안녕하세요!!!
텍스트 분석의 기술이 날로 발전하고있습니다!!
과거의 형태소 분석을 통한 문장 클러스터링부터
직접 Bert로 언어모델을 만들고 벡터를 만들어 문장을 클러스터링하는 방법들이 등장했었습니다.
그런데!!!
OpenAI의 gpt api를 활용하여 더욱 쉽게 문장들을 클러스터링 할 수 있는것을아시나요?
오늘은 이 방법에 대하여 소개하고자합니다!!
1. 모듈 임포트 및 선언
- 우선 openai의 api키 와 패키지들을 불러옵니다.
- 추가로 앞으로 대화내용을 지속 저장할 신규변수(conversation_history)를 만들어줍니다.
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
API_KEY = '{나의 API키}'
openai.api_key = API_KEY2. 테스트 문장 Set
- 이번 테스트에서는 아래와 같이 간단한 4개의 문장으로 테스트해보겠습니다!!
sentences = ["일등박사의 블로그","티스토리 블그인 일등박사",
"gpt를 활용한 문장유사도 구하기", "gpt의 embedding 기능을 활용한 문장유사도" ]3. 테스트 문장 Set
- openai의 api를 활용하여 아래와 같이 텍스트들을 올립니다!!
response_similarity = openai.Embedding.create(
input = sentences,
model = "text-similarity-ada-001")
print(response_similarity)결과로 수많은 벡터가 저장되는데, 아래의 이미지와 같이 문장별 벡터값이 선언됨을 알 수 있습니다!
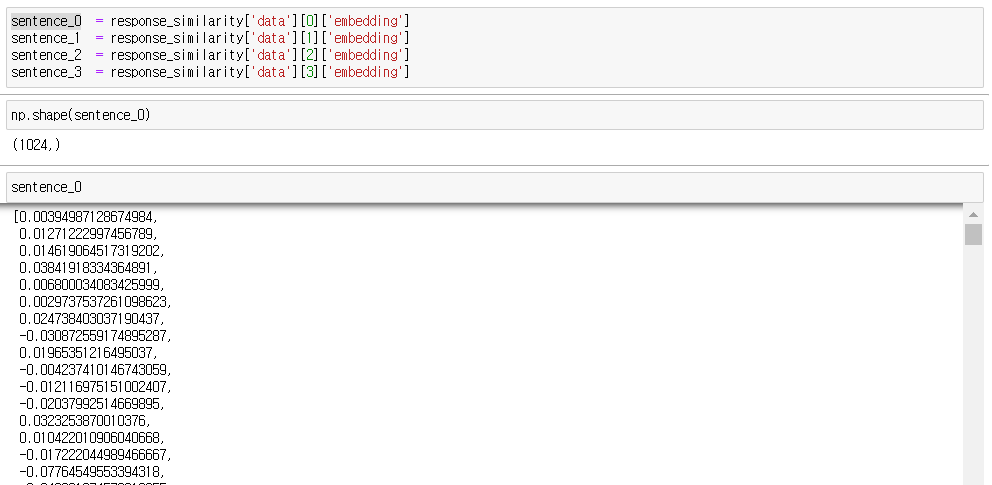
이번에 활용한 ada모델은 가장 간단한 모델로 1024개의 dimension을 가지고 있습니다!
실제 결과 벡터도 1024개의 축으로 구성되어 있습니다!!
(축이 적을수록 빠르고 값이 싸다는 장점이있지만,
반대로 세부적 분석및 정확도차원에서는 부족한 점이 있을것입니다!

4. 클러스터링하기t
- 이제, 위의 api를 통해 나온 결과값 벡터들을 sikit-learn의 KMeans 방법을 통하여 클러스터링 해줍니다!
embeddings = [sentence_0, sentence_1,sentence_2,sentence_3]
from sklearn.cluster import KMeans
num_clusters = 2
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(sentences[sentence_id])
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i+1)
print(cluster)
print("")
어떤가요!?
openai 의 gpt 모델을 활용하여
아래 이미지처럼 간단하고빠르게 클러스터링 된것을 확인할 수 있습나더!

'데이터&AI' 카테고리의 다른 글
| [PYTHON] openai의 gpt api를 활용하여 적은 데이터로 중요도 점수 모델 만들기 (0) | 2023.03.06 |
|---|---|
| python API를 활용한 chatgpt- 과거내용 기억하기 (3) | 2023.03.05 |
| Python API를 활용하여 OpenAI 교육(파인튜닝, Fine tuning)하기 (0) | 2023.03.04 |
| OpenAI의 ChatGPT를 파이썬 API로 이용하기(gpt-3.5-turbo) (3) | 2023.03.04 |
| OpenAI의 ChatGPT가 예측한 비트코인의 미래 (feat Python) (0) | 2023.02.06 |




댓글