안녕하세요!!!
정보는 돈이라는 빅데이터의 시대!!
기업은 고객 데이터와 생산 데이터,
그리고 데이터 판매업체로부터 구매한
다양한 고품질의 정보들을 분석하며
재미있는 인사이트들을 많이 발굴하고 있는데요!!
반면, 개인적으로 데이터 분석을 시도하는 저로서는
고도의 데이터 분석 능력을 떠나
데이터를 구하는것 자체가 쉽지 않은 일입니다!!
이때 가장 유용하게 활용할 수 있는 정보로
Twitter API, 네이버 댓글정보 등이 있습니다!!
오늘은 네이버 뉴스의 댓글과
그 통계적 정보를 수집하는 방법을
공유하는 포스팅을 작성해보겠습니다!!^^*
1. Target : 네이버 뉴스 댓글 및 통계정보


2. 방법 : Python의 Request
1. 관련 package import
import bs4
import requests
import json
import pandas as pd
from bs4 import BeautifulSoup
from datetime import datetime
import time
2. 필요한 변수 설정
# "YTN : num_ = '0001644604' # 2021 12 29 NEW'0001668339'
num_ = "0001624537"
# num_에 해당하는 기사를 기준으로 과거에 생성된 기사들을 수집!
news_company = "052" # 한경 ㅣ 015 매경 : 009 YTN : 052
target_num = int(num_)
reply_all_l = []
reply_all_index_l = []
title_l = []
gender_male_l = []
gender_female_l = []
ages_group_10_l = []
ages_group_20_l = []
ages_group_30_l = []
ages_group_40_l = []
ages_group_50_l = []
ages_group_60_l = []
crawl_time_l = []
reply_cnt_l = []
news_id_l = []※ new_company의 경우 네이버 뉴스에서 확인할 수 있습니다.
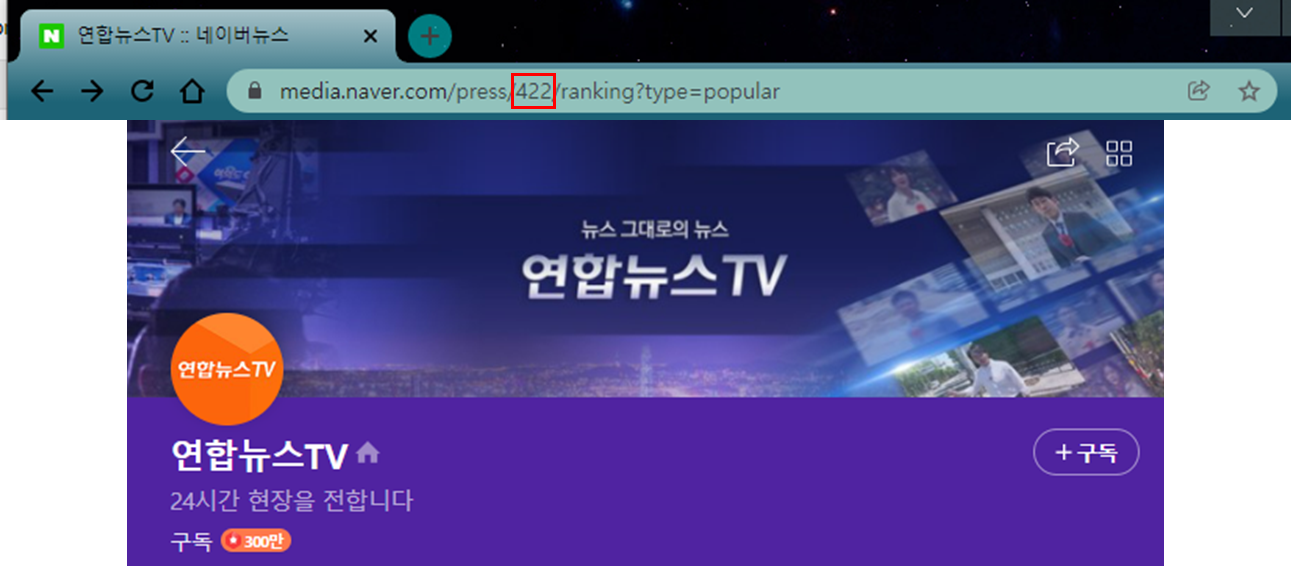
※ num은 기사의 고유 번호로 마찬가지로 네이버 뉴스에서 확인할 수 있습니다.

3. 댓글의 통계정보를 가져올 함수(gogo_reply) 만들기!
"""
- 함수명 : gogo_reply
- 함수 역할 : new_ori 의 URL의 가진 뉴스의 댓글 통계정보 및 모든 댓글 크롤링
(통계정보가 없는 소량 댓글 뉴스의 경우 error 발생)
- Input 변수
> uri_ori : 댓글을 수집하고자하는 뉴스 URL
> referer : request의 get에 필요로 되는 referer URL
> news_id : 회사id와 뉴스번호가 결합된 뉴스 고유 key
- output 변수
> uri_ori : 댓글을 수집하고자하는 뉴스 URL
> referer : request의 get에 필요로 되는 referer URL
> news_id : 회사id와 뉴스번호가 결합된 뉴스 고유 key
> gender_male : 남성 비중 (0~100)
> gender_female : 여성 비중 (0~100)
> ages_group_10 : 각 연령대 별 비중 (0~100)
> ages_group_20 : 각 연령대 별 비중 (0~100)
> ages_group_30 : 각 연령대 별 비중 (0~100)
> ages_group_40 : 각 연령대 별 비중 (0~100)
> ages_group_50 : 각 연령대 별 비중 (0~100)
> ages_group_60 : 각 연령대 별 비중 (0~100)
> reply_l : 모든 댓글 수집 (그러므로 len(reply_l) 은 댓글의 개수!)
> title : 해당 뉴스의 제목
"""
def gogo_reply(url_ori, referer, news_id):
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.39.132 Safari/53.36',
'Referer': referer}
req = requests.get(referer, headers=headers)
soup = BeautifulSoup(req.text, 'html.parser')
title = soup.find('title').text
url_news = url_ori
req = requests.get(url_news, headers=headers)
reply_json = json.loads(req.text[req.text.find('{'):-2])
## 성별 통계정보 가져오기
gender_male = reply_json['result']['graph']['gender']['male']
gender_female = reply_json['result']['graph']['gender']['female']
## 연령 통게정보 가져오기
ages_group_10 = reply_json['result']['graph']['old'][0]['value']
ages_group_20 = reply_json['result']['graph']['old'][1]['value']
ages_group_30 = reply_json['result']['graph']['old'][2]['value']
ages_group_40 = reply_json['result']['graph']['old'][3]['value']
ages_group_50 = reply_json['result']['graph']['old'][4]['value']
ages_group_60 = reply_json['result']['graph']['old'][5]['value']
## 모든 댓글을 쌓을 reply_l 리스트 만들기
reply_l = []
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.39.132 Safari/53.36',
'Referer': url_news }
i = 0
# 모든 댓글이 수집될때 까지 반복.
while True:
i += 1
url = url_ori.split('objectId=')[0] + 'objectId=' + news_id + '&categoryId' +url_ori.split('objectId=')[1].split('&categoryId')[1].split('page=')[0] + 'page=' + str(i) + url_ori.split('objectId=')[1].split('&categoryId')[1].split('page=')[1][1:]
req = requests.get(url, headers=headers)
try:
reply_json = json.loads(req.text[req.text.find('{'):-2])
except:
reply_json = json.loads(req.text[42:-2])
if len(reply_json['result']['commentList']) != 0:
for comlist in reply_json['result']['commentList']:
reply_l.append(comlist['contents'])
else :
break
return gender_male, gender_female, ages_group_10, ages_group_20, ages_group_30, ages_group_40, ages_group_50, ages_group_60, reply_l, title
4. 반복적인 댓글 크롤링 실시!!
## 이번 코드는 2만개의 댓그이 모일때 까지 수집을 진행합니다.
while True:
# Naver 서버에 부하를 줄이기 위해 0.1초씩 쉬어가기
time.sleep(0.1)
## gogo_reply에 넣을 인자 만들기
num_ = '0' * (10- len(str(target_num ))) +str(target_num )
news_id = "news" + news_company + ","+ num_
referer = "https://news.naver.com/main/read.naver?oid=" + news_company + "&aid=" + num_
url_ori = 'https://apis.naver.com/commentBox/cbox/web_naver_list_jsonp.json?ticket=news&templateId=view_society&pool=cbox5&_wr&_callback=jQuery11240673401066245984_1638166575411&lang=ko&country=KR&objectId=' + news_id + '&categoryId=&pageSize=10&indexSize=10&groupId=&listType=OBJECT&pageType=more&page=1&initialize=true&userType=&useAltSort=true&replyPageSize=20&sort=favorite&includeAllStatus=true&_=1638166575413'
## 통계정보가 생성되지 않을경우에는 skip되며
## try: 에 에러가 안난경우는 통계정보가 생성된(댓글이 일정수준 이상 달린) 댓글입니다
try:
## 함수에서 나온 값을 받아 list에 추가
gender_male, gender_female, ages_group_10, ages_group_20, ages_group_30, ages_group_40, ages_group_50, ages_group_60, reply_l, title= gogo_reply(url_ori, referer, news_id)
title_l .append(title )
gender_male_l .append(gender_male )
gender_female_l.append(gender_female)
ages_group_10_l.append(ages_group_10)
ages_group_20_l.append(ages_group_20)
ages_group_30_l.append(ages_group_30)
ages_group_40_l.append(ages_group_40)
ages_group_50_l.append(ages_group_50)
ages_group_60_l.append(ages_group_60)
reply_all_l .append(reply_l)
crawl_time_l .append(datetime.now().strftime("%Y%m%d-%H%m"))
reply_cnt_l.append(len(reply_l))
news_id_l.append(news_id)
# 변수 List로 dataFrame만들고 저장!
df = pd.DataFrame()
df['news_id'] = news_id_l
df['title'] = title_l
df['gender_male'] = gender_male_l
df['gender_female'] = gender_female_l
df['ages_group_10'] = ages_group_10_l
df['ages_group_20'] = ages_group_20_l
df['ages_group_30'] = ages_group_30_l
df['ages_group_40'] = ages_group_40_l
df['ages_group_50'] = ages_group_50_l
df['ages_group_60'] = ages_group_60_l
df['reply_cnt'] = reply_cnt_l
df['reply_all'] = reply_all_l
df['crawl_time'] = crawl_time_l
## 저장해주기!!
df.to_pickle('naver_YTN')
print(len(df), ' ' ,title,' Reply num : ', len(reply_l))
# 이만 개의 댓글이 모였다면! 끝!!
if len(df) > 20001:
break
## 통계정보가 생성되지 않은 뉴스는 pass!
except KeyError :
print(num_, news_id, 'pass')
target_num = int(num_) - 1
3. 최종 결과
위의 코드로 3개의 댓글만 수집을 진행해 보았습니다!!^^


어떄요!! 네이버 댓글 수집하기!! 어렵지 않죠!?
참고하시 수 있게 ipynb 파일을 같이 업로드합니다!!^^
다음 포스팅에서는 이렇게 크롤링된 정보를 바탕으로
남성과 여성, 세대별 글쓰기 특성 알아보기 등 재미있는 분석들을 진행해보겠습니다!!
감사합니다.
'데이터&AI' 카테고리의 다른 글
| [재미로보는] 네이버로 알아보는 대통령후보 여론 (Feat. Clova) (1) | 2022.01.18 |
|---|---|
| 남자 vs 여자, 글쓰기 특징을 알아보자!!(feat. 네이버 댓글통계정보) (0) | 2022.01.16 |
| [판독기 시리즈] 당신의 얼굴로 밝혀지는 진실!! (0) | 2022.01.03 |
| [재미로보는] 네이버의 정치적 올바름 (Political Correctness) (Feat. Clova) (0) | 2021.12.30 |
| MongoDB 에러- 다른 프로세스가 파일을 사용 중이기 때문에 프로세스가 액세스 할 수 없습니다. (feat Windows) (0) | 2021.12.22 |




댓글