점수의 타입!!
chatgpt이후로!
LLM을 통한 요약, 변역에 정말 효과적이어서
많은 분들이 사용하고 있는데요~~

이때 정말 요약을 잘하는걸까? 에 대하여
어떤 모델이 더 요약을 잘할까? 를 평가하는 지표가 있어 오늘 소개하고자합니다!!
바로 ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 점수!!! 인데요!!
이 ROUGE 점수가 어떻게 계산되는지,
python 코드로 이 점수를 구하는 방법을 오늘 알아보겠습니다!!
ROUGE 점수의 타입 및 평가방법!
ROUGE 점수는 요약 성능을 평가하는 주요 지표입니다.
요약 결과 내의 텍스트가 기준 텍스트와 얼마나 일치하는지를 측정합니다.
ROUGE는 주로 n-그램(연속된 단어의 집합) 일치를 기반으로 하는 평가 지표인데,
ROUGE 점수에는 다양한 변형방식이 존제합니다!!
점수의 타입!!
1. ROUGE-N: 기준 텍스트와 생성 텍스트 간의 n-그램(예: 1-그램, 2-그램 등) 일치를 측정
ex) ROUGE -1 은 단어 하나 하나의 일치여부를 ( 단어 단위의 정확도),
ROUGE-2는 두 단어씩 묶어 평가 ( 구 또는 짧은 문장 단위의 일치도 평가)
2. ROUGE-L: 가장 긴 공통 부분 (Longest Common Subsequence, LCS)를 사용, 요약의 순서를 고려한 일치도 측정!!
>> 생성 텍스트와 기준 텍스트 간에 얼마나 비슷한 순서로 내용이 나타나는지를 평가
= 요약의 순서와 연속성을 반영
3. ROUGE-W: W가 weighted 의 약자로서!! ROUGE-L과 유사하지만, 연속적인 일치에 가중치를 부여하여 더 긴 연속 일치 구간에 더 높은 점수 부여
4.ROUGE-S: Skip-Bigram을 기반으로, 단어 간의 거리가 다소 멀어도 일치하는 경우를 인정다. 단어 사이에 다른 단어들이 있어도 일치로 간주하는 융통성을 가진 평가 방식
점수의 해석(평가방법)!!
ROUGE 점수는 Precision, Recall, F1-Score로 나누어 평가됩니다:
- Recall: 기준 텍스트에 있는 중요한 n-그램을 얼마나 많이 포함했는지 평가
- Precision: 생성된 요약 텍스트에서 기준 텍스트와 일치하는 n-그램의 비율을
- F1-Score: Precision과 Recall의 조화 평균으로, 두 점수의 균형
ROUGE의 장점과 한계
ROUGE 점수는 대량의 텍스트 평가에서 빠르게 성능을 비교할 수 있다는 점에서 매우 유용합니다. 특히, 여러 모델을 비교할 때 상대적인 성능 차이를 직관적으로 파악할 수 있습니다. 그러나 텍스트의 의미와 문맥적 유사성을 완벽히 반영하지 못한다는 한계가 있습니다. 같은 의미의 동의어를 사용한 경우에도 ROUGE 점수가 낮을 수 있고, 단순히 n-그램을 맞추는 것이 요약의 진정한 품질을 보장하지는 않기 때문에 사람의 평가와 함께 보조적으로 사용하는 것이 이상적입니다.
예시 코드: ROUGE 점수 계산하기
Python의 rouge-score 라이브러리를 사용하여 간단히 ROUGE 점수를 계산할 수 있습니다.
1. 라이브러리 설치 : pip로 간단하게 설치합닏!
pip install rouge_score
2. rouge 점수 계산하기!
> 저는 rouge1 / 2 / L 점수를 계산 해보겠습니다!
from rouge_score import rouge_scorer
# 기준 텍스트와 생성된 요약 텍스트
reference_text = """
일등박사는 대한민국 출신의 LLM, 프롬프트 엔지니어링 블로거로서 다양한 글들을 연재하고있습니다.
그의 주된 관심사는 생성형 AI모델을 자체의 기술과 그 기술을 여러 분야에 적용시켜보는것 입니다.
이 외에도 금융시장, 블록체인에 대하여 관심이 많은 블로거로서 많은글들을 사용하며 네티즌들에게 사람받고있습니다
한편으로는 블록체인에 대하여
"""
generated_summary = "일등박사는 대한민국 출신의 LLM 및 프롬프트 엔지니어링 블로거입니다"
# ROUGE 점수 계산
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference_text, generated_summary)
print(scores)
그결과!!
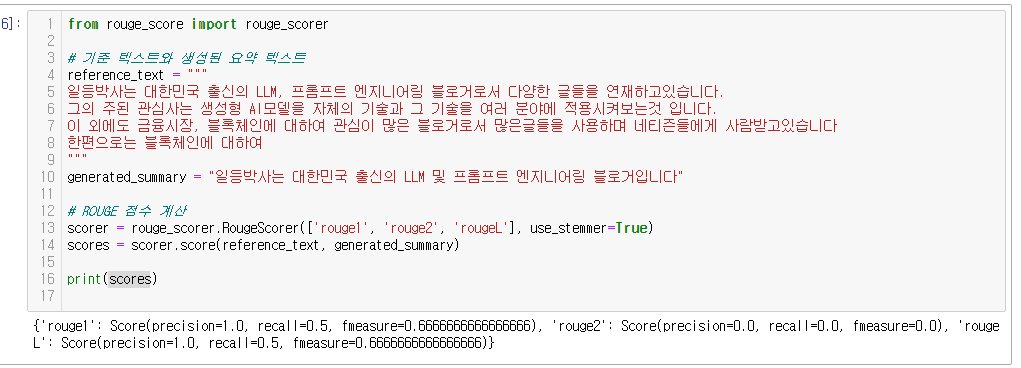
{'rouge1': Score(precision=1.0, recall=0.5, fmeasure=0.6666666666666666)
, 'rouge2': Score(precision=0.0, recall=0.0, fmeasure=0.0)
, 'rougeL': Score(precision=1.0, recall=0.5, fmeasure=0.6666666666666666)}
간단하계 rouge 의 타입별 스코어를 볼 수 있습니다.
해석해보면 단어단위 (rouge1) 및 요약의 연속성 (rougeL)에서는 괜찮은 점수 (0.6)을 받았지만,
문장단위 일치도(roung2) 에서는 낮은 점스를 받았습니다!
이번엔!
패키지가 아니라 직접 코드를 통해서 구해보겠습니다!!
1, rouge1 !!
각각의 문장을 쪼갠 뒤 precision과 recall을 구해서, 잘 가공하여 f1_score를 만듧니다!!
def rouge_1_score(reference, candidate):
# 기준(reference)과 생성된 텍스트(candidate)를 단어로 분리
ref_words = reference.split()
cand_words = candidate.split()
# 각 텍스트의 단어 집합 생성
ref_word_count = len(ref_words)
cand_word_count = len(cand_words)
# 단어 일치 수 계산
matches = sum(1 for word in cand_words if word in ref_words)
# Precision, Recall 계산
precision = matches / cand_word_count if cand_word_count > 0 else 0
recall = matches / ref_word_count if ref_word_count > 0 else 0
# F1-Score 계산
if precision + recall == 0:
f1_score = 0
else:
f1_score = 2 * (precision * recall) / (precision + recall)
return {
"ROUGE-1 Precision": precision,
"ROUGE-1 Recall": recall,
"ROUGE-1 F1-Score": f1_score
}
# ROUGE-1 점수 계산
rouge_1_result = rouge_1_score(reference_text, generated_summary)
print(rouge_1_result)
2, rouge2 !!
ngram을 만들어서 복잡한계산!! rouge1과는 많이 다르지요~!?
from collections import Counter
def get_ngrams(text, n=2):
words = text.split()
ngrams = zip(*[words[i:] for i in range(n)])
return [" ".join(ngram) for ngram in ngrams]
def rouge_2_score(reference, candidate):
# 기준(reference)과 생성된 텍스트(candidate)의 2-그램을 생성
ref_bigrams = get_ngrams(reference, n=2)
cand_bigrams = get_ngrams(candidate, n=2)
# 2-그램 카운트
ref_bigram_count = Counter(ref_bigrams)
cand_bigram_count = Counter(cand_bigrams)
# 일치하는 2-그램 수 계산
overlap = sum((cand_bigram_count & ref_bigram_count).values())
# Precision, Recall 계산
precision = overlap / sum(cand_bigram_count.values()) if sum(cand_bigram_count.values()) > 0 else 0
recall = overlap / sum(ref_bigram_count.values()) if sum(ref_bigram_count.values()) > 0 else 0
# F1-Score 계산
if precision + recall == 0:
f1_score = 0
else:
f1_score = 2 * (precision * recall) / (precision + recall)
return {
"ROUGE-2 Precision": precision,
"ROUGE-2 Recall": recall,
"ROUGE-2 F1-Score": f1_score
}
# ROUGE-2 점수 계산
rouge_2_result = rouge_2_score(reference_text, generated_summary)
print(rouge_2_result)
이처럼 직접 rouge를 계싼할 수도 있지만!! 처음 나온 패키기를 통해 계산하는게 간단하고 빠릅니다!!^^
+ 그런데!! 두개의 점수가 다른것은 왜일까요!?
- 어근(stemming) 처리: rouge_scorer.RougeScorer는 use_stemmer=True 설정을 통해 단어의 어근을 추출하여 일치 여부를 비교합니다. 예를 들어, "블로거입니다"와 "블로거"가 같은 어근으로 처리되므로 일치율이 높아질 수 있습니다. 반면 scratch로 계산한 코드에는 어근 처리 기능이 없으므로 정확히 일치하는 단어만 계산합니다.
- 토큰화 방식의 차이: rouge_score 라이브러리는 일반적으로 단어 경계, 구두점 등 텍스트 토큰화를 보다 정교하게 처리하여 ROUGE 점수를 계산합니다. 반면 scratch 구현에서는 단순히 공백으로만 단어를 분리했기 때문에, 구두점이 포함된 단어들은 다르게 인식될 수 있습니다.
- 정확한 2-그램 계산 방식의 차이: rouge_score 라이브러리에서는 2-그램 생성과 비교 과정이 더욱 정밀하게 처리될 수 있습니다. 예를 들어, 일부 라이브러리는 중복된 2-그램을 다루는 방식이 다를 수 있으며, 공백이나 구두점 처리 등에서도 차이가 발생할 수 있습니다.
- 길이 패널티: rouge_score 라이브러리는 일부 변형된 ROUGE 메트릭에 대해 길이 패널티를 적용하여 짧은 텍스트의 점수를 조정할 수도 있습니다.
따라서, scratch 구현과 rouge_score 라이브러리의 계산 결과는 어근 처리, 토큰화, 길이 패널티 등 세부적인 구현 차이로 인해 다를 수 있습니다.
일관된 점수를 원할 경우 라이브러리 사용이 권장됩니다.
'데이터&AI > LLM' 카테고리의 다른 글
| openai API의 RAG하기!! (2)-여러개 파일!!+html (tool_call 기능 중 Assistants File Search) (6) | 2024.11.08 |
|---|---|
| openai API로만 RAG하기!! (1) (tool_call 기능 중 Assistants File Search) (1) | 2024.11.07 |
| openai 의 response_format (Structured_outputs의 원조) (1) | 2024.11.06 |
| [무료] OpenAI API를 활용하여 유해성 검증하기!! (moderation API) (0) | 2024.11.05 |
| Openai 패키지에서 원하는 결과를 output으로 받기(Structured outputs) (3) | 2024.11.04 |




댓글