728x90
GPT한태 똑같은 질문을 여러사람이 여러번 할수 있지 않을까요??

그런데 그때마다 GPT API를 호출한다면??
매번 GPT 답변받느라 속도도 느려지고, API를 계속 호출하느라 비용도 비싸겠찌요?
이를 대비해서!!
LangChain의 caching 기능을 사용하면됩니다!!.
캐싱이란 무엇인가요?
캐싱은 이전에 계산된 결과를 저장해두고,
동일한 입력이 들어왔을 때 다시 계산하지 않고
저장된 결과를 재사용하는 기술입니다.
LangChain에서 캐싱은 LLM 호출 결과를 저장하고, 동일한 프롬프트에 대해서는 LLM을 다시 호출하지 않고 캐시된 결과를 반환합니다.
LangChain 캐싱 사용 방법
LangChain의 캐싱은 크게 2가지 방법으로 사용 가능합니다!!
방법1. 메모리캐시 사용
from langchain.cache import InMemoryCache
from langchain.llms import OpenAI
llm = OpenAI(cache=InMemoryCache())
# LLM 호출 (첫 번째 호출은 LLM API를 호출하고 결과를 캐시에 저장)
response1 = llm.predict("개구리 관한 농담하나해줘")
# LLM 호출 (두 번째 호출은 캐시된 결과를 반환)
response2 = llm.predict("개구리 관한 농담하나해줘")
print(response1 == response2) # True- 다른 두번의 질문에 같은 답변을 사용하는 지 확인하면
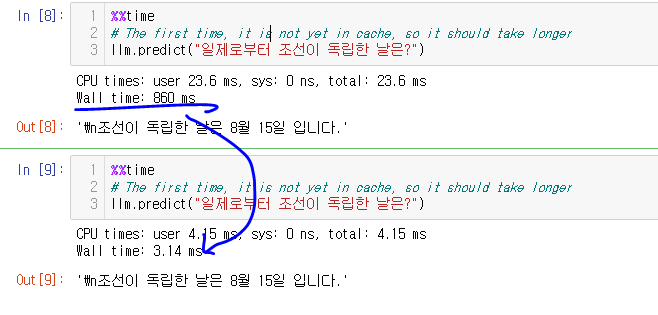
한편, 답변시간은!?
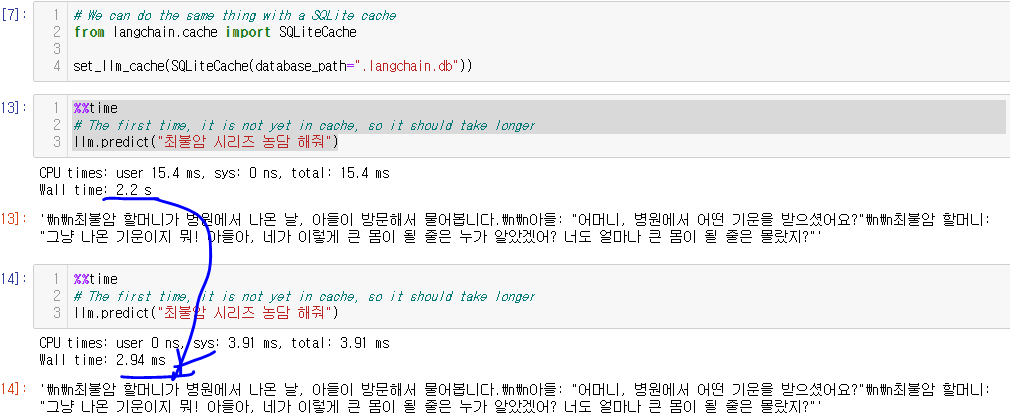
방법2. sqlite DB 사용
메모리가 불안하다면! db로 저정항 사용할수 도 있지요!~!
# We can do the same thing with a SQLite cache
from langchain.cache import SQLiteCache
set_llm_cache(SQLiteCache(database_path=".langchain.db"))위와 같이 db로 캐싱하라고 설정해주면!@
마무리
LangChain 캐싱은 LLM 애플리케이션의 성능과 비용 효율성을 크게 향상시키는 강력한 도구입니다.
캐싱을 적절하게 활용하여 LLM 애플리케이션을 더욱 효율적으로 개발하고 운영할 수 있습니다.
ㅁ 참고 : https://python.langchain.com/v0.1/docs/modules/model_io/llms/llm_caching/
728x90
'데이터&AI > LLM' 카테고리의 다른 글
| 지금시간 맞추는 GPT 만들기 (feat. function calling) (0) | 2024.05.30 |
|---|---|
| LLM 에이전트(llm agent) 란 무엇일까?- 코드로 알아보기 (feat. prompt engineering) (0) | 2024.05.29 |
| [HyperCLOVA] 익스플로러를 활용하여 데이터 생성하기 (오덕체 생성!) (1) | 2024.05.24 |
| [HyperCLOVA] 문장을 벡터로 임베딩하기 (with Python) (0) | 2024.05.23 |
| 완전쉽게!!! GPT의 Token 이해하기 (with Python) (0) | 2024.05.20 |




댓글