OpenAI에서 저렴한 가격의 새로운 텍스트 임베딩 모델이 출시되어 소개포스팅을 작성하고자합니다!

1. text-embedding-3-small : 작고 효율적인모델
새로운 text-embedding-3-small 모델 : 2022년 12월 출시된 text-embedding-ada-002 모델보다 성능이 크게 향상된 작고 효율적인 텍스트 임베딩 모델
- 더 강력한 성능: 다국어 검색 벤치마크(MIRACL)에서는 평균 점수가 31.4%에서 44.0%로, 영어 작업 벤치마크(MTEB)에서는 평균 점수가 61.0%에서 62.3%로 증가
- 더 저렴한 가격: 이전 모델인 text-embedding-ada-002에 비해 5배 저렴한 가격(1,000 토큰당 $0.00002)으로 제공
* 이전 모델인 text-embedding-ada-002도 계속 사용 가능
2. text-embedding-3-large :크고 강력한 모델
text-embedding-3-large 모델은 최대 3072개 차원의 임베딩을 생성하는 새로운 차세대 대형 텍스트 임베딩 모델
- 더 강력한 성능: text-embedding-ada-002와 비교했을 때 MIRACL 벤치마크에서 평균 점수가 31.4%에서 54.9%로, MTEB 벤치마크에서 61.0%에서 64.6%로 증가
- 가격은 1,000 토큰당 $0.00013입니다. (small 比 6.5배 비싼!!)
임베딩 모델 활용 법은 이전 포스팅을 참고해주세요~!
2024.02.13 - [일등박사의 생각/데이터&AI] - [langchain공부]유로 임베딩 모델 사용하기!? (feat. OpenAI ada)
[langchain공부]유로 임베딩 모델 사용하기!? (feat. OpenAI ada)
많이 사용하는 huggingface의 BERT 모델! model_huggingface = HuggingFaceEmbeddings(model_name = 'jhgan/ko-sroberta-multitask' , model_kwargs = {'device':'cpu'} , encode_kwargs = {'normalize_embeddings' : True}) 위와 같은 방식으로 로드하
drfirst.tistory.com

3.shortening embeddings 기능 지원
InvalidDimensionException: Embedding dimension 1536 does not match collection dimensionality 768위와 같은 에러 본적 있으신가요!?
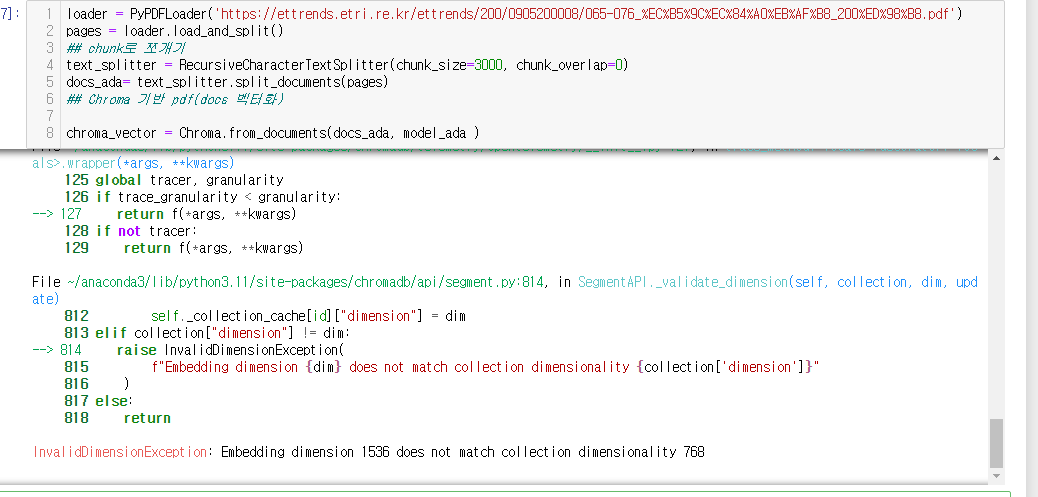
각각의 embedding의 dimensions 이 달라 발생하는 오류였는데요!!!
이번에 출시된 두 가지 새로운 임베딩 모델은 개발자가 성능과 비용을 절충할 수 있는 기술을 적용하여 훈련되었습니다.
이에 매번 embedding 사이즈를 바꾸어 API를 사용하면 위 에러를 해결할 수 있곘지요?

즉!! 사용자의 수요에 맞는 dimension의 모델을 사용할 수 있다는 것이지요!!!!
dimensions API 매개 변수를 통해 임베딩을 단축(즉, 시퀀스 끝에서 몇 개의 숫자를 제거)할 수 있으며, 이 과정에서 임베딩의 개념 표현 속성은 유지됩니다.
ㅁ 참고 : dimenson 의 차이는!@?
- 큰 임베딩 사용시 작은 임베딩을 사용하는 것보다 많은 비용/컴퓨팅, 메모리 및 저장 공간 사용.
- 예를 들어, MTEB 벤치마크에서 text-embedding-3-large 임베딩을 256 크기로 단축하더라도 크기가 1536인 단축하지 않은 text-embedding-ada-002 임베딩보다 성능이 우수
ㅁ 참고 : https://openai.com/blog/new-embedding-models-and-api-updates
'데이터&AI > LLM' 카테고리의 다른 글
| AI모델(GPT4)로 그림 및 사진 읽기 with python (0) | 2024.03.26 |
|---|---|
| 일론머스크의 AI, xAI의 오픈소스 LLM 사용해보기 (grok) (1) | 2024.03.19 |
| [OpenAI] GPT-3.5-turbo 가격인하!! (24.2.16~) (0) | 2024.02.16 |
| SERPAPI 알아보기!! (llm 의 필수 요소!!?) (1) | 2024.01.31 |
| Tavily(타빌리)는 무엇일까?? (인공지능을 통한 검색!) (1) | 2024.01.29 |




댓글