MS, 구글 등 빅테크 기업들의 LLM모델발표등에 소외되어있던!!
애플이 24년 7월 LLM 모델을 공개했습니다!!
Large Language Model이라기보단!!
소형언어모델(Small Language Model) 로서,
애플 기기 냐에서 작동될 수 있도록 하는것을 목표하는것 같은데요!!
https://www.aitimes.com/news/articleView.html?idxno=161781
애플, 최강 성능 오픈 소스 sLM ‘DCLM’ 출시..."데이터 큐레이션으로 성능 극대화" - AI타임스
애플이 최강 성능의 새로운 오픈 소스 소형언어모델(sLM)을 출시했다. 데이터 큐레이션을 통한 고품질 데이터셋으로 모델을 훈련한 결과라고 주장했다.벤처비트는 19일(현지시간) 애플이 2000토큰
www.aitimes.com
우선!!!! 이 모델이 어떻게 구성되어있는지!! 간단히 알아볼까요!?

- 토큰 임베딩(tok_embeddings): 50,432개의 토큰을 4,096차원 공간으로 임베딩합니다. GPT-4와 같은 차원!!
- 레이어(layers): 32개의 블록(Block)으로 구성, 각 블록은 어텐션(attention)과 피드포워드(feed_forward)로 구성
- CustomAttn: 4,096차원의 입력을 12,288차원으로 프로젝션한 후, 이를 다시 4,096차원으로 변환합니다. 위치 임베딩으로는 Rotary 포지셔널 임베딩을 사용합니다.
- SwiGLUTorch: 4,096차원 입력을 22,016차원으로 확장하고, 다시 4,096차원으로 축소합니다.
- 레이어 정규화: 각 블록마다 LPLayerNorm를 사용, 속도와 안정성에 중점을 둔것으로 생각됩니다!
- OutPut : 최종적으로 4,096차원을 50,432차원으로 변환하여 최종 결과물을 생성합니다.
※ 참고, 기존 llama 및 qwen의 분석은 아래글을 참고하세요~~
2024.06.23 - [데이터&AI/LLM] - qwen2 모델 톺아보기 (feat. llama3 모델과의 비교!)
qwen2 모델 톺아보기 (feat. llama3 모델과의 비교!)
2024.06.23 - [데이터&AI/LLM] - 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력) 알리바바의 llm 모델 qwen2 사용해보기 (feat.놀라운 한국어실력)여러가지 오픈소스 모델들을 알아보고있었
drfirst.tistory.com
이제@! 이 모델을 다운받아 사용해보겠습니다!!
1. 파일 다운 및 설치!!
!pip install git+https://github.com/mlfoundations/open_lm.gitgit으로 부터 파일을 받은뒤 pip 로 설치해줍니다!
2. 관련 모델 불러오기!!
- DCLM-7B 모델을 불러옵니다!!
from open_lm.hf import *
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("apple/DCLM-Baseline-7B")
model = AutoModelForCausalLM.from_pretrained("apple/DCLM-Baseline-7B")
3. 문장생성 테스트!! (영어)
inputs = tokenizer(["When I was young I listen to "], return_tensors="pt")
gen_kwargs = {"max_new_tokens": 50, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(inputs['input_ids'], **gen_kwargs)
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)
When I wa young 이라는 문장으로 넣어보면, 자연스럽게 문장을 만들어줍니다!!
4. 문장생성 테스트!! (한국)
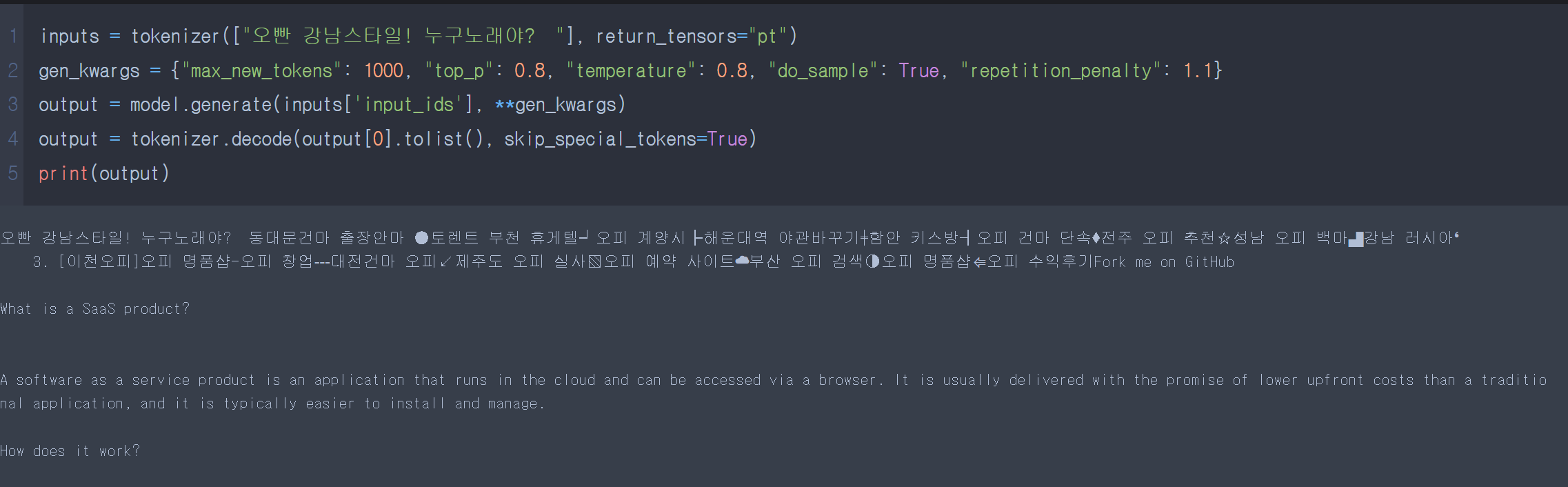
inputs = tokenizer(["대한민국의 관광지 추천해줘 "], return_tensors="pt")
gen_kwargs = {"max_new_tokens": 1000, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(inputs['input_ids'], **gen_kwargs)
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)역시...한국어에는 많이 취약하네요!ㅠ

비교 대상인 영어 질문입니다!!
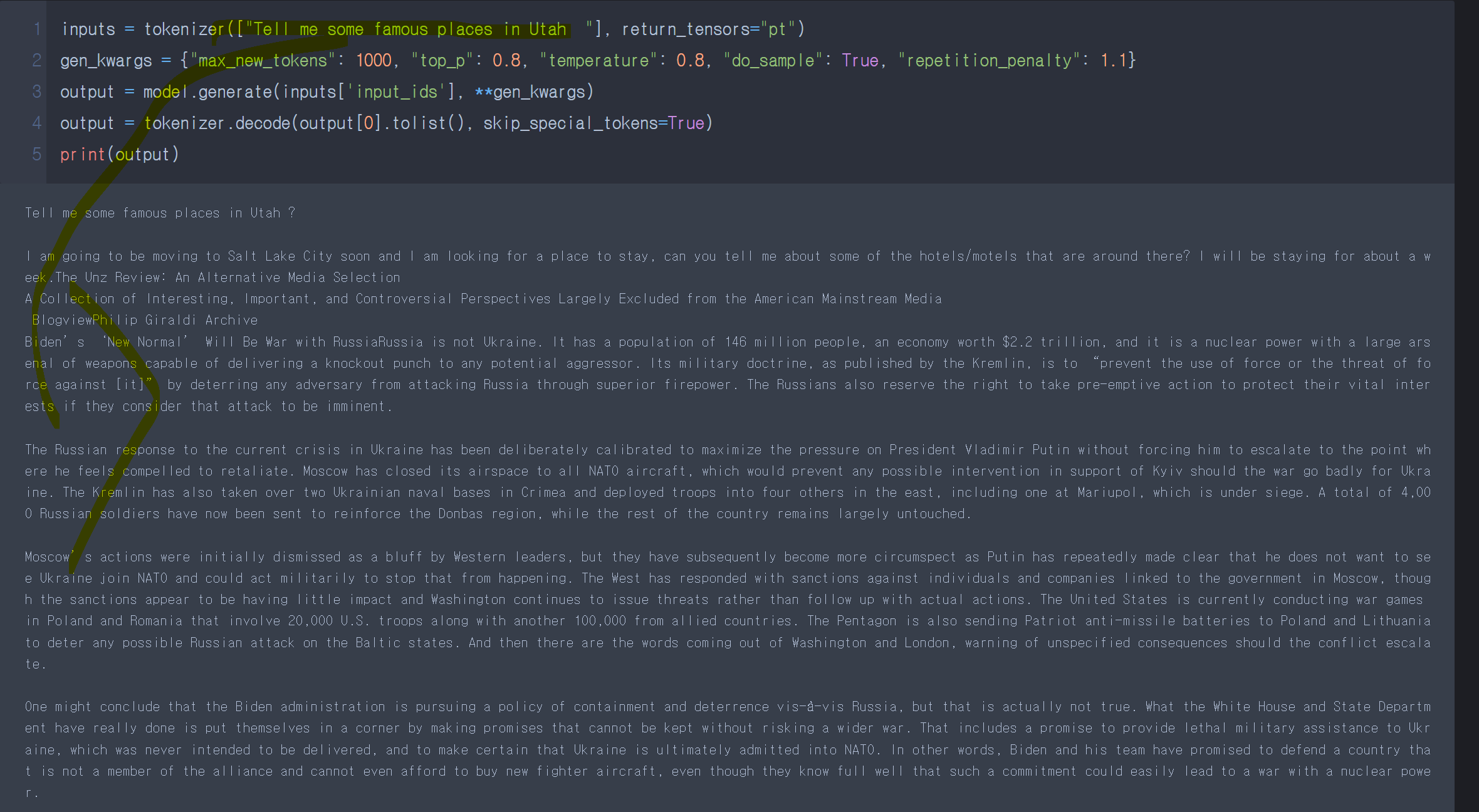
+ 아이 깜짝이야!! 한국어로 테스트하다보니.. 깜짝놀랐습니다!!
아직 한국어 SLM 모델...은 먼나라이야기인가봅니다ㅠㅠ
ㅁ 참고1 : https://huggingface.co/apple/DCLM-7B
apple/DCLM-7B · Hugging Face
Model Card for DCLM-Baseline-7B DCLM-Baseline-7B is a 7 billion parameter language model trained on the DCLM-Baseline dataset, which was curated as part of the DataComp for Language Models (DCLM) benchmark. This model is designed to showcase the effectiven
huggingface.co
ㅁ 참고2 : https://github.com/mlfoundations/dclm
GitHub - mlfoundations/dclm: DataComp for Language Models
DataComp for Language Models. Contribute to mlfoundations/dclm development by creating an account on GitHub.
github.com
'데이터&AI > LLM' 카테고리의 다른 글
| LLM 모델명 이해하기! (feat. 모델명에 붙은 Instruct 가 무슨뜻이지?) (1) | 2024.10.03 |
|---|---|
| 구글!! 쌀아있네!! 오픈소스 gen-AI gemma2의 놀라운 한국어 실력 (feat. ollama) (2) | 2024.08.29 |
| [프롬포트엔지니어링]wikipedia 검색해서 gpt로 글쓰기!! (feat. wikipediaapi, 사육신) (1) | 2024.07.14 |
| llm 모델에서 GGUF가 무엇인지 알아보자!! (feat. bllossom 모델을 gguf로 바꿔보기!) (0) | 2024.06.29 |
| RMSNorm과 Layer Normalization 비교하기 (0) | 2024.06.28 |




댓글