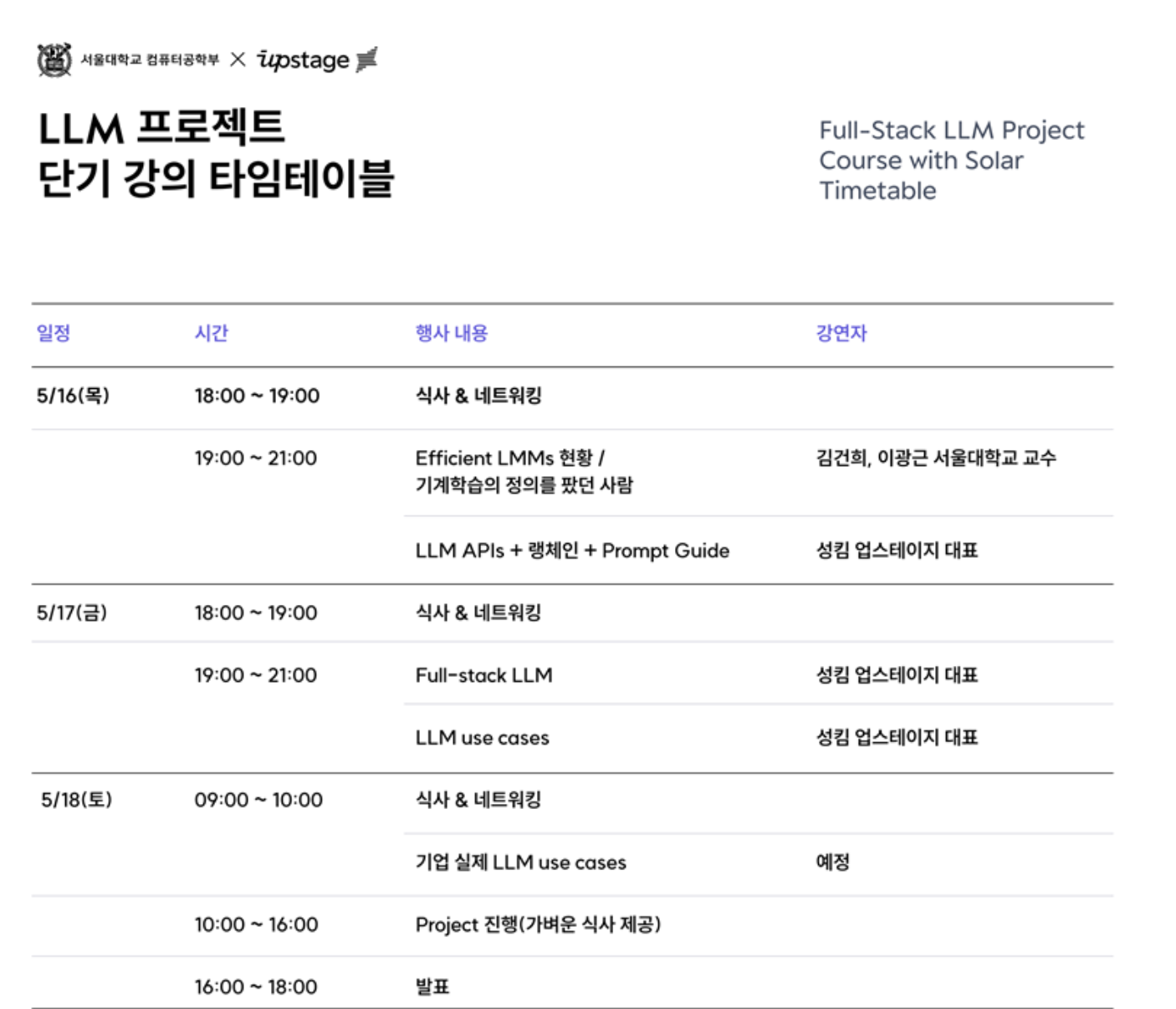
https://kiise.or.kr/conference/conf/147/
한국정보과학회 - 학술대회 홈페이지
kiise.or.kr
첫수업!! 서울대 컴퓨터공학부 이광근 교수님.

기계계산의 정의와 탄생!!
쿠르트 괴델 (Kurt Gödel)
- 괴델의 불완전성 정리:
- 제1 정리: 모든 일관된 형식적 시스템(수학의 공리체계)에는 그 시스템 내에서 참이지만 증명할 수 없는 명제가 존재한다.
- 제2 정리: 어떤 형식적 시스템이 일관되다는 것을 그 시스템 내에서는 증명할 수 없다.
- 이 정리들은 수학적 시스템의 한계를 명확히 했으며, 알고리즘과 계산 가능성에 대한 이해를 깊게 하였습니다.
5살 어린 동생, 앨런 튜링 (Alan Turing)
- 튜링 기계

- 튜링은 알고리즘 개념을 형식화하는 튜링 기계 고안, 추상적인 계산 모델로서, 현대 컴퓨터의 이론적 기반이 됨
- 튜링 기계는 기계학습 모델의 계산 가능성 제
- 계산 가능성과 결정 문제:
- 튜링은 "계산 가능 함수"의 개념을 도입하여 어떤 문제가 알고리즘적으로 해결 가능한지에 대한 이론적 틀을 마련했습니다.
- 튜링의 연구는 어떤 문제를 기계학습 알고리즘이 풀 수 있는지, 어떤 문제는 풀 수 없는지에 대한 이해를 돕습니다
결론 : 기계계산은 튜링기계로 돌리는 계산이다!! llm도!!
두번째수업!! 서울대 컴퓨터공학부 김건 교수님.
주제 : Efficient LLM
모두 잘하는 llm은 필요없다!! 내 분야에서만 잘하는 llm 이면 된다!
그래서!? 모두가 오픈소스 기반으로 연구중이다!!
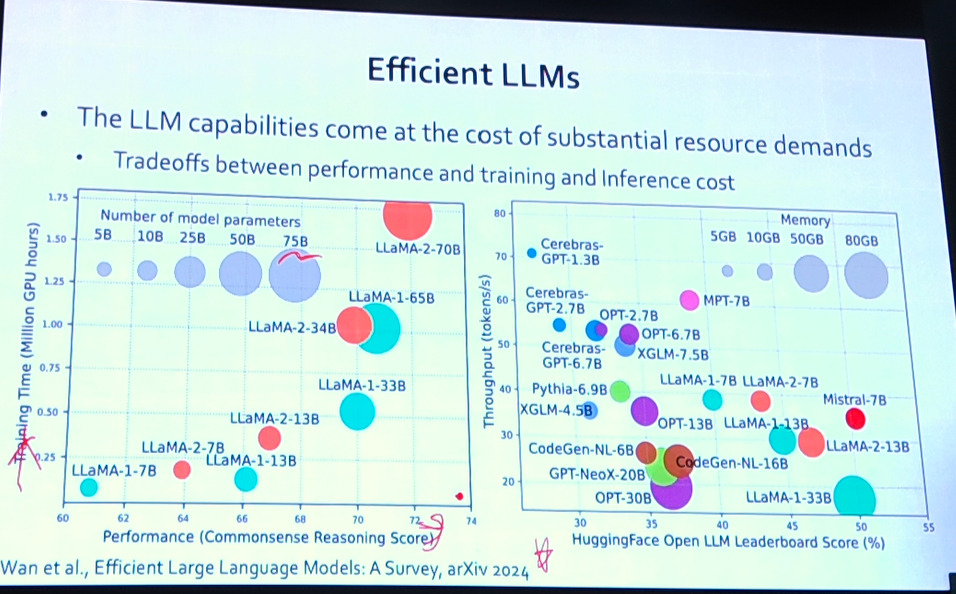
하지만 큰모델일수록 성능이 좋다!!
그런데 조금만 더 늘릴려고 하는 트레이닝과 파라미터가 거대하다!!
그래서 나온 LLM(대형 언어 모델) 고도화의 방법론!!
1. Model-centric 접근
Model-centric 접근은 모델의 구조와 매개변수 튜닝에 중점을 둠. 모델 자체를 개선하는 방법론
특징:
- 모델 아키텍처 개선: 트랜스포머 구조, 레이어 수, 어텐션 메커니즘 등 모델의 기본 구조를 최적화합니다.
- 하이퍼파라미터 튜닝: 학습률, 배치 크기, 드롭아웃 비율 등 모델 학습에 영향을 미치는 파라미터를 조정합니다.
- 프리트레이닝 기법: 대규모 코퍼스를 사용한 사전 학습(pretraining)을 통해 모델의 언어 이해 능력을 향상시킵니다.
- 모델 크기: 더 큰 모델(파라미터 수가 많은 모델)을 사용하여 성능을 개선하려고 합니다. 예: GPT-3, GPT-4 등.
- 전이 학습: 사전 학습된 모델을 특정 작업에 맞게 미세 조정(fine-tuning)하여 성능을 극대화합니다.
2. Data-centric 접근
데이터의 품질과 양을 개선하여 모델의 성능을 향상시키는 방법론. 데이터를 모델 학습의 핵심 요소로 봅니다.
특징:
- 데이터 품질: 깨끗하고 일관된 데이터를 확보하기 위해 데이터 클리닝과 전처리를 강조합니다.
- 데이터 양: 더 많은 데이터를 수집하여 모델이 다양한 상황을 학습할 수 있도록 합니다.
- 라벨링 품질: 정교하고 정확한 라벨링을 통해 지도 학습의 성능을 높입니다.
- 데이터 증강: 데이터의 다양성을 높이기 위해 데이터 증강 기법을 사용합니다. 예: 텍스트 증강, 데이터 샘플 변형 등.
- 다양한 데이터 소스: 여러 출처의 데이터를 사용하여 모델이 다양한 언어적 특성과 문맥을 학습할 수 있도록 합니다.
- 노이즈 제거: 데이터에서 노이즈와 불필요한 정보를 제거하여 모델 학습의 효율성을 높입니다.
3. LLM Frameworks
LLM 프레임워크는 대형 언어 모델을 구축, 학습, 배포하는 데 필요한 도구와 라이브러리를 제공. 이 프레임워크는 모델과 데이터 모두를 효과적으로 관리할 수 있도록 설계되었습니다.
특징:
- 모델 관리: 모델 학습, 저장, 배포에 필요한 기능을 제공합니다. 예: Hugging Face Transformers, TensorFlow, PyTorch.
- 데이터 파이프라인: 데이터 수집, 전처리, 로딩을 위한 도구를 포함합니다. 효율적인 데이터 파이프라인을 구축할 수 있습니다.
- 분산 학습: 대규모 데이터를 처리하고 모델을 학습하기 위해 분산 학습 환경을 지원합니다.
- 확장성: 대규모 모델과 데이터를 처리할 수 있도록 확장 가능한 인프라를 제공합니다.
- 사용 편의성: 연구자와 개발자가 쉽게 사용할 수 있도록 직관적인 API와 문서를 제공합니다.
- 커뮤니티와 지원: 활발한 커뮤니티와 다양한 튜토리얼, 예제, 지원 자료를 제공합니다.
그중! 일반적인 사용자들은@@ Fine tuning을 많이한다!!

PEFT (Parameterized Efficient Fine-Tuning)
PEFT는 대형 모델의 일부 파라미터만을 조정하여 미세 조정을 수행하는 기법. 모델의 효율성을 높이고 학습 시간과 메모리 사용량을 줄일 수 있습니다.
특징:
- 부분 파라미터 조정: 전체 모델이 아닌 일부 파라미터만을 조정하여 효율성을 높입니다. 이는 모델의 크기가 매우 큰 경우 특히 유용합니다.
- 동결 파라미터: 대부분의 파라미터는 동결시키고, 특정 층이나 모듈의 파라미터만을 조정합니다. 이는 학습 시간을 줄이고, 과적합을 방지하는 데 도움이 됩니다.
- 메타 파라미터 튜닝: 학습률, 배치 크기 등 메타 파라미터를 최적화하여 조정할 파라미터의 효율성을 극대화합니다.
- 전이 학습: 사전 학습된 모델을 사용하고, 특정 작업에 맞게 일부 파라미터만 미세 조정하여 전이 학습의 이점을 최대한 활용합니다.
MEFT (Modular Efficient Fine-Tuning)
MEFT는 모델을 모듈화하여 각 모듈을 독립적으로 조정하는 기법. 모델의 특정 부분만을 조정하며, 확장성과 재사용 ↑
특징:
- 모듈화: 모델을 여러 모듈로 분할하고, 각 모듈을 독립적으로 미세 조정할 수 있습니다. 이를 통해 특정 모듈만을 조정하여 모델의 특정 기능을 향상시킬 수 있습니다.
- 재사용성: 조정된 모듈을 다른 모델이나 작업에 재사용할 수 있습니다. 이는 효율적인 개발과 연구를 가능하게 합니다.
- 확장성: 모델의 특정 모듈을 교체하거나 업그레이드하여 모델을 확장할 수 있습니다. 이를 통해 새로운 기능을 추가하거나 성능을 향상시킬 수 있습니다.
- 분산 학습: 모듈별로 학습을 분산시켜 대규모 모델의 학습 효율성을 높일 수 있습니다.
그리고! LoRA(Low-rank Adaption) (feat SVD)
LoRA는LLM 의 fine-tuning을 효율적으로 수행할 수 있는 도구, 자원 사용을 최소화하면서도 높은 성능을 유지할 수 있음
-
- 저랭크 근사: 모델 파라미터를 저랭크 행렬로 분해하여 효율적인 학습과 경량화를 달성합니다.
- 사전 학습된 파라미터 보존: 사전 학습된 파라미터를 대부분 유지하면서 일부 파라미터만 미세 조정하여 효율성을 극대화합니다.
- 확장성과 재사용성: 미세 조정된 파라미터를 모듈화하여 저장하고 다양한 작업에 재사용할 수 있습니다.
Input: Pre-trained model parameters W
Output: Adapted model parameters W' with low-rank updates
1. Initialize low-rank matrices A and B with smaller dimensions than W
2. Freeze the original model parameters W during fine-tuning
3. Replace W with W + A * B
4. Fine-tune only the parameters of matrices A and B
5. Use the adapted model with parameters W' = W + A * B for downstream tasks이에 더해서!! qLoRA (Quantized Low-Rank Adaptation)
qLoRA의 주요 특징
1. 저랭크 근사 (Low-Rank Approximation)
LoRA 접근 방식과 마찬가지, qLoRA는 모델의 파라미터를 두 개의 저랭크 행렬로 분해하여 효율적인 미세 조정을 수행.
- 효율성: 저랭크 행렬 근사는 원래 파라미터 공간을 축소하여 계산 비용과 메모리 사용을 줄입니다.
- 경량화: 모델의 복잡성을 줄이고, 경량화된 형태로 유지합니다.
2. 양자화 (Quantization)
qLoRA는 추가적으로 양자화를 도입, 파라미터의 비트를 줄여 메모리 사용과 계산 속도를 최적화
- 메모리 절감: 파라미터를 낮은 정밀도로 표현하여 메모리 사용을 줄입니다.
- 계산 효율성: 양자화된 파라미터는 계산 속도를 높여 모델의 추론 시간을 단축시킵니다.
- 성능 유지: 양자화 기술을 사용해 성능 저하를 최소화하면서도 효율성을 극대화합니다.
3. 저랭크 행렬과 양자화 결합
qLoRA는 저랭크 행렬 근사와 양자화를 결합하여 두 가지 기법의 장점을 모두 활용합니다.

- 저비용 미세 조정: 저랭크 행렬을 사용해 효율적으로 모델을 미세 조정하면서도 양자화를 통해 추가적인 메모리 절감을 달성합니다.
- 성능 최적화: 양자화된 저랭크 행렬을 통해 모델의 성능을 최적화하고, 효율성을 높입니다.
Speculative Decoding : llm의 텍스트 생성 속도를 높이기 위한 효과적인 기법
- 기존 문제점 : 순차적 텍스트 생성: 전통적인 텍스트 생성 방식에서는 한 번에 한 토큰씩 생성. 이전 토큰이 결정된 후에야 다음 토큰을 예측 가능하기에 정확하지만 속도가 느립니다.
- Speculative decoding의 기본 아이디어:
- Speculative decoding은 여러 토큰을 동시 생성하여 텍스트 생성 속도를 향상. 두 개의 모델을 활용!!
- 가이드 모델(Guide Model): 빠르고 덜 정교한 모델로, 여러 후보 토큰 시퀀스를 빠르게 생성합니다.
- 리파인 모델(Refine Model): 더 정확하고 정교한 모델로, 가이드 모델이 생성한 후보 중에서 최종 출력을 선택하거나 조정
- Speculative decoding은 여러 토큰을 동시 생성하여 텍스트 생성 속도를 향상. 두 개의 모델을 활용!!

동작 방식
- 초기 후보 생성: 가이드 모델이 현재 토큰부터 시작하여 여러 후보 토큰 시퀀스를 빠르게 생성
- 후보 검토 및 선택: 리파인 모델이 가이드 모델이 생성한 후보 시퀀스를 검토, 리파인 모델은 각 후보 시퀀스의 확률을 계산하고, 가장 적합한 시퀀스를 선택하거나 조정
- 결과 출력:리파인 모델이 최종적으로 선택한 시퀀스가 출력. 이 과정은 전체 텍스트 생성 속도를 크게 향상시킬 수 있습니다.
'데이터&AI > LLM' 카테고리의 다른 글
| [2024.5.17] 성킴님의 LLM, langchain 강의 - SNUxUpstage LLM 세션② (3) | 2024.05.17 |
|---|---|
| upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의) (0) | 2024.05.16 |
| 2024 Google I/O 핵심 요약: 진짜 초초초거대모델?? (0) | 2024.05.16 |
| 이미지 생성 AI, Ideogram.ai 알아보기 (무료 서비스!!!) (0) | 2024.05.15 |
| OpenAI의 새로운 모델 GPT-4o 알아보기!! (feat. 빠르고 저렴하고 좋다) (1) | 2024.05.14 |




댓글