안녕하세요!!!
지난 포스팅에서 openai의 gpt api를 활용하여 문장 클러스터링 하는 방법을배워보았습니다!
2023.03.05 - [일등박사의 생각/데이터분석] - [PYTHON] openai의 gpt api를 활용하여 문장 클러스터링 하기
이번에는, 클러스터링을 넘어 나만의 텍스트 중요도 모델을 만들어보겠습니다!!
1. 모듈 임포트 및 선언
- 우선 openai의 api키 와 패키지들을 불러옵니다.
- 추가로 앞으로 대화내용을 지속 저장할 신규변수(conversation_history)를 만들어줍니다.
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
API_KEY = '{나의 API키}'
openai.api_key = API_KEY2. 테스트 문장 Set
- 이번 테스트에서는 아래와 같이 간단한 4개의 문장을 샘플로 정했습니다!
- 처음 2개 문장은 긍정(1)으로, 뒤 두개 문장은 부정(2)로 정하여 labels 의 변수에 저장!!
sentences = ["일등박사의 블로그는 최고입니다 ",
"일등박사 블로그에서는 블록체인, AI에 관한 유용한 정보를 잘 알수 있어요",
"나는 옆의 다른블로그가 더 좋던데",
"api로 하는것이 아니라 원천 모델을 만들줄 알아야지!?" ]
labels = [1,1,0,0]3. 테스트 문장 Set 을 기준으로 벡터 만들기
- 지난 포스팅과 유사하게, api를 활용하여 openai의 gpt모델 ada 기반의 벡터를 생성, embeddings에 저장합니다!
response_similarity = openai.Embedding.create(
input = sentences,
model = "text-similarity-ada-001")
print(response_similarity)
sentence_0 = response_similarity['data'][0]['embedding']
sentence_1 = response_similarity['data'][1]['embedding']
sentence_2 = response_similarity['data'][2]['embedding']
sentence_3 = response_similarity['data'][3]['embedding']
embeddings = [sentence_0, sentence_1,sentence_2,sentence_3]
4. logistic Regression으로 구분모델 제작
- 많은 분들이 익숙한 sikit-learn의 logisticRegression을 활용하여 모델을 만들어줍니다!
from sklearn.linear_model import LogisticRegression
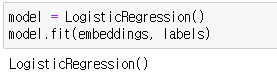
model = LogisticRegression()
model.fit(embeddings, labels)아래와 같이 모델이 잘 생성됩니다!!
4. Test 문장으로 검증
- 이젠, 새로운 테스트 문장을 만들어 검증을 진행합니다!
- 마찬가지로 문장들을 gpt api에 보내고 그 벡터값을 저장하여, 이미 생성된 모델이 적용해보는 것입니다!!
sentences_test = [ "별로 배울게 없네,, 다음엔 안와야지",
"일등박사 블로그를 통하여 잘배웠습니다 ",
"블록체인, AI에 관한 유용한 정보가 많아 좋았어요",
"원천 모델 만드는 법은 안알려주나요!??" ]
response_similarity = openai.Embedding.create(
input = sentences_test,
model = "text-similarity-ada-001")
print(response_similarity)
sentence_test_0 = response_similarity['data'][0]['embedding']
sentence_test_1 = response_similarity['data'][1]['embedding']
sentence_test_2 = response_similarity['data'][2]['embedding']
sentence_test_3 = response_similarity['data'][3]['embedding']
embeddings_test = [sentence_test_0, sentence_test_1,sentence_test_2,sentence_test_3]
model.predict(embeddings_test)결과는 어땟을까요!!?
아래의 이미지와 같이 긍정적인 내용에는 1, 부정적인 내용에는 0으로 잘 분류한 것을 확인할 수 있었습니다!@
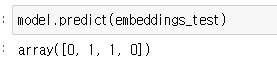
어떤가요!? 4개의 적은 데이터로 학습시켰지만, 결과적으로 좋은 모델을 만들 수 있었음을 확인할수 있었습니다!!
'데이터&AI' 카테고리의 다른 글
| [PYTHON] openai의 gpt api를 활용하여 문장 클러스터링 하기 (0) | 2023.03.05 |
|---|---|
| python API를 활용한 chatgpt- 과거내용 기억하기 (3) | 2023.03.05 |
| Python API를 활용하여 OpenAI 교육(파인튜닝, Fine tuning)하기 (0) | 2023.03.04 |
| OpenAI의 ChatGPT를 파이썬 API로 이용하기(gpt-3.5-turbo) (3) | 2023.03.04 |
| OpenAI의 ChatGPT가 예측한 비트코인의 미래 (feat Python) (0) | 2023.02.06 |




댓글