세션1은 교수님들의 강의로 진행되었습니다.
2024.05.16 - [데이터&AI/LLM] - [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!!
솔라 가입 및 간단한 시작!! 아래글을 참고로 세팅을 마쳤습니다!
2024.05.16 - [데이터&AI/LLM] - upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의)
upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의)
2024.05.16 - [데이터&AI/LLM] - [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!! [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!!https://kiise.or.kr/conference/conf/147/ 한국정보과학회 - 학
drfirst.tistory.com
langchain의 핵심!! PromptTemplate로 invoke하기!!
llm의 패키지 langchain의 핵심은!!
바로!! PromptTemplate 이다!!
코드부터보자!!!
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"나에게 {animals}와 관련된 {story} 이야기 해줘."
)
prompt_template.format(animals="개구리", story="무서운")
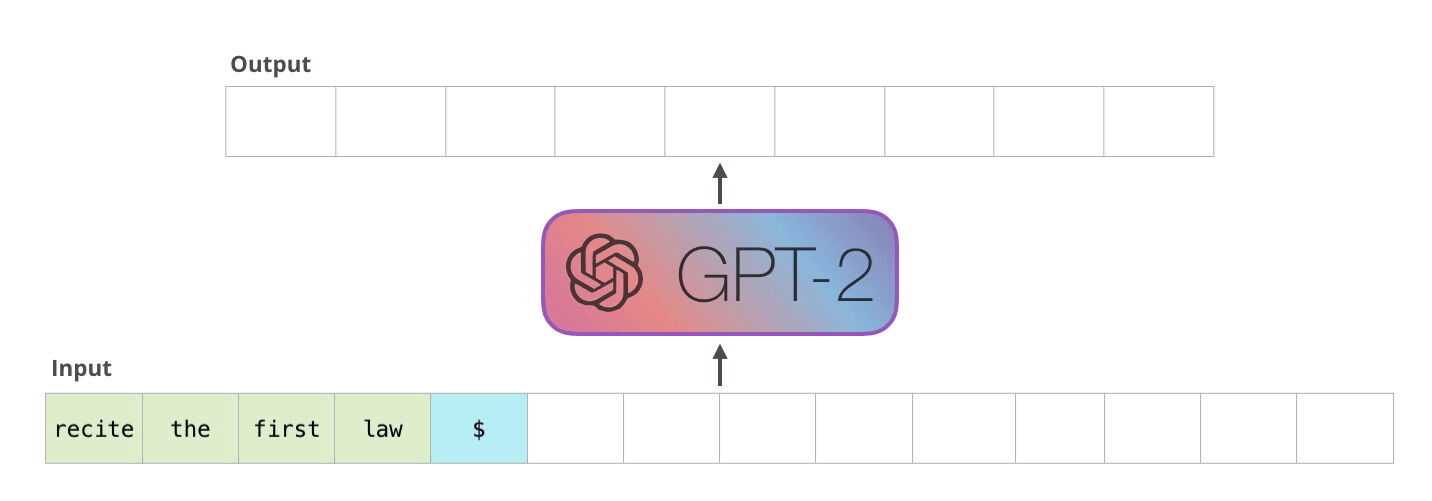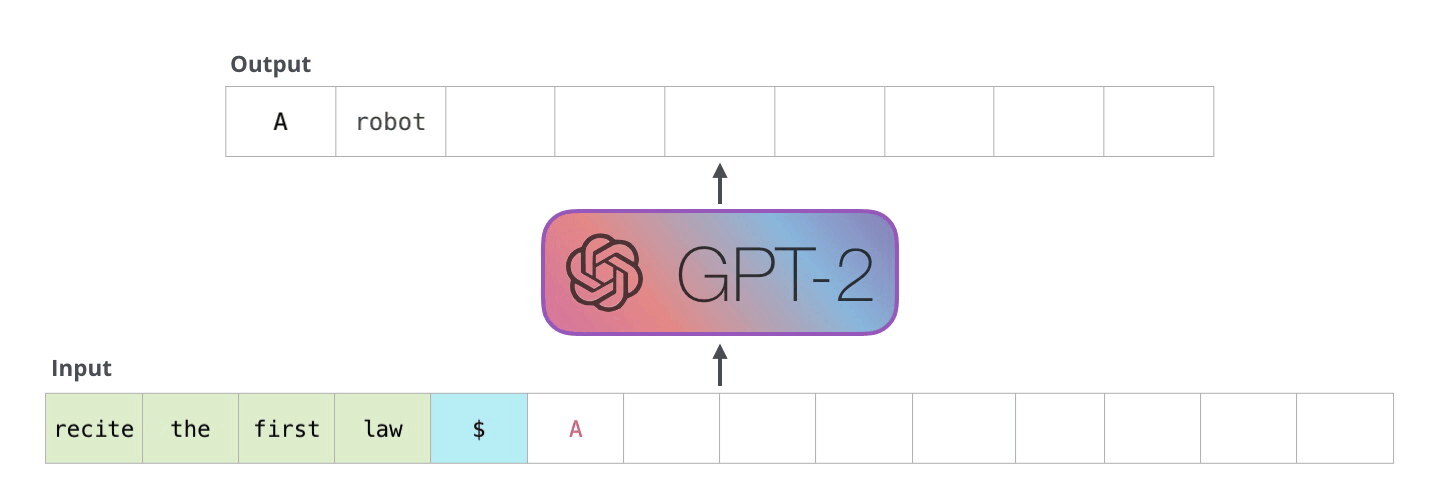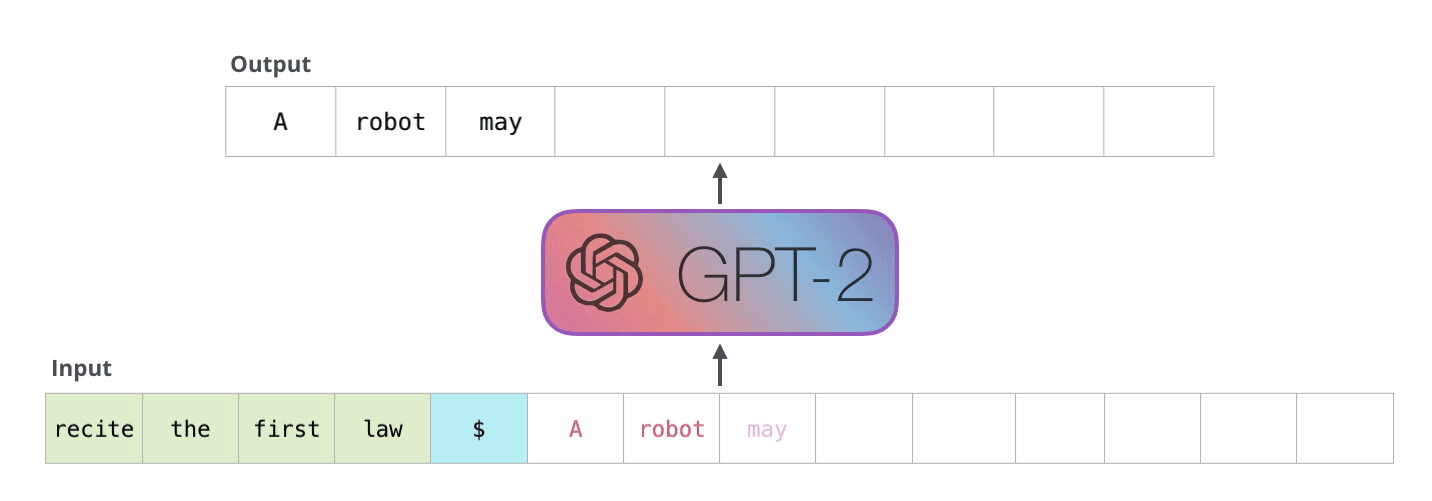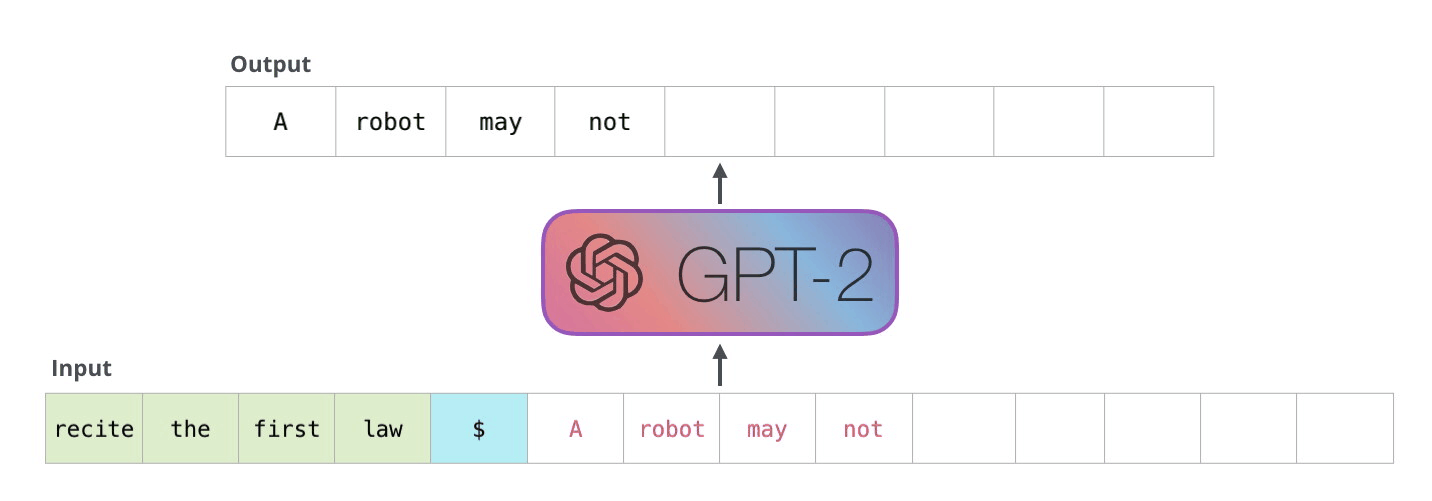
위 코드를 실행하면!?
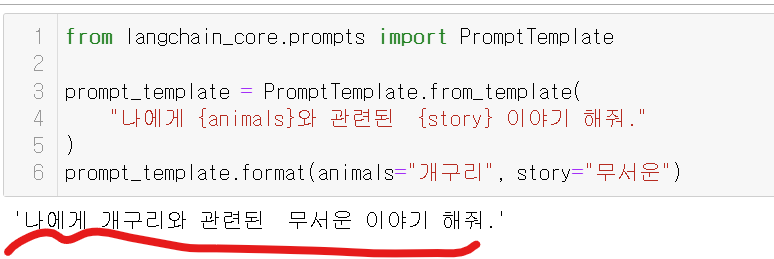
템플릿에 변수를 넣어서 완성해준다! 아주 간단하죠~?
# 환경변수 세팅!! .env에 api key가 저장되어야 있어야 합니다!!
from langchain_upstage import ChatUpstage
llm = ChatUpstage()
llm.invoke("What's the best season to get to Korean?")
chain = prompt_template | llm | StrOutputParser()
chain.invoke({"animals": "개구리", "story": "무서운"})
바로 invoke 해봅시다!!
결과는??
'한 번은 숲 속에 작은 오두막에 사는 외로운 노인이 있었습니다.
그는 숲에서 발견한 개구리를 애완동물로 키우고 있었습니다.
개구리는 노인에게 큰 위안이 되었고, 그들은 함께 행복한 시간을 보냈습니다.
어느 날, 노인은 숲에서 나무를 베고 돌아오는 길에 개구리가 없어진 것을 깨달았습니다.
그는 걱정하며 개구리를 찾아 헤맸지만, 어디에도 찾을 수 없었습니다.
그 후로, 노인은 매일 밤 개구리의 울음소리를 듣기 시작했습니다.
그 소리는 점점 더 가까워지고, 노인은 불안감에 사로잡혔습니다.
그는 개구리가 그에게 무언가를 전하려는 것 같은 느낌을 받았습니다.
어느 날 밤, 노인은 개구리의 울음소리를 따라 숲 속으로 들어갔습니다.
그리고 그는 개구리가 나무 위에 앉아 있는 것을 발견했습니다.
개구리는 노인에게 말을 걸며, 숲 속에 숨겨진 보물에 대해 이야기했습니다.
노인은 개구리의 말을 믿고, 보물을 찾기 위해 숲을 뒤지기 시작했습니다.
그리고 그는 실제로 보물을 발견했습니다.
그러나 그 보물은 저주받은 것이었고, 노인은 그 보물을 소유함으로써 저주에 걸렸습니다.
노인은 개구리의 경고를 듣지 않고 보물을 가져간 것을 후회하며,
저주받은 보물을 다시 돌려놓기 위해 노력했습니다. 그러나 이미 늦었습니다.
노인은 저주에 걸려 숲 속에서 영원히 갇혀 살게 되었습니다.
이 이야기는 개구리와 관련된 무서운 이야기입니다.
개구리는 우리에게 경고와 경계를 주는 존재일 수 있으며,
우리는 그들의 말을 경청해야 한다는 교훈을 전해줍니다.'
바로 무시무시한 이야기를~~ 알려줍니다!
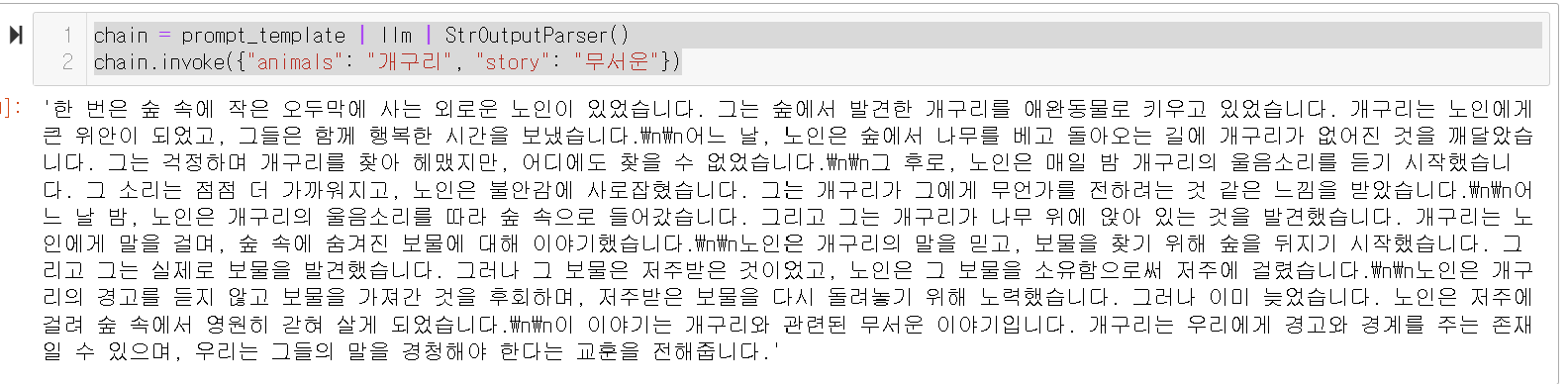
이렇게 langchain 기술로 모두가 행복했습니다~~~
면 좋았겠찌만!!
모두가 잘아는 환각, 할루시네이션 현상이 발생하게 됩니다!
Hallucination

왜냐면 GPT의 구조가 통계적으로 가장 가능성 높은 토큰을 말하기떄문입니다!!
CAG의 등장!!
그래서 사람들은 생각합니다!!
먼저 내용을 알려주고,
"아는거만 대답하고, 모르는것은 대답하지자!!!"
라구하면 어떨까??
그렇게 CAG (Context-Augmented Generation) 가 등장하게 됩니다!!
코드 예시!! (DUS에 대하여 물어보기!!)
from langchain_core.prompts import PromptTemplate
from langchain_upstage import ChatUpstage
from langchain_core.output_parsers import StrOutputParser
llm = ChatUpstage()
prompt_template = PromptTemplate.from_template(
"""
제공 텍스트 에서 아래 키워드와 관련된 내용을 알려줘
키워드 "{keyword}":
---
제공텍스트
{text}
"""
)
chain = prompt_template | llm | StrOutputParser()
keyword = "DUS"
text = """
SOLAR 10.7B: 단순하지만 효과적인 깊이 확장을 통한 대형 언어 모델의 확장
우리는 SOLAR 10.7B를 소개합니다.
이 모델은 107억 개의 파라미터를 가진 대형 언어 모델(LLM)로,
다양한 자연어 처리(NLP) 작업에서 우수한 성능을 보여줍니다.
최근의 LLM 효율적 확장 노력에서 영감을 받아, 우리는 깊이 확장(DUS)이라는 LLM 확장 방법을 제안합니다.
DUS는 깊이 확장과 지속적인 사전 학습을 포함합니다.
전문가 혼합(mixture-of-experts)을 사용하는 다른 LLM 확장 방법과 달리,
DUS는 효율적으로 훈련하고 추론하기 위해 복잡한 변경이 필요하지 않습니다.
우리는 실험을 통해 DUS가 작은 모델에서 높은 성능의 LLM으로 확장하는 데 단순하지만 효과적임을 보여줍니다.
DUS 모델을 기반으로, 우리는 추가적으로 명령을 따르는 능력으로 미세 조정된 변형인 SOLAR 10.7B-Instruct를 소개합니다.
이 모델은 Mixtral-8x7B-Instruct를 능가합니다. SOLAR 10.7B는 Apache 2.0 라이선스 하에 공개되어,
LLM 분야에서의 광범위한 접근과 응용을 촉진합니다.
"""
chain.invoke({"keyword": keyword, "text": text})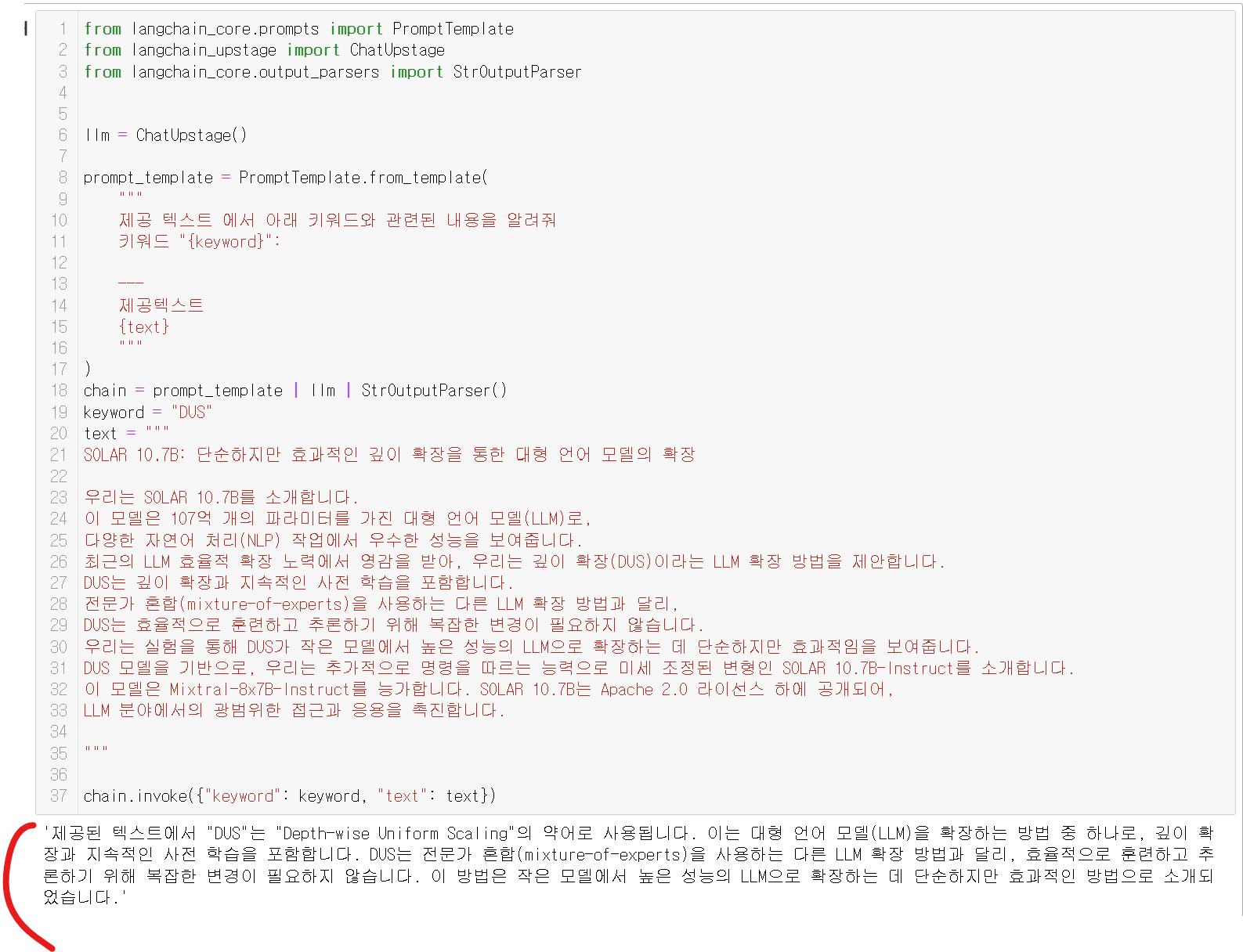
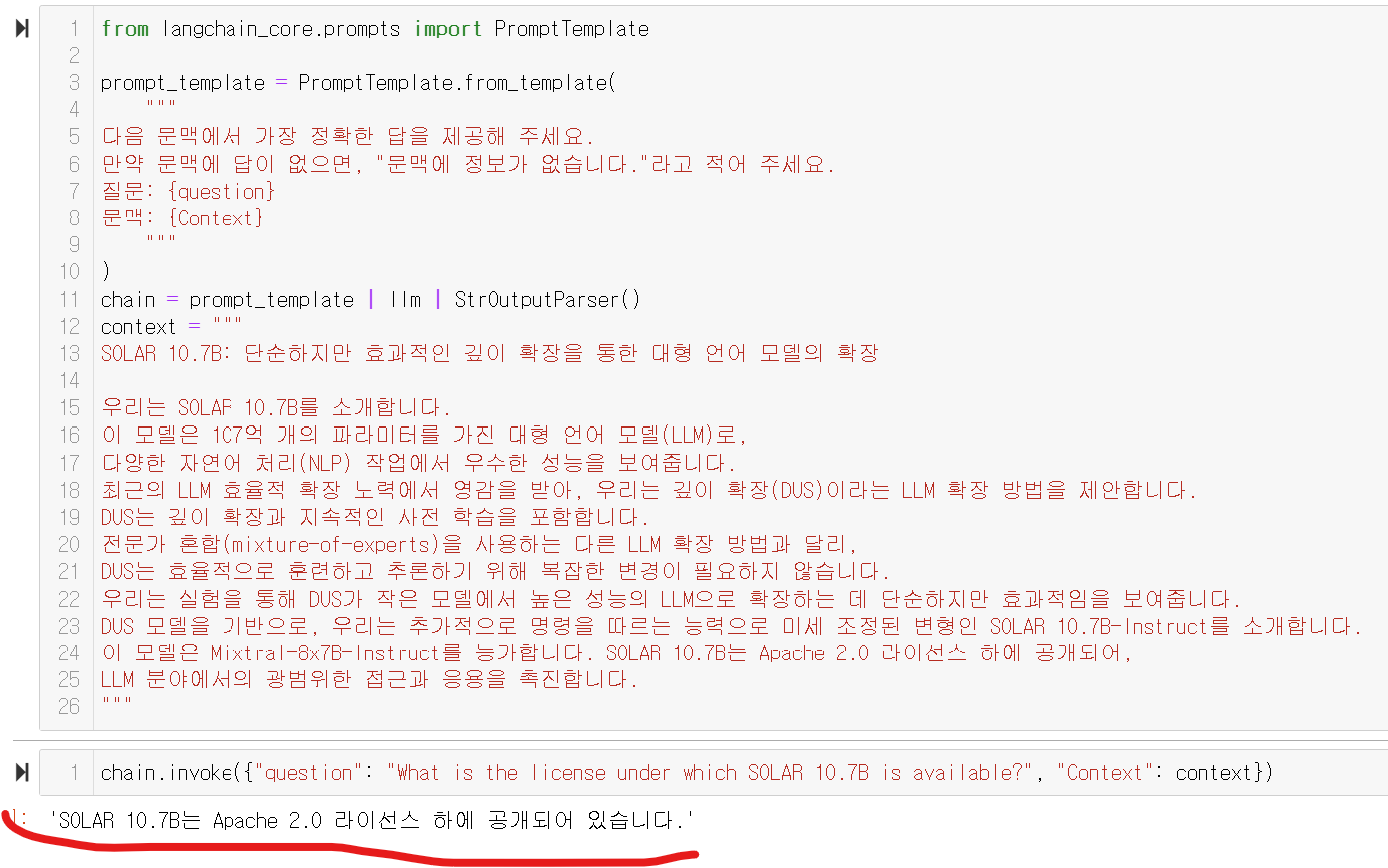
그럼 이친구한테 새로운 용어인 axFT에대하여 물어보면??

모른다고 말합니다!!
Groundedness Check (진짜야?)
콩으로 메주를 쑨대도 못 믿는다
여러분은 남을 잘 믿으시나요??
GPT는 잘 믿으실수 있나요??그래서 등장한 개념이 바로 Groundedness Check입니다.
Groundedness Check는 AI 시스템, 특히 언어 모델이 생성하는 정보의 신뢰성과 정확성을 평가하는 개념입니다.
이 개념은 주로 언어 모델이 생성한 텍스트가 실제 세계의 사실에 근거하고 있는지,
즉 'grounded'되어 있는지를 확인하는 데 사용됩니다.
Groundedness Check는 AI 응용 프로그램에서 중요한 역할을 하며,
특히 정보의 정확성과 신뢰성이 중요한 분야에서 그 중요성이 더욱 부각됩니다.
python code로 groundednes_check를 알아봅시다!!
# GC
from langchain_upstage import UpstageGroundednessCheck
groundedness_check = UpstageGroundednessCheck()
answer = chain.invoke(
{
"question": "What is the name of the variant fine-tuned for instruction-following capabilities?",
"Context": context,
}
)
print(answer)
gc_result = groundedness_check.invoke({"context": context, "answer": answer})
print(gc_result)
if gc_result.lower().startswith("grounded"):
print("✅ Groundedness check passed")
else:
print("❌ Groundedness check failed")
위 와같이
gc_result = groundedness_check.invoke({"context": context, "answer": answer})
결과물을 한번 더 체크하여!! 결과가 잘나오면 grouded로 이상하면 다른말로합니다!!
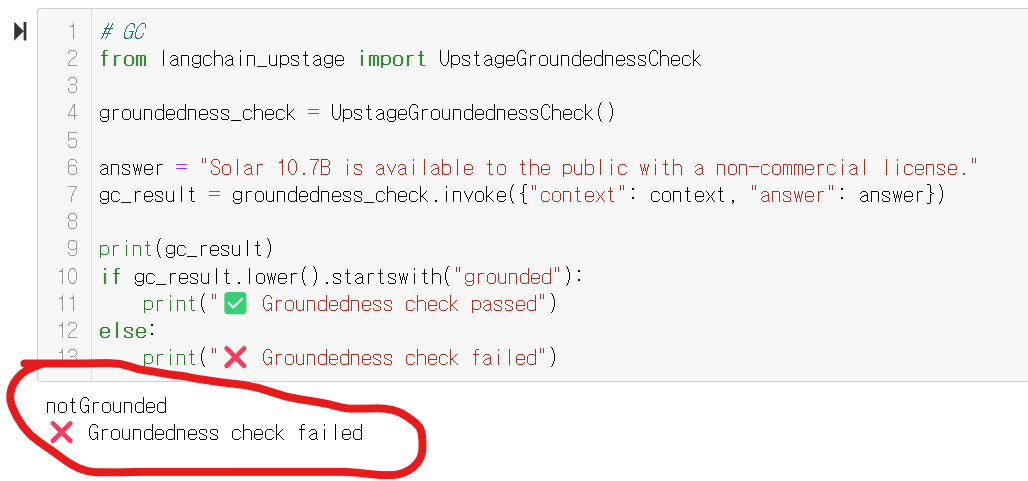
반대의 예시로 아래와 같이 " Solar 10.7B는 비상업적 라이선스로 대중에게 제공됩니다." 라는 제시된 문장과 반대되는말을 넣고
grounded check를 해보면!!
# GC
from langchain_upstage import UpstageGroundednessCheck
groundedness_check = UpstageGroundednessCheck()
answer = "Solar 10.7B is available to the public with a non-commercial license."
gc_result = groundedness_check.invoke({"context": context, "answer": answer})
print(gc_result)
if gc_result.lower().startswith("grounded"):
print("✅ Groundedness check passed")
else:
print("❌ Groundedness check failed")
모델이 깔끔하게!! 잘못됬어!! 라고이야기해줍니다!
PDF CAG (파일도 CAG할수있어??)
이젠!!! PDF도 텍스트로 읽어오면 가능하겠지?
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("pdfs/solar_sample.pdf")
PyPDFLoader를 활용하면 손쉽게 pdf파일을 문서화하여 작업을 할수 있습니다!!
그런데!!
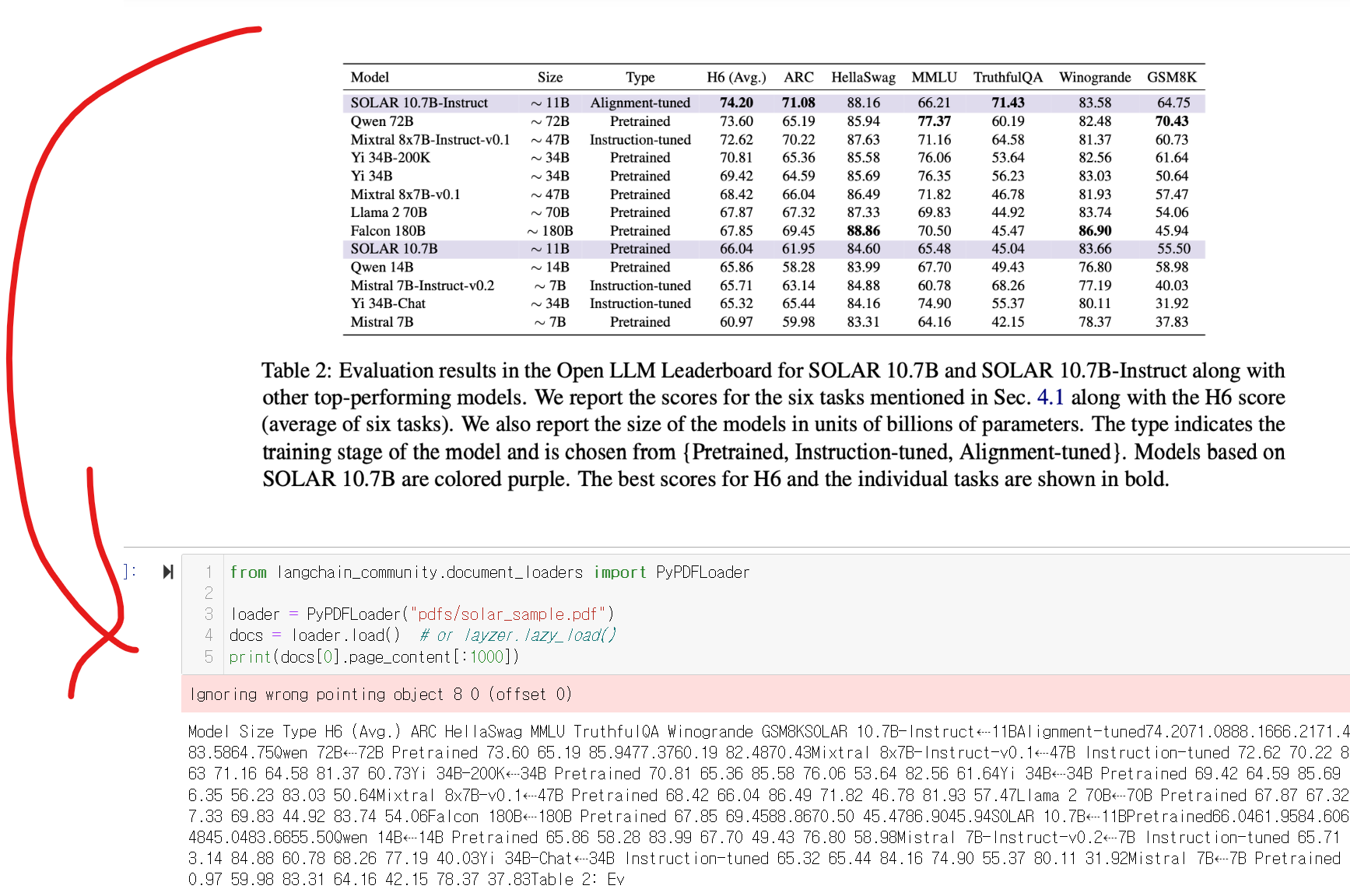
pdf를 학습해서 결과를 내긴하는데, 표나 이미지가있을경우!!
값을 잘 못내고,,이상한 답을 합니다!!
그래서!! 이런 PDF표를 잘 못읽는 방법을 해결하는 방법을 찾았습니다
from langchain_upstage import UpstageLayoutAnalysisLoader바로 업스테이지의
UpstageLayoutAnalysisLoader 를 활용한는것입니다!
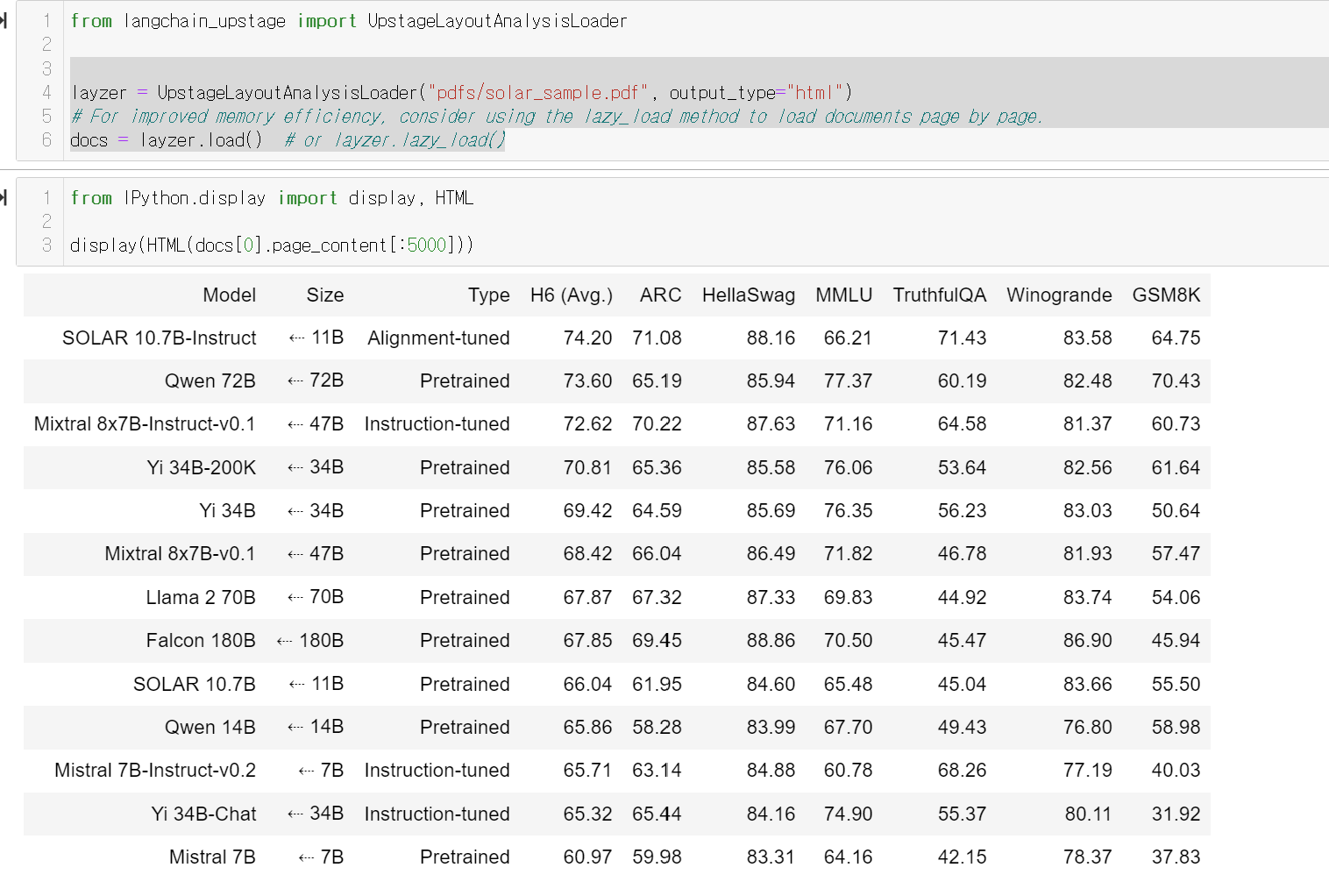
어떄요! 성능이 어마어마하죠!?
있어보이는기법, RAG의 등장!!
cag를 배웠는데,
원문이 어마어마하게 길먼 어떻해????
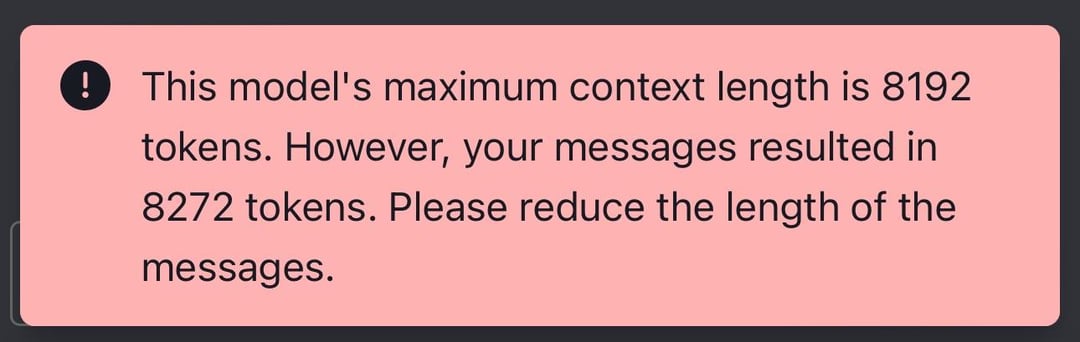
그냥 넣어버리면 모델에서는 위와 같이!! 너무길어요, 못헤요ㅠㅠ 합니다!!
그럴떄는!!
우선 필요한 부분을 검색하고, 그 부분에서만 CAG를 하면 되겠지!???
아래 PDF파일을 cag하려면 어떻게해야할까요!??
청킹!?
chunking!!
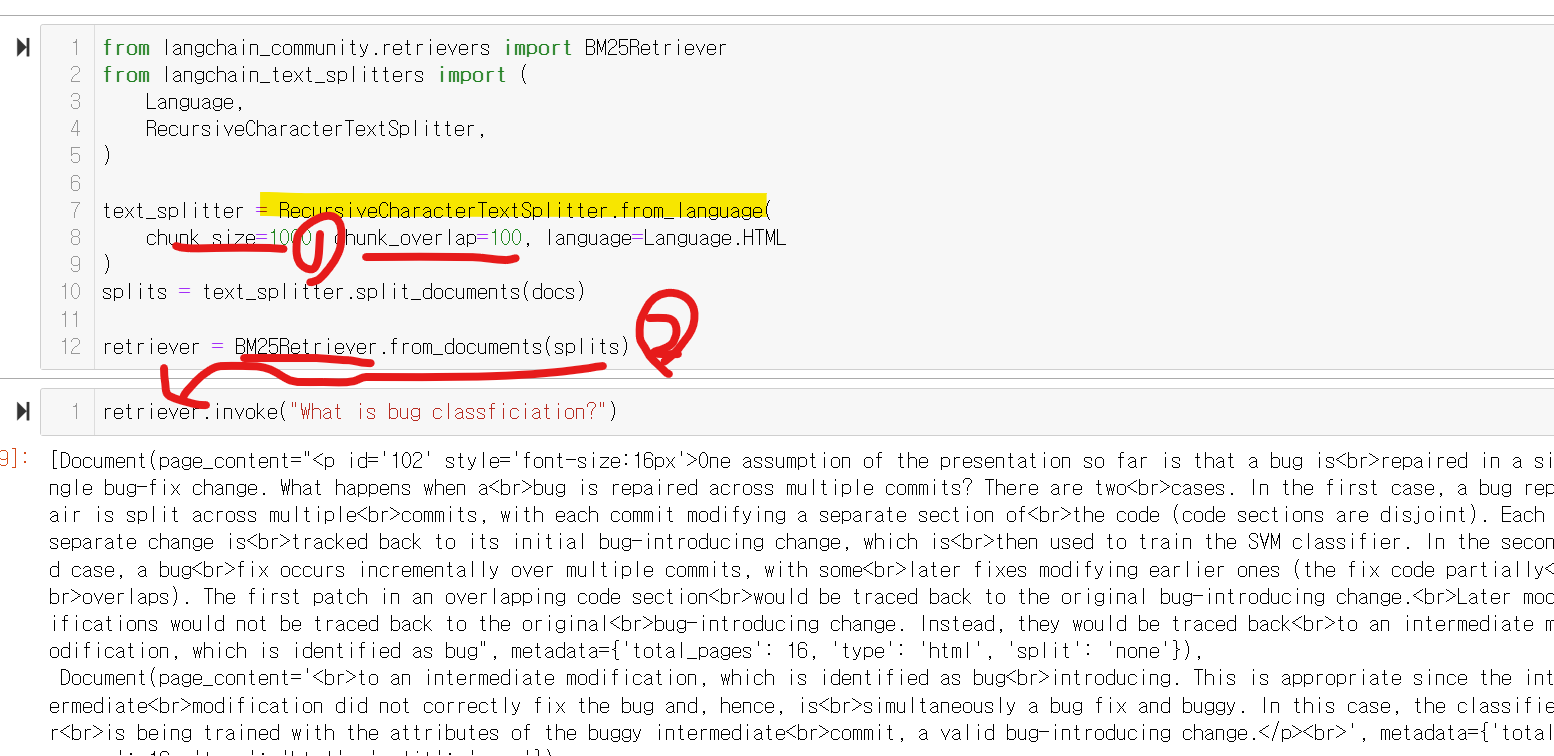
1. 문서를 청킹(쪼개기) 합니다! 이때 1000개의 조각으로, 100만큼 겹치게 진행했습니다
2. 그 다음은, 쪼갠 문서에서 검색을 진행합니다!! 검색은 BM25방식으로 진행합니다!!
| @BM25방식이란?? BM25 (Best Matching 25)는 정보 검색 분야에서 널리 사용되는 순위화 함수입니다. 이 함수는 특정 쿼리에 대해 문서의 관련성을 평가하고 순위를 매기는 데 사용됩니다. BM25는 BM25 계열의 여러 확장된 모델 중 하나로, 특히 텍스트 데이터베이스 검색 엔진에서 검색 품질을 향상시키는 데 널리 사용됩니다. TF-IDF (Term Frequency-Inverse Document Frequency)의 개념을 기반으로 합니다!!! |
>> 여기까지 정리하면, 질문을 넣으면, 그 질문에 가장 가까운 문서를 찾아서옵니다!!
이젠? 그 문서를 넣어서 cag해야겠쬬?
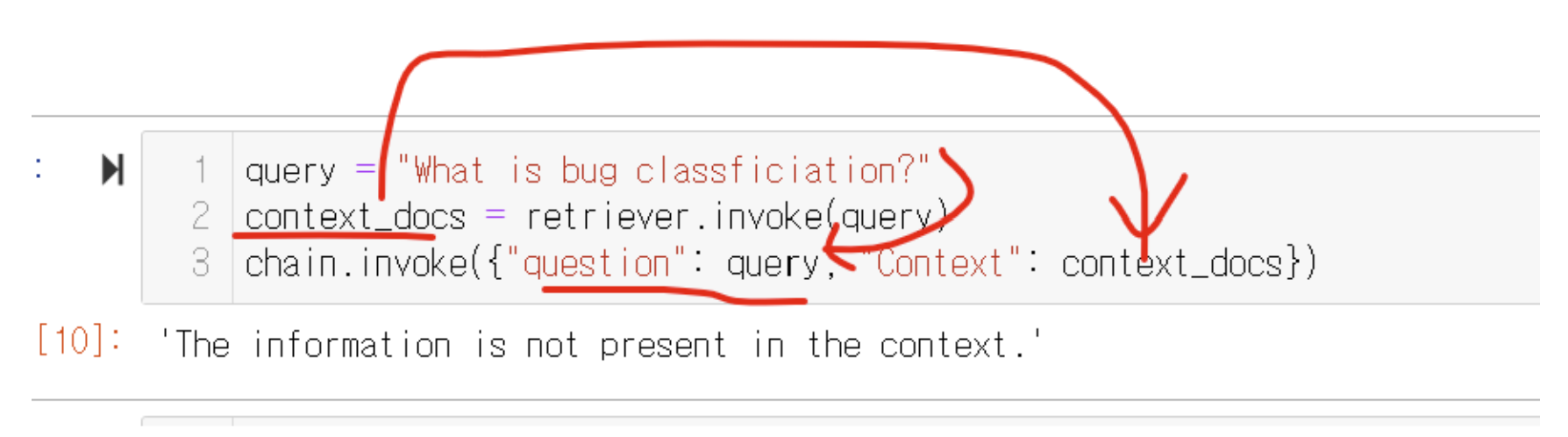
검색한 결과물을 context_docs에, 그리고 쿼리를 넣습니다!!
그런데,, 왜 결과물이 이렇게 안죻조???
다시한번, bug로 보면??

너무나 잘해요!!^^ 왜그럴까요!,,,
bm25의 한계에서 이 문제가 발생하는데요~~
검색의 고도화 : embeding!!
방금까지는 bm25, 검색을 단어 빈도 기반으로 헀다면,
이제는 문장을 수치화해서!! 진행합니다!!
복잡하나요? 아니요! 코드로는 간단합니다!!
ChromaDB를 사용해보아요!
from langchain_chroma import Chroma
# 3. Embed & indexing
vectorstore = Chroma.from_documents(documents=splits, embedding=UpstageEmbeddings(model="solar-embedding-1-large", embed_batch_size=100))
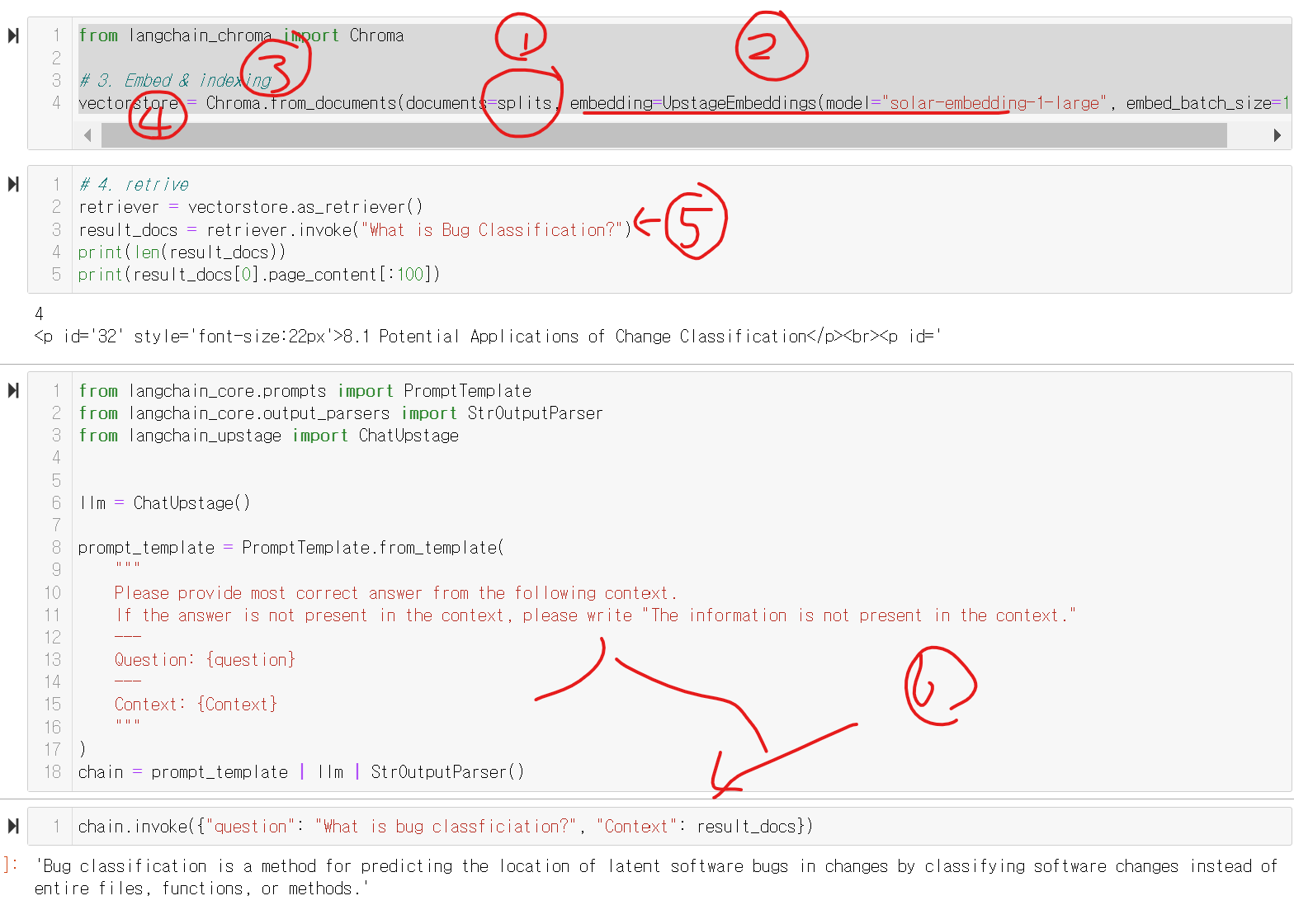
위 코드를 설명하자면!!
1. splits으로 저장된 원문들을
2. solar-embedding-1-large의 임베딩 모델을 바탕으로
3. chromaDB 방식으로
4. vectorstore에 저장합니다
그럼!!
5번과 같이 질문의 검색결과를 볼 수 있고!!
6과같이 검색결과를 바탕으로 cag를 진행, 잘된 답변을 확인할 수 있습니다!!!
chunk size는 1000개, chunk_overlap은 100 정도를 추천합니다!! (성킴 대표님의 말씀!!^^)
그리고 이런 embedding와 bm25를 더하는 앙상블 방식도 있습니다!!

ensemble_retriever = EnsembleRetriever(
retrievers = [bm25_retriever,chroma_retriever]
, weight = {0.5,0.5})
오키 굿 근대 모르면 모른다구 하면 안되?ㅠㅠ

llm의 문제!! 모르면 모른다구하면되는데,
rag해서 없으면 없다구하며되는데,
없어도 자꾸 자기 아는것만 가지고 대답을한단말이에요!!
그레서!! 이 내용이 여기 있는지 보고 말해!!의 기법이
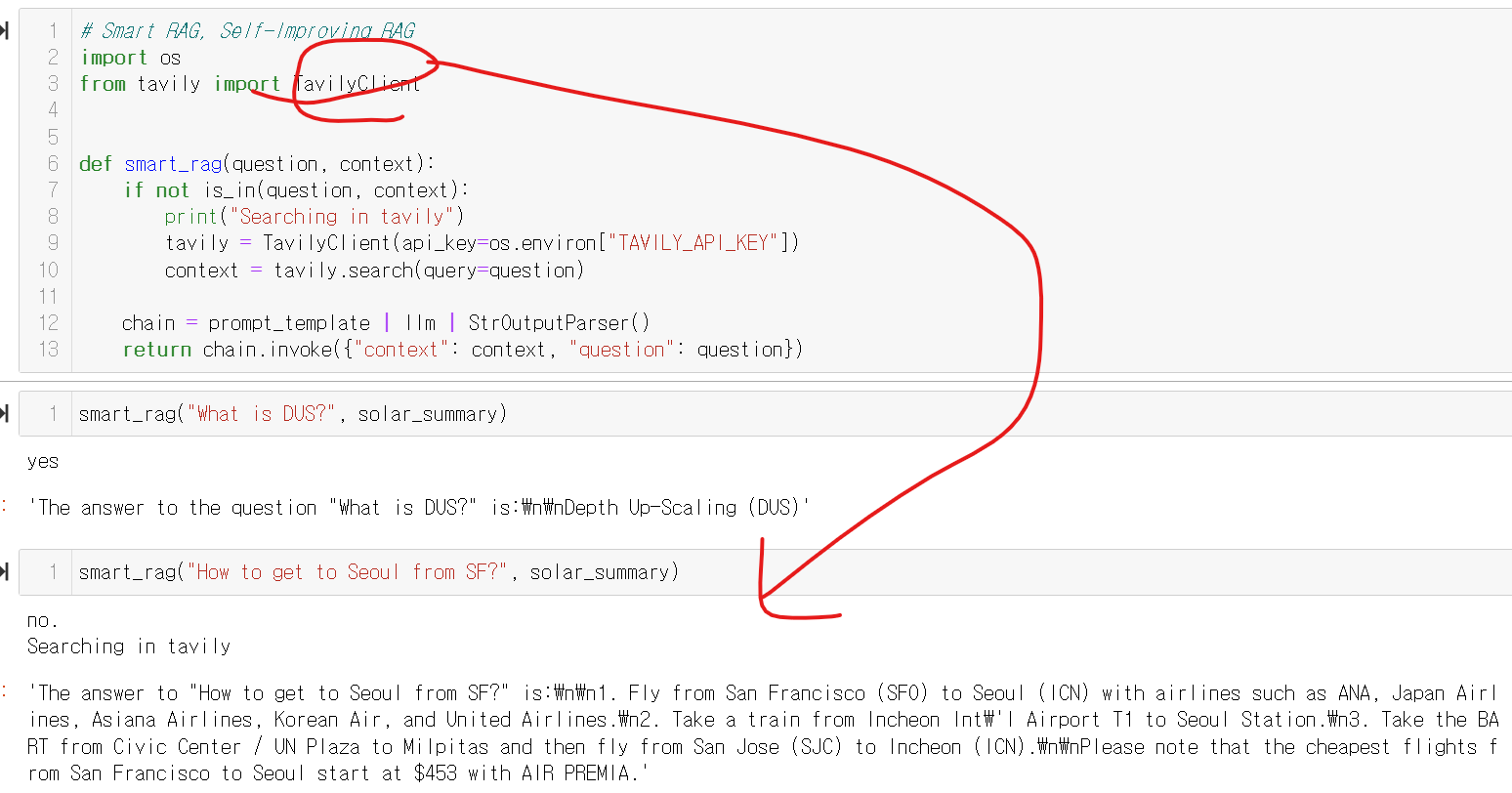
SMART RAG
입니다!
프롬프트를 볼까요?ㅎㅎ
== 한국어버젼
도움이 되는 어시스턴트로서, 질문에 대한 답이 주어진 문맥에 있는지 판단해 주세요.
답이 문맥에 있으면 "예"라고 응답해 주세요.
없으면 "아니오"라고 응답해 주세요.
"예" 또는 "아니오"만 제공하고 추가 정보를 포함하지 마세요.
최선을 다해 주세요. 다음은 질문과 문맥입니다:
문맥: {context}
질문: {question}
=== 영어버젼
As a helpful assistant,
please use your best judgment to determine if the answer to the question is within the given context.
If the answer is present in the context, please respond with "yes".
If not, please respond with "no".
Only provide "yes" or "no" and avoid including any additional information.
Please do your best. Here is the question and the context:
---
CONTEXT: {context}
---
QUESTION: {question}
---
OUTPUT (yes or no):
그래서 위 프롬포트를 바탕으로 is_in 이라는 함수를 만듭니다
# RAG or Search?
def is_in(question, context):
is_in_conetxt = """As a helpful assistant,
please use your best judgment to determine if the answer to the question is within the given context.
If the answer is present in the context, please respond with "yes".
If not, please respond with "no".
Only provide "yes" or "no" and avoid including any additional information.
Please do your best. Here is the question and the context:
---
CONTEXT: {context}
---
QUESTION: {question}
---
OUTPUT (yes or no):"""
is_in_prompt = PromptTemplate.from_template(is_in_conetxt)
chain = is_in_prompt | ChatUpstage() | StrOutputParser()
response = chain.invoke({"context": context, "question": question})
print(response)
return response.lower().startswith("yes")그래서 내용이 있으면 yes, 없으면 no 라고합니다!!!

그래서 위와같이 내용이 있는지 없는지를 잘 점검하여 진행해줍니다!!
뽀나스!!
그래서, 없으면 끝인가!?
이떄 Tavilyagent를 활용하여 추가검색, 결과를 제공해라고 할수 있습니다!!
아래와 같이 tavily를 활용하여 검색하게할 수 있습니다.
function_Calling
그런데 anthropic 에서는 tool use 라고한다!!!
이내용은,, 제 예전글을 참고해주세요!!^^
2024.01.24 - [데이터&AI/LLM] - GPT API 의 Function Calling 기능 알아보기!! (feat. Python)
GPT API 의 Function Calling 기능 알아보기!! (feat. Python)
GPT를 활용한 스토어도 나오고!! API 의 기술이 많이 발전했는데요!! 오늘은 Function Calling 기능에 대하여 알아보겠습니다~! Function Calling - 함수 호출!! 이 기능을 간단히 소개하자면!!! GPT를 통해 내
drfirst.tistory.com
그런데 사실, LLM이 잘하는거는!?
요약, 번역, 글쓰기
입니다!
우린 착한 llm을 너무 힘든거에 고생시킨것은 아닌가 반성을 해야합니다!

김성훈 대표님 좋은강의 감사합니다!^^
'데이터&AI > LLM' 카테고리의 다른 글
| 파이썬 langchain 활용기반, 쉽게 챗봇사이트 만들기 (gradio) (0) | 2024.05.18 |
|---|---|
| few show과 zero shot 그리고 CoT (feat. 성킴님 강의) (0) | 2024.05.18 |
| upstage의 llm 모델 Solar 사용하기!! (feat. 성킴 대표님 강의) (0) | 2024.05.16 |
| [2024.5.16]SNU x Upstage LLM 세션① : 컴공과 교수님들의 강의!! (0) | 2024.05.16 |
| 2024 Google I/O 핵심 요약: 진짜 초초초거대모델?? (0) | 2024.05.16 |




댓글