GPT를 사용할떄, 요금은 Token 단위로 계산이 됩니다!!
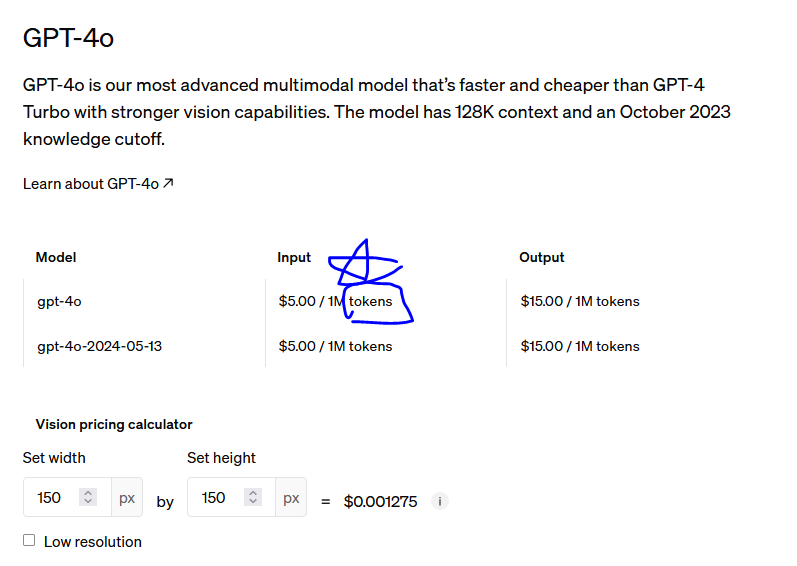
그런, 토큰이 뭘까요???
여러 글들을 찾아보면, 아래와 같이 표현합니다.
토큰이란?
GPT 모델에서의 토큰(token)은 매우 간단한 개념이다.
일상 언어에서 우리가 사용하는 단어나 문장 부호와 같은 것을 생각하면 된다.
GPT 모델에서는 이러한 단어나 문장 부호를 더 작은 단위로 쪼갠 것을 토큰이라고 부른다.
그런데, 요렇게 글로 이해하는것 보다, 파이썬 코드 하나로 이해하면 편합니다!!
한번 볼까요?
토큰 "1" 은 어떤 글자로 매칭이 될까요?
아래 코드로 확인해봅시다!
import tiktoken
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
encoding.decode([1])
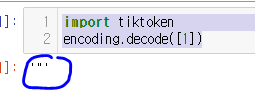
1은 바로 " 입니다!!
그럼 0,1,2,3,4 등 각각의 토큰은 어떤 글자로 매칭이 될까요?
짜잔! 아래와 같은 코드를 돌려보묜!!
import tiktoken
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
for token in range(100):
decoded_token = encoding.decode([token])
print(f"origin : {token}, Token: {decoded_token}")
위의 의미를 해석해보면!! GPT3.5 turbo에서는
!는 0 으로 " 는1로 변환하여 시작한다는것입니다!!
이번엔 반대로 알아볼까요?
한국어 가 와 나 에 대하여 보면!
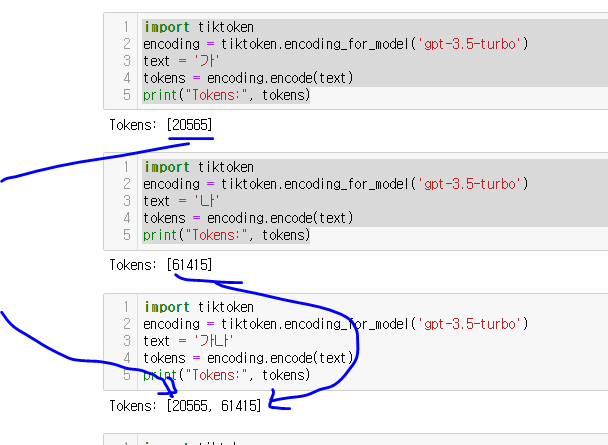
각각이 20565, 61415 토큰으로 매칭되어 연결되는것을 알수 있어요!!
그런데!! 영어는 어떨까요?
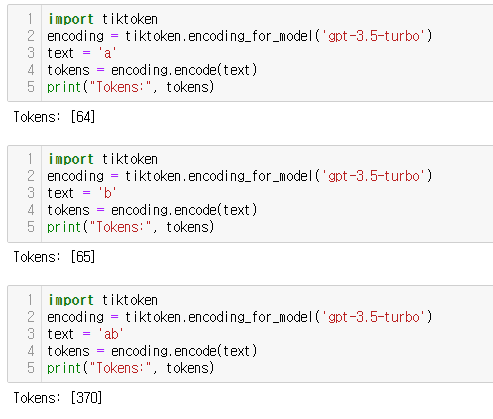
a는 64로, b는 65로 매칭되었지만, ab는 [64,65]가 아니라 370에 매칭됩니다!!
즉, 영어는 토큰 압축이 잘되지만, 한국어는 잘 안되어서 각각의 글자를 하나의 토큰으로 배정하는것인데요!,
이러한 이유료!!
네이버에서는 초기에 :LLM 출시 시에 한국어 최적화된 토큰을 배정하기에, 적은 토큰으로도 잘계산한다고
주장했었지요!!
(2023년 모델 오픈할때의 포부는 어디로갔을까요ㅠㅠ)
https://m.hankookilbo.com/News/Read/A2023082315430000817?rPrev=A2023090509040001159
"한국어 제일 잘 아는 초거대 AI로 안방서 이긴다" 네이버, 하이퍼클로바X 꺼냈다 | 한국일보
네이버는 24일 선보인 초거대 AI 거대언어모델(LLM) '하이퍼클로바X'의 강점을 이렇게 요약했다. 오픈AI의 'GPT', 구글의 '팜2', 메타의 '라마' 등 해외 빅테크가 영어에 안성맞춤인 AI 서비스로 글로벌
m.hankookilbo.com

그럼 총 몇개의 토큰이 있을까요??
import tiktoken
# 예를 들어, 'gpt-3.5-turbo' 모델을 사용한다고 가정합니다.
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
encoding.n_vocab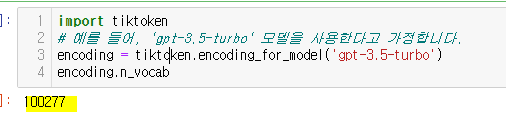
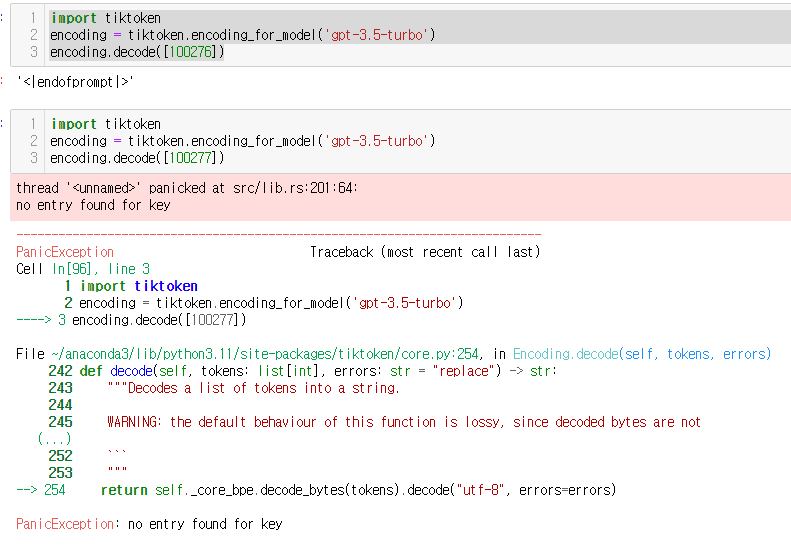
바로 100277개의 토큰으로 구성되어있는것입니다!!
이에, 100276 까지는 매칭되는 단어가 있지만!! 100277번쨰는 매칭되는 단어가 없는것입니다!!
참쉽죠!? 하지만,,
그렇지않습니다!! 글자가 1개가 아닌 리스트로 매칭되기에!!
1개의 숫자가아니라, 여러 배열로 배칭된 경우도있습니다.,
그래서,,

ㄱ,ㄴ 의 토큰을 본다면 3개로 구성되는등,, 복잡한 문제도 발생하지요~~
그래도!
이제 간단하게 토큰이 어떻게 만들어지는지 이해하셨기를 바랍니다~~
'데이터&AI > LLM' 카테고리의 다른 글
| [HyperCLOVA] 익스플로러를 활용하여 데이터 생성하기 (오덕체 생성!) (1) | 2024.05.24 |
|---|---|
| [HyperCLOVA] 문장을 벡터로 임베딩하기 (with Python) (0) | 2024.05.23 |
| 파이썬 langchain 활용기반, 쉽게 챗봇사이트 만들기 (gradio) (0) | 2024.05.18 |
| few show과 zero shot 그리고 CoT (feat. 성킴님 강의) (0) | 2024.05.18 |
| [2024.5.17] 성킴님의 LLM, langchain 강의 - SNUxUpstage LLM 세션② (3) | 2024.05.17 |




댓글