이번 포스팅은 유튜브 영상을 보고
Mixture of Experts LLM (MoE) 에 대하여 학습한 영상을 정리하고자합니다~~
Mixture of Experts (MoE) 의 정의

MoE 모델은?
- 언어 모델을 더 작고 특화된 하위 모델, 즉 전문가 모델들로 분해할 수 있다는 점에 기반을 두고 있다.
- 이 전문가 모델들은 각자 특정 부분을 처리하는 데 "특화되어 있어" 전체적인 계산 효율과 자원 할당을 개선
MoE 의 역사는?

> 2017년의 'Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer' (by google Brain)에서 시작
논문분석!! - 1
- 원문 URL : https://arxiv.org/pdf/1701.06538.pdf
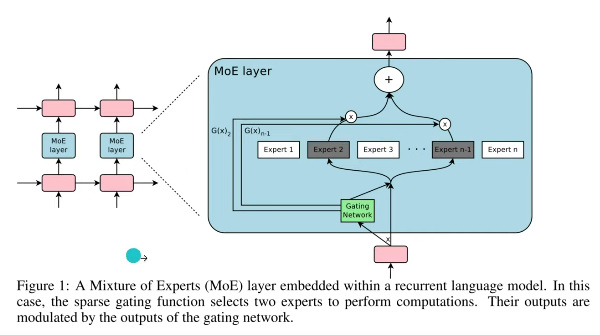
> 하늘색의 MoE Layer들로 구성
> 각각의 MoE Layer내에는 주황색의 Token이 들어옴
> Token 이 들어오면, 녹색의 Gating Network는 해당 Token을 어떤 Expert에 보낼지 결정
> 선정되는 Expert는 1개일수도, 2개일수도 있음
> Gating Network의 계산 방식으로는 2가지 방식을 제안
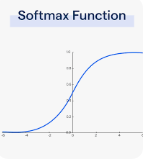
>(1) Softmax Gating

- 가장 원시적이고(1994년) 간단한 방법
- 훈련 가능한 가중치 행렬을 곱한 다음 softmax 적용.
- softmax : 최대 1 최소 0
>(2) Noisy Top-K Gating

>> Softmax gating에 노이즈와 top-k 추가
>> softmax 하기 전 우스 노이즈를 추가, top k 값만 선정하고 나머지는 마이너스 무한대로 설정!
( we add tunable Gaussian noise, then keep only the top k values, setting the rest to −∞)
>> Gate Network 훈련시키기!!!
역전파를 통해서
======> 여기까지가 2017년의 대략적인 현황!!
이제! 2022년으로 넘어옵니다!!
" MEGABLOCKS: EFFICIENT SPARSE TRAINING WITH MIXTURE-OF-EXPERTS"
논문분석!! - 2
- 원문 URL : https://arxiv.org/pdf/2211.15841.pdf
논문 2줄 요약
기존의 MoE의 한계를 지적하고브록의 수학적 연산관점에서 계산을 고도화하고
+ 블록분산메트릭구조 등 인프라관점에서도 고도화하였습니다!!
논문 세부!
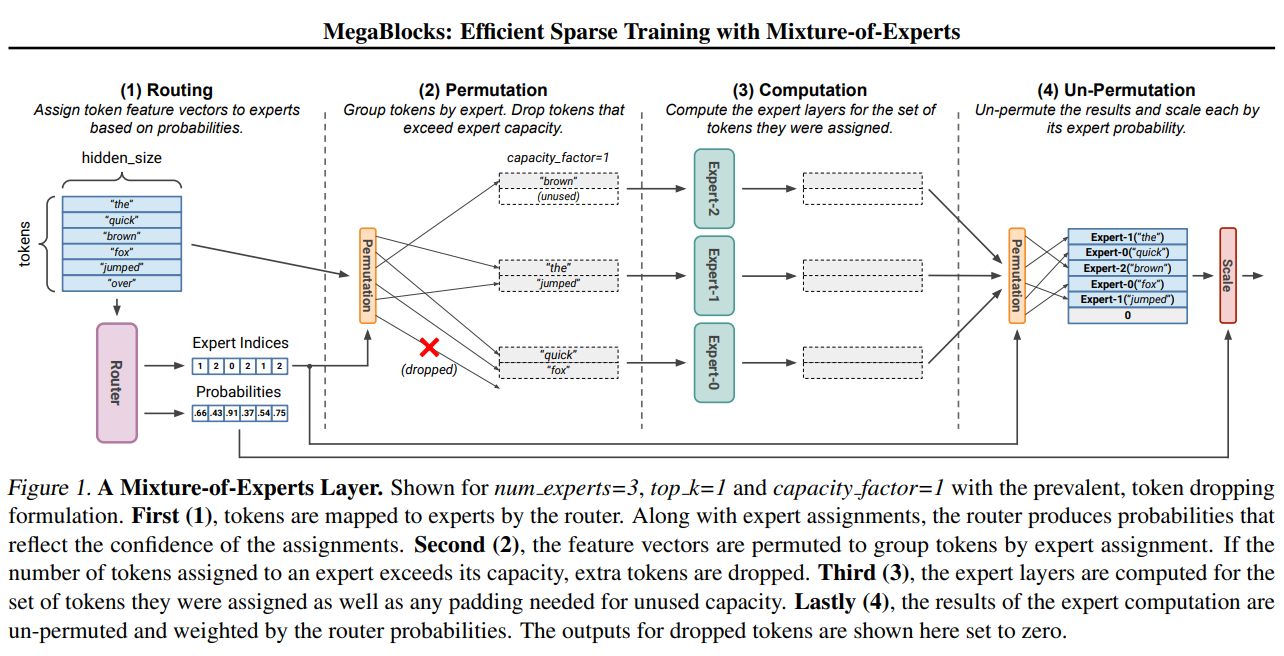
기존의 Gate가 Router(위 그림의 핑크색)로 진화, 전문가별 확률을 부여
> 현재 input과 전문가의 전문성을 기반, 여러 전문가에게 토큰 배포방법을 결정
이 Router 가 핵심요소임!!!
Router은 Neoral Network로 구성! 그 3가지 이유!!
1. Token Representation : 들어운 문장을 높은 차원(768,1024등)으로 변환. 의미와 맥락등을 포함 (transformer 구조)
2. Expertise Scoring : 토큰을 바탕으로 점수 부여. 각 전문가별 점수 부여 하고 그에 따라 관련성있는지 평가진행
3. Top-K Routing : 상위 점수를 받은 K전문가를 선정!! 1혹은 2 개의 전문가 선정
여기서 다시 Router 학습에 대한 문제가 필요.
(loss func를 최소화하는 학습을 진행. 전문가의 수행결과값이 target data)
여기서 발생하는 문제!!
1. Dynamic routing : routing을 dynamic하게 변경하려먼 어떻하지?
2. Load imbalanced computation : 불균형한 테이터문제를 어떻게해결해?
그래서 등장한!!!
sparse primitives!! > 희소한 데이터를 다루그 위한 연산법!!
이를 통해서 40% 이상 속도 가속화!!
block-sparse operation을 통해서 데이터수가 부족한 토큰데이터를 전문가에게 학습시킴!!
(dropless-MoEs : dMoEs)
2개 논문 분석결론!!
MoE는 컴퓨팅 능력의 향상 없이도 LLM 모델의 parameter수를 증가시키는 효과를 누릴 수 있다.
이때 Gating Network(Router)는 최적의 Expert k 개를를 찾는 역할을 한다!!
교실에는 50명의 학생과 7명의 선생님이 있다!!

상황)모든 학생이 선생님을 찾으면!? 선생님의 병목현상이 발생한다.
그럼 어떻게해?
학생들의 질문을 카테고리화 하고, 알맞은 선생님에게 보낸다!!
상황) 50명의 학생이 모두 수학에 질문하고싶어함. 선생님중 1명만 수학 선생님 나머지는 과학, 체육 등 관련없는 선생님임
어떻하지?
(기존의 프로세세스에서는)
여려명의 학생이 동일한 선생님을 찾가면 일부 학생들은 답을 얻을 수 없어, (tkoen dropping in MoEs)
대신, 모든 학생이 답을 잘 받을 수 있도록 제한된 학생을 한명의 선생님당 배정해줘야해. 즉 다른 선생님은 쉬게되는거지!!
(wasting computational resources)
(메가블록 방식에서는) block sparse method를 통해 선생님의 바쁜정도를 확인후 학생들을 배정

block sparse method는 행렬을 계산하는게 매우 간단해!!
dynamic routing을 통해서 여러 Expert에 배정할 수 있도록 함
4개의 운동장(블록)이 있다. 각 운동장에서는 축구 농구 배드민턴(주제) 등으로 활용.
이것이 하나의 block sparse 행렬로 구성되면 매우 빠르고 효율적으로 GPU 최적화하면서 계산됨!!
(기존방식) 각각이 3개의 운동장을 차지
(메가블록방식) 운동장의 크기 조절 가능.
마지막 논문!! 2023년!! 등장!!
Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
- 원문 URL : https://arxiv.org/pdf/2305.14705.pdf

논문 2줄 요약
명령어 튜닝으로 fine tuning을 진행!!!
기존의 MoE의 한계를 지적하고브록의 수학적 연산관점에서 계산을 고도화하고
+ 블록분산메트릭구조 등 인프라관점에서도 고도화하였습니다!!
핵심 아이디어:
이 연구는 대규모 언어 모델(LLM) 성능 향상을 위해 두 가지 기술을 결합하는 아이디어를 탐구합니다.
- Mixture-of-Experts (MoE): 이는 추론 과정에서 계산 비용을 증가시키지 않고 LLM에 더 많은 학습 가능한 매개 변수를 추가할 수 있도록 하는 신경망 아키텍처입니다.
- Instruction Tuning: 이 기술은 LLM을 자연어로 제공된 특정 지침을 따르도록 훈련하는 것을 포함합니다.
이 논문은 MoE 모델이 전통적인 밀집 LLM 아키텍처에 비해 지침 조정에서 더 많은 이점을 얻는다고 주장합니다.
MoE 및 Instruction Tuning 결합의 장점:
- 향상된 성능: 이 논문에서는 MoE 모델과 지침 조정이 MoE 모델만 사용하거나 지침 조정을 사용하는 밀집 LLM 모델보다 다양한 작업에서 더 나은 성능을 달성한다는 것을 발견했습니다.
- 향상된 일반화: MoE와 지침 조정의 조합은 모델이 명시적으로 훈련되지 않은 작업(제로 샷 및 소수 샷 학습)에서도 성능 향상을 가져왔습니다.
요약
MoE 작동 방식:
- 입력 데이터: 텍스트, 이미지, 음성 등 다양한 데이터를 입력으로 사용할 수 있습니다.
- 전문가 모델: 각 전문가 모델은 특정 유형의 데이터를 처리하는 데 특화되어 있습니다. 예를 들어, 이미지 전문가 모델은 이미지를 처리하고, 텍스트 전문가 모델은 텍스트를 처리합니다.
- 게이팅 네트워크: 게이팅 네트워크는 각 전문가 모델이 얼마나 중요한 역할을 하는지 결정합니다. 마치 오케스트라 지휘자가 각 악기 연주자의 역할을 조율하는 것과 비슷하다고 생각하면 됩니다.
- 최종 예측: 게이팅 네트워크가 결정한 중요도를 바탕으로 각 전문가 모델의 예측 결과를 종합하여 최종 예측을 도출합니다.
MoE의 장점:
- 더 나은 성능: 단일 모델보다 더 높은 정확도를 달성할 수 있습니다.
- 효율성 향상: 여러 모델을 따로 학습시키는 것보다 효율적입니다.
- 적응성: 새로운 데이터나 작업에 쉽게 적응할 수 있습니다.
MoE의 단점:
- 복잡성: 단일 모델보다 구현 및 학습이 더 복잡합니다.
- 해석 가능성: 모델의 작동 방식을 이해하기 어려울 수 있습니다.
MoE 활용 분야:
- 자연어 처리: 기계 번역, 챗봇, 문서 요약
- 컴퓨터 비전: 이미지 분류, 객체 인식
- 음성 인식: 음성 번역, 음성 명령
MoE 관련 자료:
- MoE 논문: https://arxiv.org/abs/1706.06914
MoE는 인공지능 분야에서 떠오르는 핵심 기술입니다. MoE를 이해하고 활용하는 것은 미래 인공지능 시대를 살아가는 데 중요한 역할을 할 것입니다.
ㅁ참고논문 : https://arxiv.org/abs/1701.06538
ㅁ 참고영상 : https://www.youtube.com/watch?v=_1ZDypfDOoU
'데이터&AI > LLM' 카테고리의 다른 글
| Gemini-advanced 사용해보기@ (feat. google AI premium 요금제) (0) | 2024.04.24 |
|---|---|
| llama3 무료로 쉽게 사용해보기 (feat. huggingface) (1) | 2024.04.19 |
| AI모델(GPT4)로 그림 및 사진 읽기 with python (0) | 2024.03.26 |
| 일론머스크의 AI, xAI의 오픈소스 LLM 사용해보기 (grok) (1) | 2024.03.19 |
| OpenAI !! 새로운 text 임베딩 모델 출시 (text-embedding-3) (1) | 2024.02.17 |




댓글